Context is Key: A Benchmark for Forecasting with Essential Textual Information
作者: Andrew Robert Williams, Arjun Ashok, Étienne Marcotte, Valentina Zantedeschi, Jithendaraa Subramanian, Roland Riachi, James Requeima, Alexandre Lacoste, Irina Rish, Nicolas Chapados, Alexandre Drouin
分类: cs.LG, cs.AI, stat.ML
发布日期: 2024-10-24 (更新: 2025-06-05)
备注: ICML 2025. First two authors contributed equally
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出CiK基准,评估模型在时间序列预测中整合文本上下文信息的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列预测 多模态学习 文本上下文 LLM 基准数据集
📋 核心要点
- 现有时间序列预测方法依赖历史数值数据,缺乏对预测背景信息的有效利用,导致预测准确性受限。
- 论文提出CiK基准,将数值时间序列与文本上下文信息结合,要求模型同时理解和利用两种模态的信息进行预测。
- 实验结果表明,基于LLM的预测模型在CiK基准上表现出潜力,但仍存在不足,需要进一步研究。
📝 摘要(中文)
预测是众多领域决策制定的关键任务。虽然历史数值数据提供了一个起点,但它们未能传达可靠和准确预测的完整背景。人类预测者经常依赖额外的背景知识和约束,这些信息可以通过自然语言有效地传达。尽管基于LLM的预测器最近取得了进展,但它们有效整合文本信息的能力仍然是一个悬而未决的问题。为了解决这个问题,我们引入了“Context is Key”(CiK),这是一个时间序列预测基准,它将数值数据与各种精心设计的文本上下文配对,要求模型整合这两种模态;至关重要的是,CiK中的每个任务都需要理解文本上下文才能成功解决。我们评估了一系列方法,包括统计模型、时间序列基础模型和基于LLM的预测器,并提出了一种简单而有效的LLM提示方法,该方法在我们基准测试中优于所有其他测试方法。我们的实验强调了结合上下文信息的重要性,展示了使用基于LLM的预测模型时令人惊讶的性能,同时也揭示了它们的一些关键缺点。该基准旨在通过推广既准确又易于具有不同技术专长的决策者使用的模型来推进多模态预测。
🔬 方法详解
问题定义:论文旨在解决时间序列预测中缺乏对上下文信息有效利用的问题。现有方法主要依赖历史数值数据,忽略了影响时间序列变化的背景知识、约束条件等重要信息,导致预测精度不高,难以满足实际应用需求。现有方法的痛点在于无法有效整合数值数据和文本信息,缺乏对多模态信息的综合理解能力。
核心思路:论文的核心思路是构建一个包含数值时间序列和文本上下文信息的基准数据集(CiK),并评估现有模型在该数据集上的表现,从而推动多模态时间序列预测方法的发展。通过引入文本信息,模型可以更好地理解时间序列的变化原因和趋势,从而提高预测准确性。
技术框架:CiK基准包含多种类型的文本上下文信息,例如事件描述、约束条件、背景知识等。论文评估了多种预测方法,包括传统的统计模型、时间序列基础模型和基于LLM的预测器。同时,论文提出了一种简单的LLM提示方法,用于指导LLM更好地利用文本信息进行预测。整体流程包括数据准备、模型训练与评估、结果分析等环节。
关键创新:论文的关键创新在于构建了CiK基准,该基准首次将多种类型的文本上下文信息与数值时间序列相结合,为多模态时间序列预测研究提供了一个统一的评估平台。此外,论文提出的LLM提示方法也为LLM在时间序列预测中的应用提供了一种新的思路。
关键设计:CiK基准中的文本上下文信息经过精心设计,确保其与数值时间序列具有相关性,并且能够提供有用的预测信息。LLM提示方法的设计目标是引导LLM关注文本信息中的关键内容,并将其与数值数据相结合进行预测。具体的提示策略包括使用关键词、提供背景知识、明确预测目标等。
🖼️ 关键图片
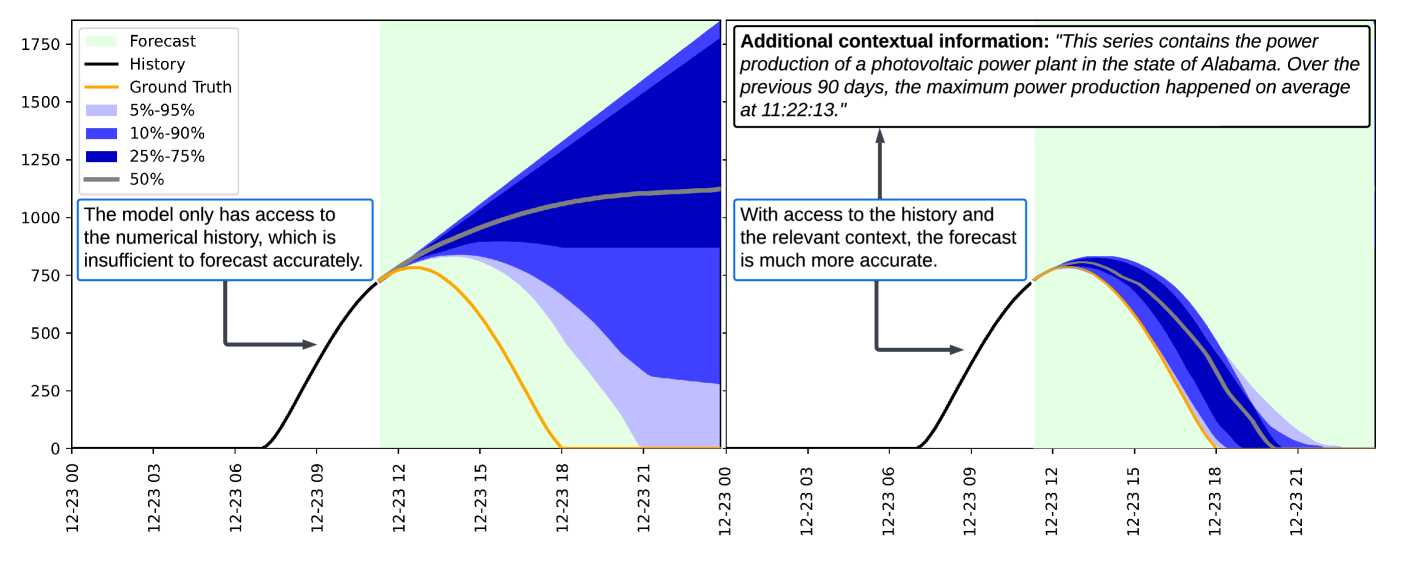
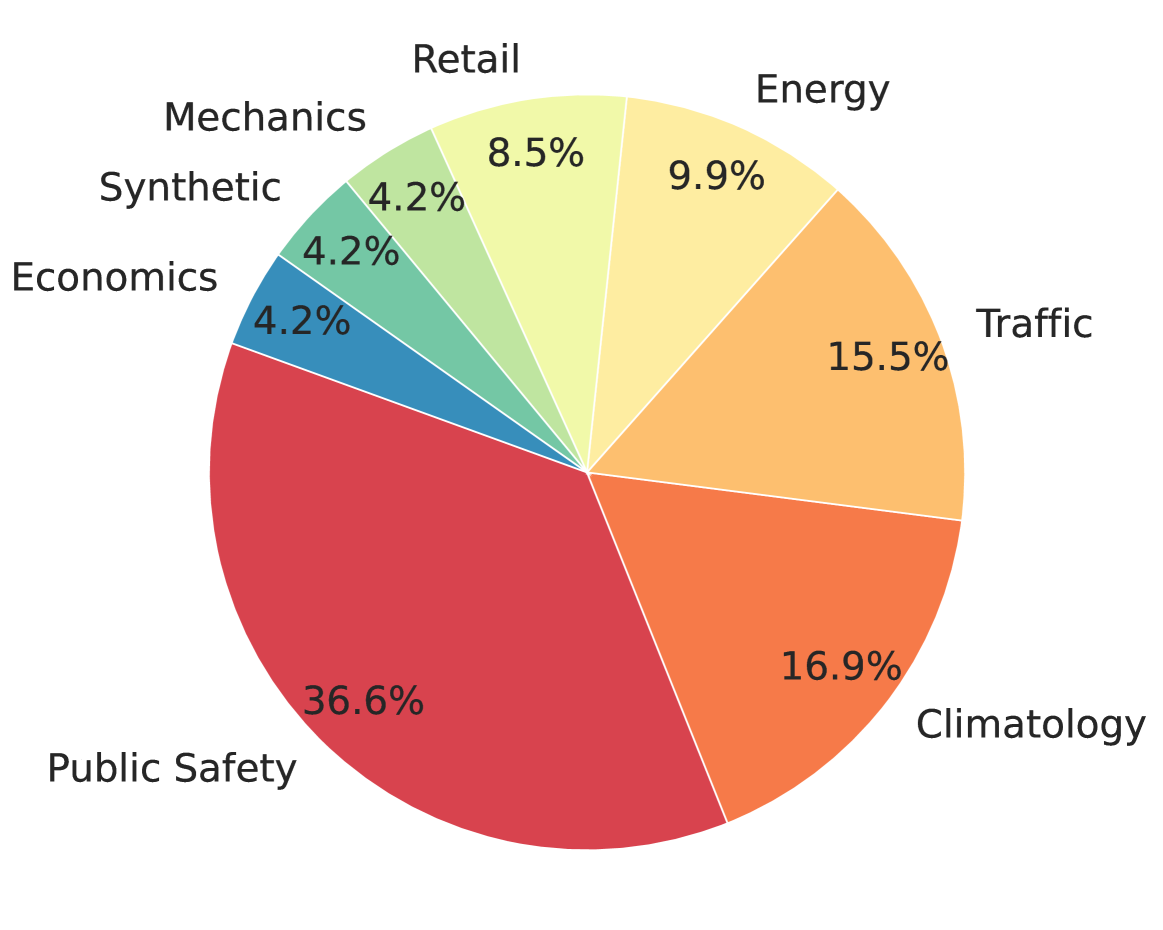
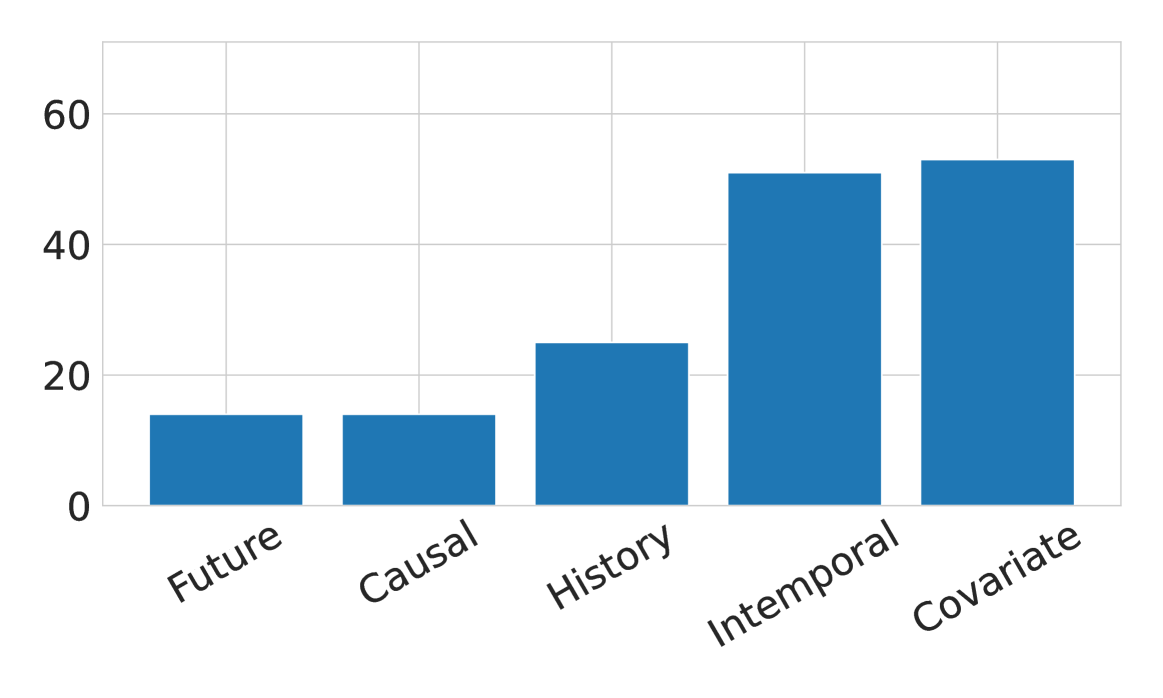
📊 实验亮点
实验结果表明,在CiK基准上,基于LLM的预测模型表现出一定的优势,但仍存在不足。论文提出的LLM提示方法优于其他测试方法,表明文本信息的有效利用可以显著提高预测准确性。例如,在某些任务上,使用LLM提示方法的模型比传统统计模型提高了10%以上的预测精度。
🎯 应用场景
该研究成果可应用于金融、供应链、能源等多个领域的时间序列预测任务。通过结合文本信息,可以提高预测的准确性和可靠性,为决策者提供更全面的信息支持。例如,在金融领域,可以利用新闻报道、市场评论等文本信息来预测股票价格;在供应链领域,可以利用天气预报、交通状况等文本信息来预测产品需求。
📄 摘要(原文)
Forecasting is a critical task in decision-making across numerous domains. While historical numerical data provide a start, they fail to convey the complete context for reliable and accurate predictions. Human forecasters frequently rely on additional information, such as background knowledge and constraints, which can efficiently be communicated through natural language. However, in spite of recent progress with LLM-based forecasters, their ability to effectively integrate this textual information remains an open question. To address this, we introduce "Context is Key" (CiK), a time-series forecasting benchmark that pairs numerical data with diverse types of carefully crafted textual context, requiring models to integrate both modalities; crucially, every task in CiK requires understanding textual context to be solved successfully. We evaluate a range of approaches, including statistical models, time series foundation models, and LLM-based forecasters, and propose a simple yet effective LLM prompting method that outperforms all other tested methods on our benchmark. Our experiments highlight the importance of incorporating contextual information, demonstrate surprising performance when using LLM-based forecasting models, and also reveal some of their critical shortcomings. This benchmark aims to advance multimodal forecasting by promoting models that are both accurate and accessible to decision-makers with varied technical expertise. The benchmark can be visualized at https://servicenow.github.io/context-is-key-forecasting/v0/.