COAT: Compressing Optimizer states and Activation for Memory-Efficient FP8 Training
作者: Haocheng Xi, Han Cai, Ligeng Zhu, Yao Lu, Kurt Keutzer, Jianfei Chen, Song Han
分类: cs.LG, cs.AI
发布日期: 2024-10-25 (更新: 2025-02-12)
备注: Accepted by ICLR 2025. 22 pages. 9 Figures. 13 Tables
🔗 代码/项目: GITHUB
💡 一句话要点
COAT:通过压缩优化器状态和激活,实现内存高效的FP8训练
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: FP8训练 模型压缩 优化器状态量化 激活量化 动态范围扩展 混合粒度量化 内存优化 大规模模型训练
📋 核心要点
- 现有FP8训练框架在加速线性层计算的同时,将优化器状态和激活保留在较高精度,未能充分优化内存使用。
- COAT通过动态范围扩展对齐优化器状态分布,并采用混合粒度激活量化策略,显著降低内存占用。
- 实验表明,COAT在多种任务中实现了接近无损的性能,同时显著降低内存占用并加速训练过程。
📝 摘要(中文)
本文提出了一种名为COAT(Compressing Optimizer States and Activations for FP8 Training)的FP8训练框架,旨在显著减少大型模型训练时的内存占用。COAT通过两项关键创新解决现有方法的局限性:一是动态范围扩展,使优化器状态分布与FP8表示范围更紧密对齐,从而减少量化误差;二是混合粒度激活量化,通过结合per-tensor和per-group量化策略来优化激活内存。实验表明,与BF16相比,COAT有效地将端到端训练内存占用减少了1.54倍,并在大型语言模型预训练和微调以及视觉语言模型训练等各种任务中实现了几乎无损的性能。COAT还实现了比BF16快1.43倍的端到端训练加速,性能与TransformerEngine相当甚至超过。COAT能够在更少的GPU上高效地进行大型模型的全参数训练,并有助于在分布式训练环境中将批量大小加倍,为扩展大规模模型训练提供了一个实用的解决方案。
🔬 方法详解
问题定义:现有FP8训练方法虽然在计算层面利用了FP8的优势,但优化器状态和激活仍然使用较高精度(如BF16),导致整体内存占用仍然很高,限制了模型规模和训练效率。痛点在于无法充分利用FP8的内存优势,阻碍了大规模模型的训练。
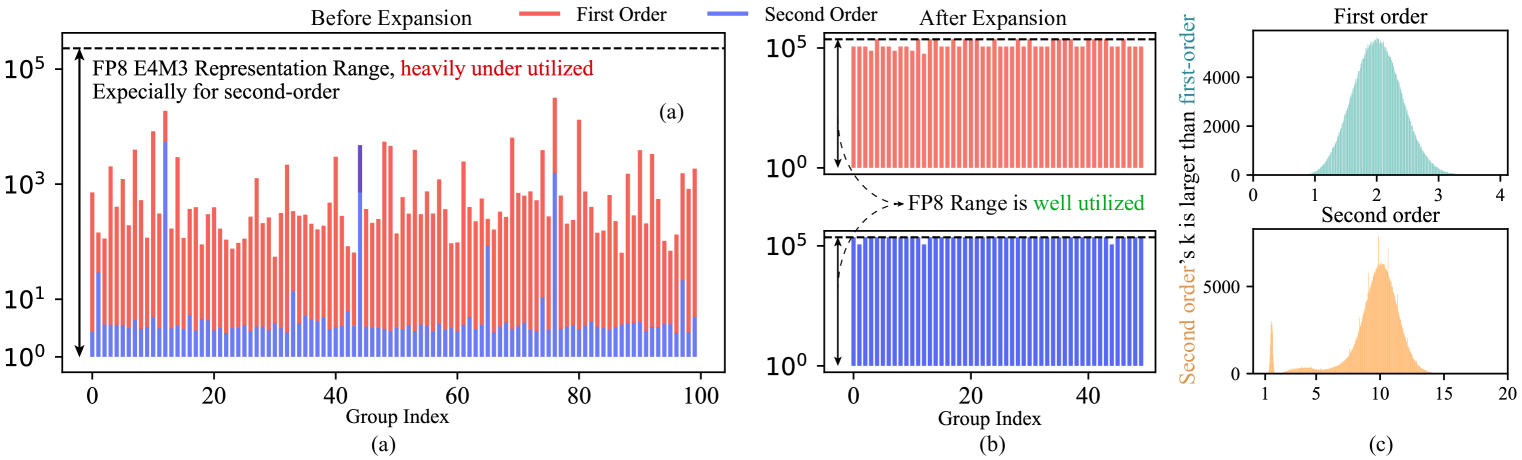
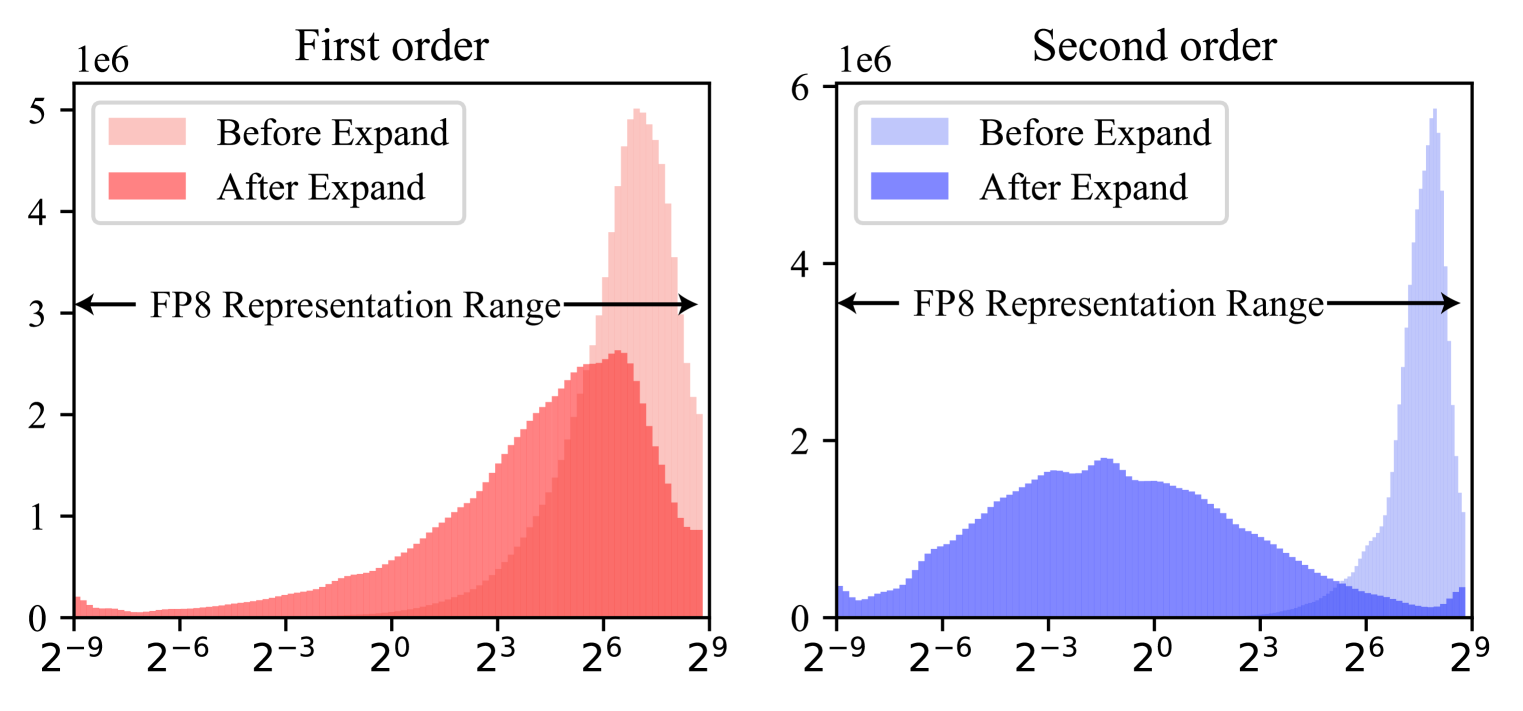
核心思路:COAT的核心思路是同时压缩优化器状态和激活,使其也采用FP8表示,从而实现端到端的内存优化。为了解决FP8表示范围有限带来的量化误差问题,COAT提出了动态范围扩展和混合粒度激活量化策略。
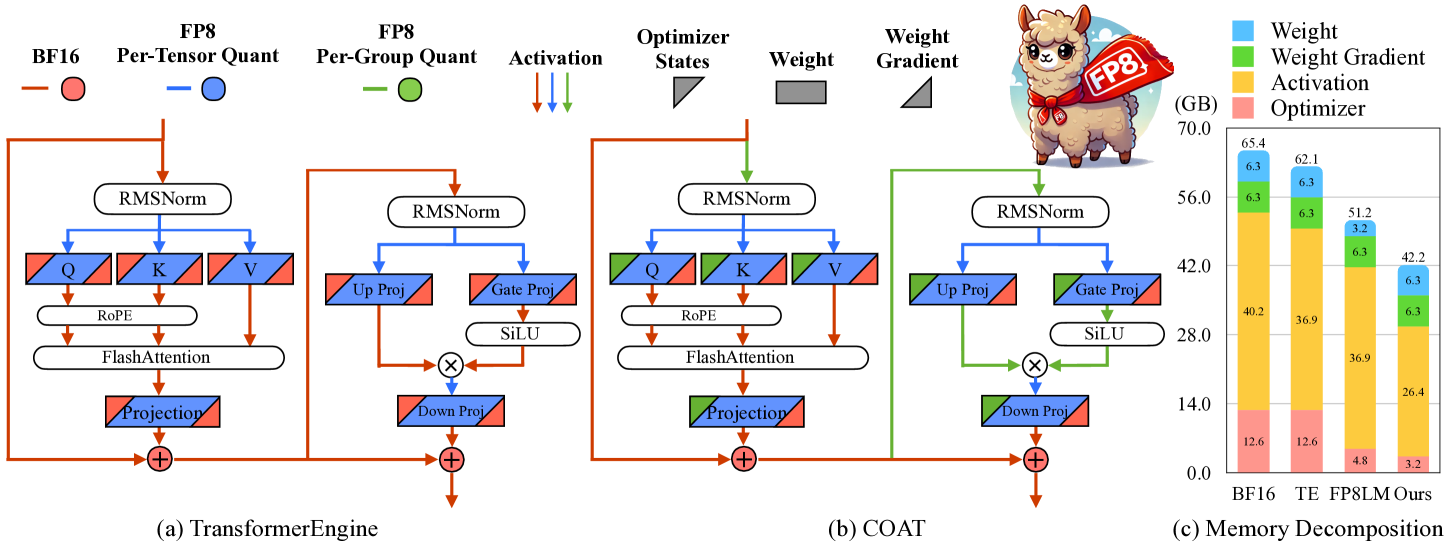
技术框架:COAT框架主要包含两个核心模块:动态范围扩展的优化器状态量化和混合粒度激活量化。首先,对优化器状态进行动态范围调整,使其分布更适合FP8表示。然后,根据激活的特性,选择per-tensor或per-group量化策略,以最小化量化误差。整个训练流程与标准的FP8训练流程类似,但在量化和反量化过程中应用了COAT的优化策略。
关键创新:COAT的关键创新在于同时压缩优化器状态和激活,并提出了动态范围扩展和混合粒度激活量化两种策略。与现有方法只关注计算层面的FP8加速不同,COAT实现了端到端的内存优化,从而能够训练更大的模型或使用更大的batch size。动态范围扩展和混合粒度量化也有效降低了量化误差,保证了模型性能。
关键设计:动态范围扩展的具体实现方式未知,可能涉及统计优化器状态的分布,并动态调整量化参数。混合粒度激活量化的关键在于如何选择合适的量化粒度,可能需要根据激活的方差或其他统计指标来决定。损失函数和网络结构与原始模型保持一致,COAT主要关注的是量化策略的优化。
🖼️ 关键图片
📊 实验亮点
COAT在多种任务上取得了显著的性能提升。与BF16相比,COAT将端到端训练内存占用减少了1.54倍,同时实现了1.43倍的端到端训练加速,性能与TransformerEngine相当甚至超过。在保证性能几乎无损的情况下,COAT显著降低了内存需求,使得更大规模的模型训练成为可能。
🎯 应用场景
COAT的潜在应用领域包括大规模语言模型预训练、微调,以及视觉语言模型的训练。通过降低内存占用,COAT使得在资源受限的硬件上训练大型模型成为可能,加速了AI模型的开发和部署。此外,COAT还可以应用于边缘计算设备,实现更高效的AI推理。
📄 摘要(原文)
FP8 training has emerged as a promising method for improving training efficiency. Existing frameworks accelerate training by applying FP8 computation to linear layers while leaving optimizer states and activations in higher precision, which fails to fully optimize memory usage. This paper introduces COAT (Compressing Optimizer States and Activations for FP8 Training), a novel FP8 training framework designed to significantly reduce memory footprint when training large models. COAT addresses current limitations through two key innovations: (1) Dynamic Range Expansion, which aligns optimizer state distributions more closely with the FP8 representation range, thereby reducing quantization error, and (2) Mixed-Granularity Activation Quantization, which optimizes activation memory using a combination of per-tensor and per-group quantization strategies. Experiments demonstrate that COAT effectively reduces end-to-end training memory footprint by 1.54x compared to BF16 while achieving nearly lossless performance across various tasks, such as Large Language Model pretraining and fine-tuning and Vision Language Model training. COAT also achieves a 1.43x end-to-end training speedup compared to BF16, performing on par with or surpassing TransformerEngine's speedup. COAT enables efficient full-parameter training of large models on fewer GPUs, and facilitates doubling the batch size in distributed training settings, providing a practical solution for scaling large-scale model training. The code is available at https://github.com/NVlabs/COAT.