Multi-Agent Reinforcement Learning with Selective State-Space Models
作者: Jemma Daniel, Ruan de Kock, Louay Ben Nessir, Sasha Abramowitz, Omayma Mahjoub, Wiem Khlifi, Claude Formanek, Arnu Pretorius
分类: cs.LG, cs.AI, cs.MA
发布日期: 2024-10-25 (更新: 2024-10-28)
备注: 17 pages, 7 figures
💡 一句话要点
提出多智能体Mamba(MAM),在多智能体强化学习中实现与Transformer媲美的性能和更优的可扩展性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 状态空间模型 Mamba Transformer 计算效率 可扩展性 交叉注意力
📋 核心要点
- Transformer在MARL中表现出色,但计算复杂度高,限制了其在多智能体环境中的应用。
- 论文提出多智能体Mamba(MAM),利用状态空间模型(SSM)的计算效率,旨在替代Transformer。
- 实验表明,MAM在标准MARL环境中性能与MAT相当,并在大规模智能体场景中展现出更强的可扩展性。
📝 摘要(中文)
Transformer模型在多个领域取得了成功,包括多智能体强化学习(MARL),其中多智能体Transformer(MAT)已成为该领域的领先算法。然而,Transformer模型的一个显著缺点是其相对于输入大小的二次计算复杂度,这使得在扩展到更大输入时计算成本很高。这种限制限制了MAT在具有许多智能体的环境中的可扩展性。最近,状态空间模型(SSM)因其计算效率而受到关注,但它们在MARL中的应用仍未被探索。在这项工作中,我们研究了在MARL中使用Mamba(一种最新的SSM),并评估它是否可以在提供显著效率提升的同时匹配MAT的性能。我们引入了MAT的修改版本,该版本结合了标准和双向Mamba块,以及一种新颖的“交叉注意力”Mamba块。广泛的测试表明,我们的多智能体Mamba(MAM)在多个标准多智能体环境中匹配了MAT的性能,同时为更大的智能体场景提供了卓越的可扩展性。这对MARL社区意义重大,因为它表明SSM可以在不影响性能的情况下取代Transformer,同时还支持更有效地扩展到更多的智能体。
🔬 方法详解
问题定义:现有的多智能体强化学习方法,特别是基于Transformer的模型(如MAT),在处理大量智能体时面临计算复杂度过高的问题。Transformer的计算复杂度随输入规模呈二次方增长,这限制了其在复杂环境中的应用。因此,需要一种更高效的模型来处理大规模多智能体场景。
核心思路:论文的核心思路是利用状态空间模型(SSM),特别是Mamba模型,来替代Transformer。SSM具有线性计算复杂度,理论上可以显著提高计算效率,从而更好地扩展到大规模多智能体环境。通过将Mamba模型集成到MAT框架中,旨在在保持甚至提升性能的同时,降低计算成本。
技术框架:论文提出的MAM模型基于MAT框架,主要由以下几个模块组成:1) 标准Mamba块:用于处理单个智能体的状态信息。2) 双向Mamba块:用于捕捉智能体之间的双向依赖关系。3) 交叉注意力Mamba块:一种新颖的设计,用于在不同智能体之间进行信息交互。整体流程是,首先通过Mamba块处理每个智能体的状态,然后通过交叉注意力Mamba块进行智能体间的信息融合,最后输出动作策略。
关键创新:论文的关键创新在于将Mamba模型引入到多智能体强化学习中,并设计了交叉注意力Mamba块。交叉注意力Mamba块允许智能体之间进行高效的信息交互,这是传统Mamba模型所不具备的。此外,通过对MAT框架进行修改,使其能够兼容Mamba块,从而实现了性能与效率的平衡。
关键设计:论文中关键的设计包括:1) Mamba块的参数设置:具体参数值未知,但强调了需要根据具体环境进行调整。2) 交叉注意力Mamba块的设计:具体实现细节未知,但强调了其在智能体间信息融合中的作用。3) 损失函数:与MAT保持一致,具体形式未知,但目标是优化智能体的策略。
🖼️ 关键图片

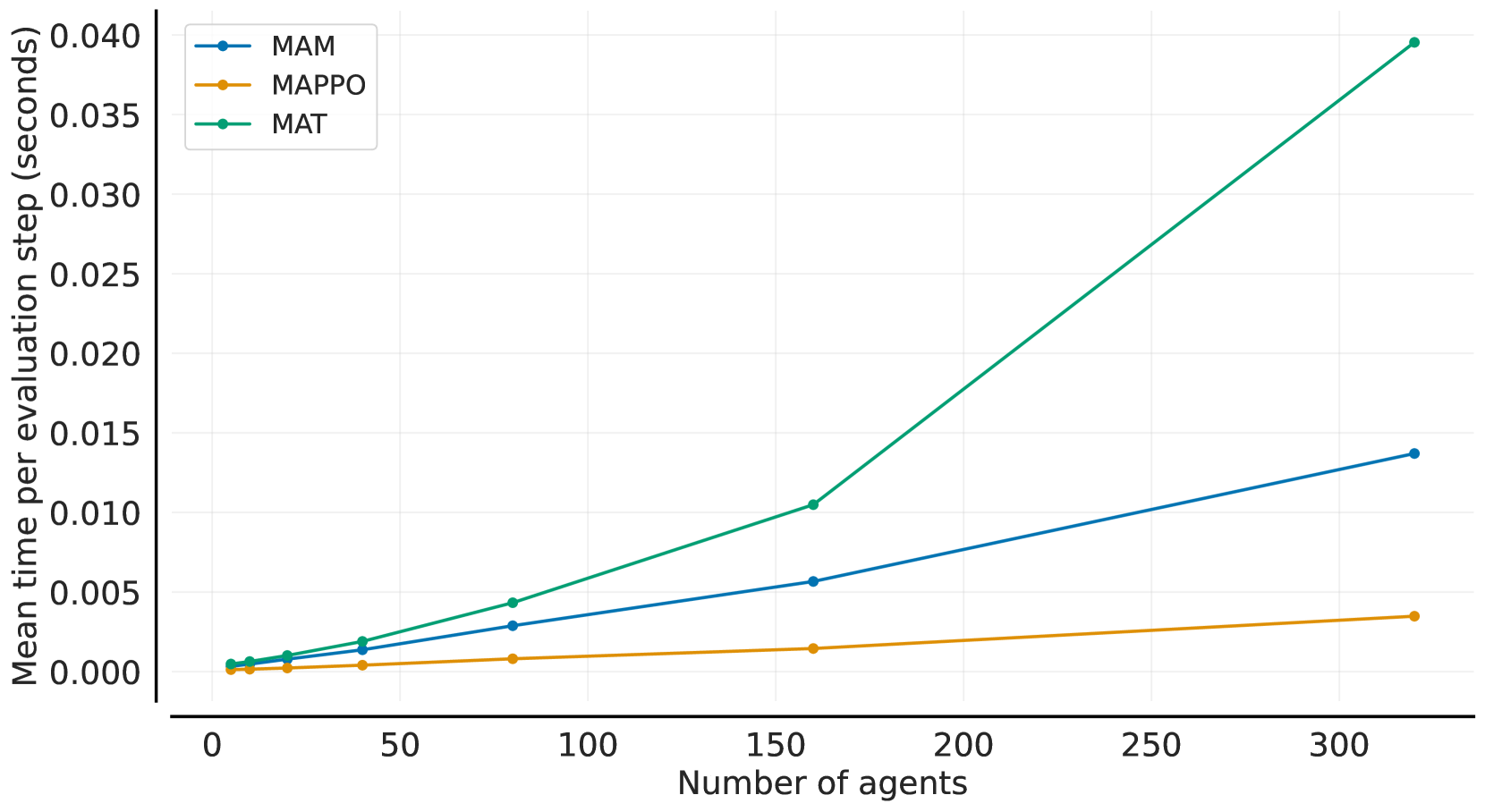

📊 实验亮点
实验结果表明,MAM模型在多个标准多智能体环境中能够匹配MAT的性能,同时在更大规模的智能体场景中展现出更强的可扩展性。具体的性能数据和提升幅度未知,但论文强调MAM在计算效率方面优于MAT,这使得其能够处理更大规模的智能体系统。
🎯 应用场景
该研究成果可应用于大规模多智能体系统,例如交通控制、机器人集群、资源分配等领域。通过提高计算效率和可扩展性,MAM模型能够处理更复杂的环境和更多的智能体,从而提升系统的整体性能和效率。未来,该研究有望推动多智能体强化学习在实际场景中的广泛应用。
📄 摘要(原文)
The Transformer model has demonstrated success across a wide range of domains, including in Multi-Agent Reinforcement Learning (MARL) where the Multi-Agent Transformer (MAT) has emerged as a leading algorithm in the field. However, a significant drawback of Transformer models is their quadratic computational complexity relative to input size, making them computationally expensive when scaling to larger inputs. This limitation restricts MAT's scalability in environments with many agents. Recently, State-Space Models (SSMs) have gained attention due to their computational efficiency, but their application in MARL remains unexplored. In this work, we investigate the use of Mamba, a recent SSM, in MARL and assess whether it can match the performance of MAT while providing significant improvements in efficiency. We introduce a modified version of MAT that incorporates standard and bi-directional Mamba blocks, as well as a novel "cross-attention" Mamba block. Extensive testing shows that our Multi-Agent Mamba (MAM) matches the performance of MAT across multiple standard multi-agent environments, while offering superior scalability to larger agent scenarios. This is significant for the MARL community, because it indicates that SSMs could replace Transformers without compromising performance, whilst also supporting more effective scaling to higher numbers of agents. Our project page is available at https://sites.google.com/view/multi-agent-mamba .