Accelerating Direct Preference Optimization with Prefix Sharing
作者: Franklin Wang, Sumanth Hegde
分类: cs.LG, cs.CL
发布日期: 2024-10-27 (更新: 2024-10-30)
备注: To appear in NeurIPS 2024 in the Fine-Tuning in Machine Learning Workshop
🔗 代码/项目: GITHUB
💡 一句话要点
提出前缀共享DPO加速方法,提升训练吞吐量且不影响收敛性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 直接偏好优化 DPO 前缀共享 注意力机制 模型微调
📋 核心要点
- 传统DPO方法在处理长提示时存在大量冗余计算,效率较低。
- 论文提出前缀共享技术,将选择和拒绝的响应合并为一个共享前缀的序列进行处理。
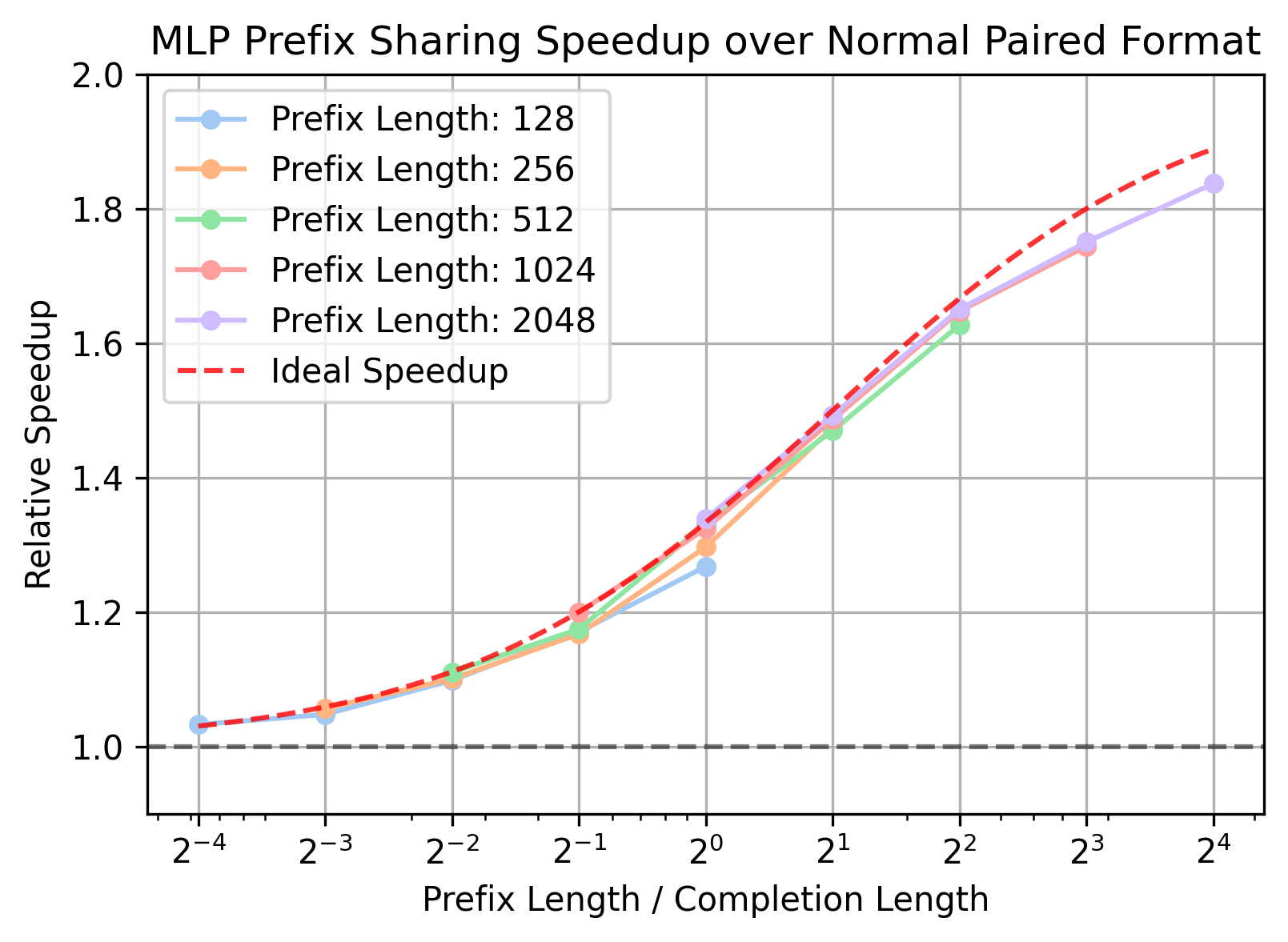
- 实验表明,该方法在DPO数据集上实现了1.1-1.5倍的训练吞吐量提升,且不影响模型收敛。
📝 摘要(中文)
离线配对偏好优化算法已成为一种流行的偏好数据微调方法,在各种任务中优于传统的监督微调。然而,传统的实现方式通常涉及冗余计算,尤其是在具有长共享提示的任务中。我们引入了偏好调整的前缀共享,这是一种将选择的和拒绝的响应作为具有共享前缀的一个序列进行处理的新技术。为了防止跨响应污染,我们使用自定义的块稀疏注意力掩码。我们的方法在流行的DPO数据集上实现了1.1-1.5倍的训练吞吐量提升,且对收敛没有任何影响。当与序列打包结合使用时,我们观察到一致的1.3-1.6倍加速,即使是序列长度较小的数据集也能受益。虽然我们专注于直接偏好优化(DPO),但我们的方法适用于其他配对偏好调整方法。通过提高计算效率,我们的工作有助于使基于偏好的微调更易于用于更广泛的应用和模型尺寸。
🔬 方法详解
问题定义:现有直接偏好优化(DPO)方法在处理具有长共享提示的任务时,存在大量的冗余计算。这是因为对于每个选择-拒绝样本对,模型都需要分别处理包含相同提示的两个序列,导致计算资源的浪费。这种冗余计算降低了训练效率,尤其是在处理大规模数据集和大型模型时,问题更加突出。
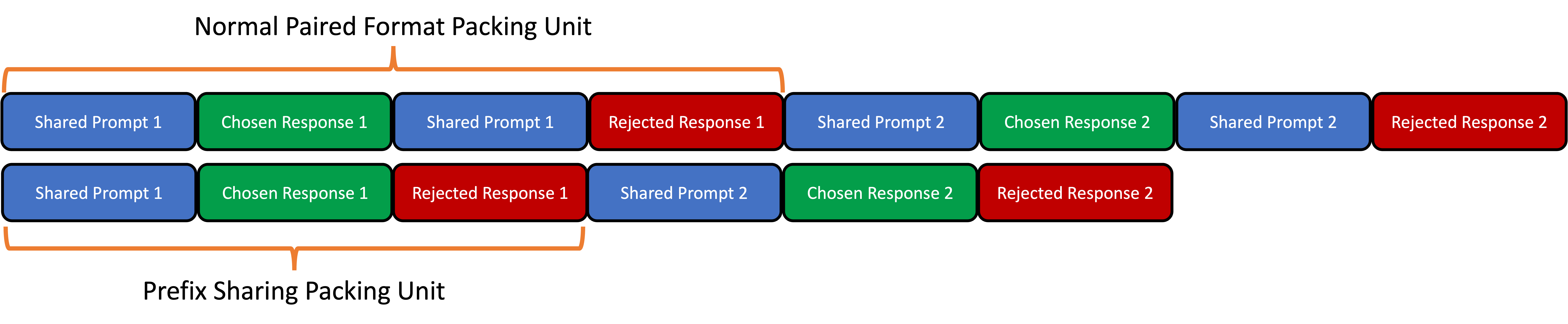
核心思路:论文的核心思路是利用选择和拒绝的响应共享相同的前缀(即提示)这一特性,将两个序列合并为一个序列进行处理。通过共享前缀,可以避免重复计算,从而提高训练效率。为了防止选择和拒绝的响应之间发生信息泄露(即cross-response contamination),需要采用特殊的注意力机制。
技术框架:该方法的核心在于将DPO训练过程中的选择和拒绝响应合并为一个序列,并使用一个定制的块稀疏注意力掩码。整体流程如下:1. 将选择的响应和拒绝的响应拼接成一个序列,共享提示部分。2. 使用一个特殊的块稀疏注意力掩码,该掩码允许提示部分的所有token之间进行attention,以及选择响应内部和拒绝响应内部的token之间进行attention,但禁止选择响应和拒绝响应之间的token进行attention。3. 使用DPO损失函数进行训练,该损失函数基于选择和拒绝响应的得分差异。
关键创新:该方法最重要的技术创新点在于提出了前缀共享的概念,并设计了相应的块稀疏注意力掩码。与传统的DPO方法相比,该方法避免了对共享提示的重复计算,从而显著提高了训练效率。块稀疏注意力掩码的设计有效地防止了选择和拒绝响应之间的信息泄露,保证了训练的有效性。
关键设计:关键设计包括:1. 块稀疏注意力掩码:该掩码是实现前缀共享的关键,它允许模型学习到选择和拒绝响应之间的差异,同时避免信息泄露。掩码的具体实现方式是,将注意力矩阵划分为多个块,只允许块内的token之间进行attention。2. 序列打包:为了进一步提高训练效率,该方法还可以与序列打包技术结合使用。序列打包可以将多个短序列打包成一个长序列,从而减少padding带来的计算开销。3. DPO损失函数:使用标准的DPO损失函数,该损失函数基于选择和拒绝响应的得分差异进行优化。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在流行的DPO数据集上实现了1.1-1.5倍的训练吞吐量提升,且对模型收敛没有任何影响。当与序列打包结合使用时,可以观察到一致的1.3-1.6倍加速,即使是序列长度较小的数据集也能受益。这些结果表明,该方法能够显著提高DPO训练的效率,且具有良好的通用性。
🎯 应用场景
该研究成果可广泛应用于各种需要基于偏好数据进行模型微调的场景,例如对话系统、文本生成、代码生成等。通过提高训练效率,该方法使得更大规模的模型和数据集的训练成为可能,从而提升模型的性能和泛化能力。此外,该方法还可以降低训练成本,使得基于偏好的微调更加普及。
📄 摘要(原文)
Offline paired preference optimization algorithms have become a popular approach for fine-tuning on preference data, outperforming traditional supervised fine-tuning in various tasks. However, traditional implementations often involve redundant computations, especially for tasks with long shared prompts. We introduce prefix sharing for preference tuning, a novel technique that processes chosen and rejected responses as one sequence with a shared prefix. To prevent cross-response contamination, we use a custom block-sparse attention mask. Our method achieves $1.1$-$1.5\times$ improvement in training throughput on popular DPO datasets, without any effect on convergence. When combined with sequence packing, we observe consistent $1.3$-$1.6\times$ speedups, benefiting even datasets with smaller sequence lengths. While we focus on Direct Preference Optimization (DPO), our approach is applicable to other paired preference tuning methods. By enhancing computational efficiency, our work contributes to making preference-based fine-tuning more accessible for a wider range of applications and model sizes. We open-source our code at https://github.com/frankxwang/dpo-prefix-sharing.