SepMamba: State-space models for speaker separation using Mamba
作者: Thor Højhus Avenstrup, Boldizsár Elek, István László Mádi, András Bence Schin, Morten Mørup, Bjørn Sand Jensen, Kenny Falkær Olsen
分类: cs.SD, cs.LG, eess.AS
发布日期: 2024-10-28
💡 一句话要点
SepMamba:利用Mamba的状态空间模型进行语音分离
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语音分离 Mamba 状态空间模型 U-Net 深度学习
📋 核心要点
- Transformer在语音分离中表现出色,但计算量巨大,限制了其应用。
- SepMamba采用U-Net架构,主要由双向Mamba层构成,旨在提高计算效率。
- 实验表明,SepMamba在WSJ0数据集上优于同等规模的Transformer模型,且计算成本更低。
📝 摘要(中文)
近年来,基于深度学习的单通道语音分离技术取得了显著进展,这主要归功于基于Transformer的注意力机制的引入。然而,这些改进是以巨大的计算需求为代价的,这使得它们无法在许多实际应用中使用。作为一种计算效率高且具有类似建模能力的替代方案,Mamba最近被提出。我们提出了SepMamba,一种主要由双向Mamba层组成的基于U-Net的架构。我们发现,在WSJ0 2-speaker数据集上,我们的方法优于类似大小的著名模型(包括基于Transformer的模型),同时显著降低了计算成本、内存使用和前向传递时间。此外,我们还报告了SepMamba因果变体的强大结果。我们的方法为深度语音分离提供了一种在计算上优于基于Transformer的架构的替代方案。
🔬 方法详解
问题定义:论文旨在解决单通道语音分离问题,即从混合语音信号中分离出多个说话者的语音。现有方法,特别是基于Transformer的模型,虽然性能优异,但计算复杂度高,内存占用大,难以在资源受限的设备上部署。
核心思路:论文的核心思路是利用Mamba状态空间模型作为Transformer的替代方案,Mamba在保持类似建模能力的同时,具有更高的计算效率和更低的内存占用。通过构建基于Mamba的U-Net架构,SepMamba旨在在语音分离任务上实现性能与效率的平衡。
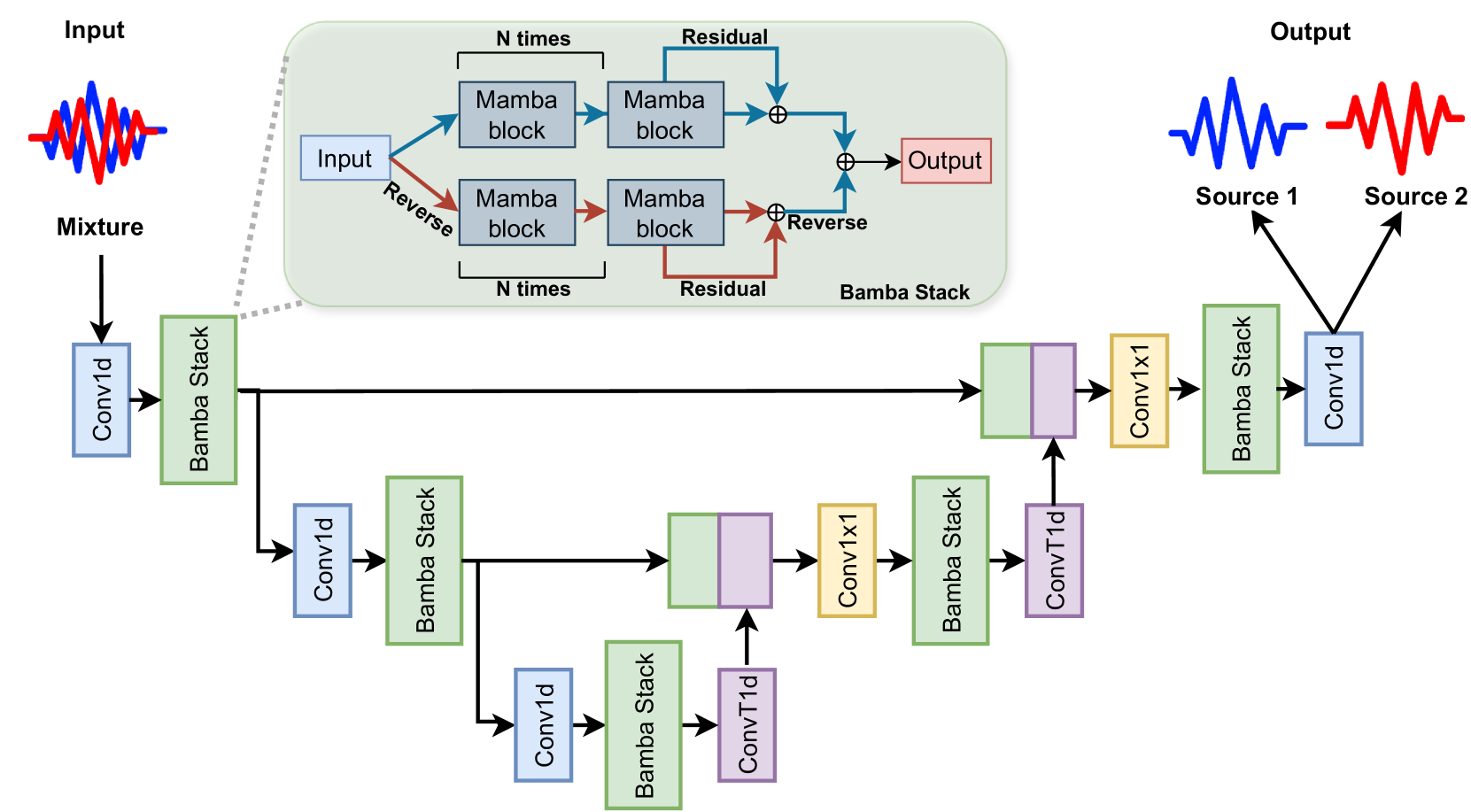
技术框架:SepMamba采用U-Net架构,包含编码器和解码器两部分。编码器负责提取输入语音信号的特征,解码器负责从特征中重建分离后的语音信号。关键在于,U-Net中的卷积层和Transformer层被替换为双向Mamba层。这种架构允许模型捕获语音信号中的长程依赖关系,同时保持计算效率。
关键创新:最重要的技术创新点是使用Mamba状态空间模型替代Transformer中的注意力机制。Mamba通过选择性扫描机制,能够自适应地关注输入序列的不同部分,从而有效地建模长程依赖关系。与Transformer相比,Mamba的计算复杂度更低,内存占用更小,更适合处理长序列数据。
关键设计:SepMamba的关键设计包括:1) 使用双向Mamba层以同时利用过去和未来的信息;2) 采用U-Net架构以实现多尺度特征融合;3) 针对因果语音分离任务,设计了SepMamba的因果变体。具体的参数设置和损失函数等技术细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
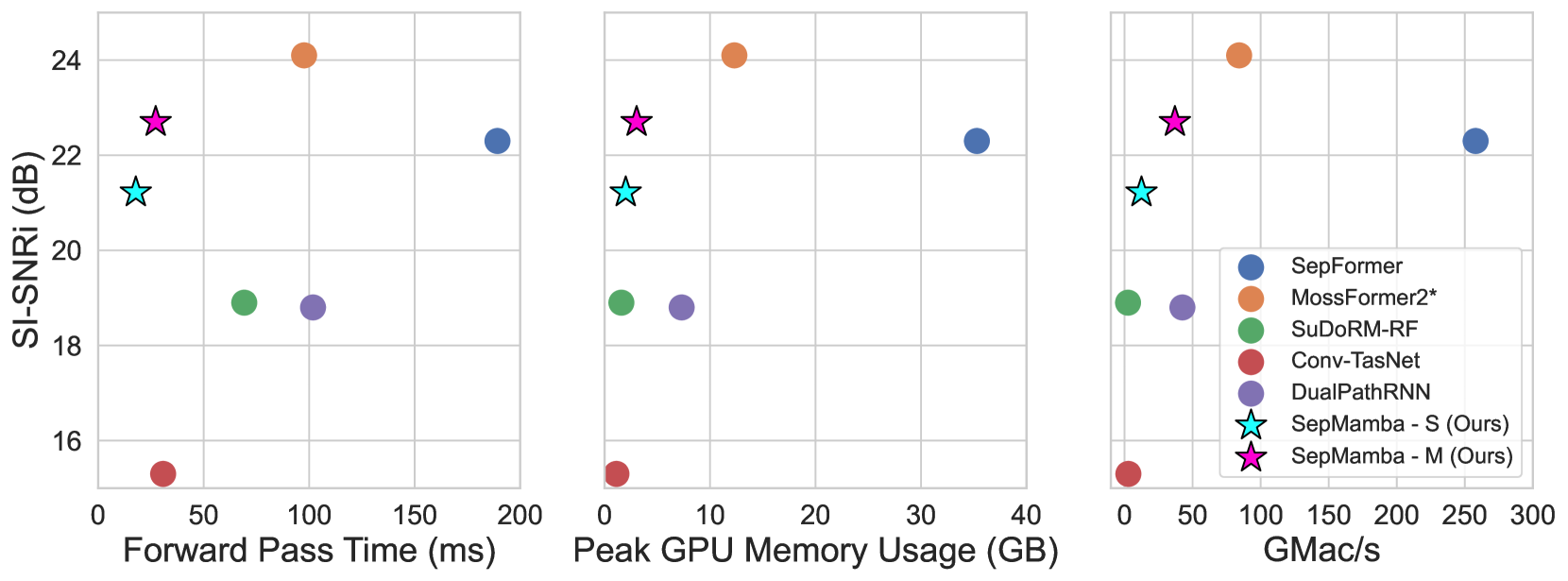
SepMamba在WSJ0 2-speaker数据集上取得了优异的性能,超越了同等规模的基于Transformer的模型。同时,SepMamba显著降低了计算成本、内存使用和前向传递时间。这些实验结果表明,SepMamba是深度语音分离中一种具有竞争力的替代方案。
🎯 应用场景
SepMamba在语音助手、语音会议、助听器等领域具有广泛的应用前景。它可以用于提高嘈杂环境下的语音识别准确率,改善语音通话质量,以及增强听力受损人士的听觉体验。未来,SepMamba有望在移动设备和嵌入式系统中实现高效的语音分离,从而推动语音交互技术的普及。
📄 摘要(原文)
Deep learning-based single-channel speaker separation has improved significantly in recent years largely due to the introduction of the transformer-based attention mechanism. However, these improvements come at the expense of intense computational demands, precluding their use in many practical applications. As a computationally efficient alternative with similar modeling capabilities, Mamba was recently introduced. We propose SepMamba, a U-Net-based architecture composed primarily of bidirectional Mamba layers. We find that our approach outperforms similarly-sized prominent models - including transformer-based models - on the WSJ0 2-speaker dataset while enjoying a significant reduction in computational cost, memory usage, and forward pass time. We additionally report strong results for causal variants of SepMamba. Our approach provides a computationally favorable alternative to transformer-based architectures for deep speech separation.