Adversarial Attacks on Large Language Models Using Regularized Relaxation
作者: Samuel Jacob Chacko, Sajib Biswas, Chashi Mahiul Islam, Fatema Tabassum Liza, Xiuwen Liu
分类: cs.LG, cs.AI, cs.CL, cs.CR
发布日期: 2024-10-24
备注: 8 pages, 6 figures
💡 一句话要点
提出基于正则化松弛的对抗攻击方法,高效提升大语言模型安全性评估。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对抗攻击 大语言模型 安全性评估 正则化 连续优化 梯度攻击 对抗样本
📋 核心要点
- 现有对抗攻击方法在效率和有效性上存在局限,离散token优化效率低,连续优化无法生成有效token。
- 提出一种基于正则化梯度的连续优化方法,旨在生成有效的对抗样本,同时提升攻击效率和成功率。
- 实验表明,该方法比现有方法快两个数量级,并显著提高了对齐语言模型的攻击成功率,且能生成有效token。
📝 摘要(中文)
随着强大的大语言模型(LLMs)被广泛应用于众多实际应用,其安全性至关重要。虽然对齐技术已显著提高了整体安全性,但LLMs仍然容易受到精心设计的对抗性输入的影响。因此,对抗攻击方法被广泛用于研究和理解这些漏洞。然而,当前的攻击方法面临着重大限制。依赖于优化离散token的方法效率有限,而连续优化技术无法从模型的词汇表中生成有效的token,使其在实际应用中不切实际。在本文中,我们提出了一种新的对抗攻击技术,通过利用带有连续优化方法的正则化梯度来克服这些限制。我们的方法比最先进的基于贪婪坐标梯度的算法快两个数量级,显著提高了对齐语言模型的攻击成功率。此外,它生成有效的token,解决了现有连续优化方法的一个根本限制。我们使用四个数据集在五个最先进的LLMs上证明了我们攻击的有效性。
🔬 方法详解
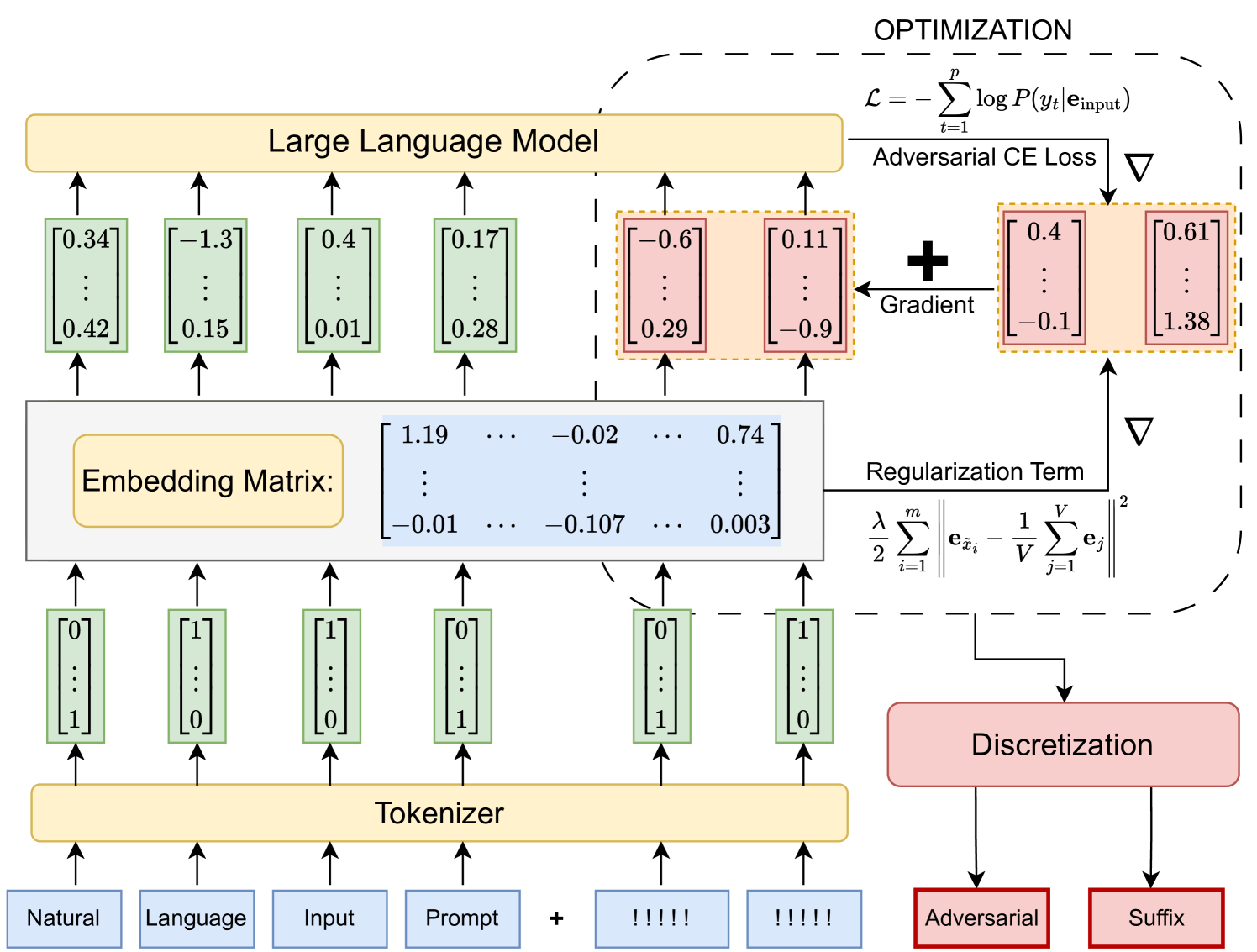
问题定义:论文旨在解决现有对抗攻击方法在大语言模型上的局限性。具体来说,现有方法要么效率低下(如基于离散token的优化),要么无法生成有效的、符合模型词汇表的对抗样本(如直接进行连续空间优化)。这些问题限制了对抗攻击在实际评估和提升大语言模型安全性方面的应用。
核心思路:论文的核心思路是结合连续优化的效率和离散token的有效性。通过在连续空间中优化对抗样本,并利用正则化技术引导优化过程,使其生成的对抗样本在离散化后仍然是有效的token。这种方法旨在克服现有方法的缺点,实现高效且有效的对抗攻击。
技术框架:该方法主要包含以下几个阶段:1) 初始化:在输入文本的基础上,初始化一个连续空间的扰动向量。2) 连续优化:使用梯度下降等优化算法,在连续空间中优化扰动向量,目标是最大化攻击目标(例如,使模型生成不期望的输出)。3) 正则化:在优化过程中,引入正则化项,鼓励扰动向量对应的token是有效的、符合模型词汇表的。4) 离散化:将连续空间的扰动向量映射回离散的token空间,生成最终的对抗样本。
关键创新:该方法最重要的创新点在于结合了连续优化和正则化技术。通过连续优化,可以高效地搜索对抗样本空间;通过正则化,可以保证生成的对抗样本是有效的,可以直接用于攻击大语言模型。这种结合克服了现有方法的局限性,实现了高效且有效的对抗攻击。
关键设计:关键的设计包括:1) 正则化项的选择:论文可能采用了某种特定的正则化项,例如L1正则化或L2正则化,以鼓励扰动向量的稀疏性或平滑性。2) 优化算法的选择:论文可能采用了某种高效的优化算法,例如Adam或SGD,以加速对抗样本的生成过程。3) 损失函数的设计:损失函数需要能够有效地衡量攻击目标,例如,可以使用交叉熵损失函数来衡量模型生成不期望输出的程度。4) 超参数的设置:正则化系数、学习率等超参数的设置对攻击效果有重要影响,需要仔细调整。
🖼️ 关键图片


📊 实验亮点
该方法在五个最先进的LLMs上进行了实验,并使用四个数据集进行了验证。实验结果表明,该方法比最先进的基于贪婪坐标梯度的算法快两个数量级,并显著提高了对齐语言模型的攻击成功率。此外,该方法能够生成有效的token,解决了现有连续优化方法的一个根本限制。
🎯 应用场景
该研究成果可应用于大语言模型的安全性评估和防御。通过对抗攻击,可以发现LLMs的潜在漏洞,并为开发更鲁棒的模型提供指导。此外,该方法还可以用于评估LLMs在各种实际应用场景中的安全性,例如,在对话系统、文本生成和信息检索等领域。
📄 摘要(原文)
As powerful Large Language Models (LLMs) are now widely used for numerous practical applications, their safety is of critical importance. While alignment techniques have significantly improved overall safety, LLMs remain vulnerable to carefully crafted adversarial inputs. Consequently, adversarial attack methods are extensively used to study and understand these vulnerabilities. However, current attack methods face significant limitations. Those relying on optimizing discrete tokens suffer from limited efficiency, while continuous optimization techniques fail to generate valid tokens from the model's vocabulary, rendering them impractical for real-world applications. In this paper, we propose a novel technique for adversarial attacks that overcomes these limitations by leveraging regularized gradients with continuous optimization methods. Our approach is two orders of magnitude faster than the state-of-the-art greedy coordinate gradient-based method, significantly improving the attack success rate on aligned language models. Moreover, it generates valid tokens, addressing a fundamental limitation of existing continuous optimization methods. We demonstrate the effectiveness of our attack on five state-of-the-art LLMs using four datasets.