From Efficiency to Equity: Measuring Fairness in Preference Learning
作者: Shreeyash Gowaikar, Hugo Berard, Rashid Mushkani, Shin Koseki
分类: cs.LG, cs.AI
发布日期: 2024-10-24
💡 一句话要点
提出基于经济学理论的偏好学习公平性评估框架,提升AI系统对不同用户偏好的公平表征。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 偏好学习 公平性评估 认知公平 经济学理论 基尼系数
📋 核心要点
- 现有偏好学习模型在代表不同用户偏好时可能存在偏差,导致认知不公正,缺乏有效的公平性评估方法。
- 借鉴经济学中的不平等理论,提出基于基尼系数等指标的公平性评估框架,量化偏好学习模型中的认知公平性。
- 通过在视觉偏好和笑话推荐数据集上的实验,验证了该框架的有效性,并探索了缓解不公平现象的策略。
📝 摘要(中文)
随着人工智能系统,特别是生成模型,在决策中发挥越来越大的作用,确保它们能够公平地代表不同人类的偏好变得至关重要。本文介绍了一种新颖的框架,用于评估偏好学习模型中的认知公平性,该框架的灵感来源于经济学中的不平等理论和罗尔斯正义论。我们提出了从基尼系数、阿特金森指数和库兹涅茨比率改编而来的指标,以量化这些模型中的公平性。我们使用两个数据集验证了我们的方法:一个定制的视觉偏好数据集(AI-EDI-Space)和Jester Jokes数据集。我们的分析揭示了不同用户之间模型性能的差异,突出了潜在的认知不公正现象。我们探索了预处理和过程中处理技术来缓解这些不平等,展示了模型效率和公平性之间复杂的关系。这项工作通过提供一个评估和改进偏好学习模型中认知公平性的框架,为人工智能伦理做出了贡献,为在不同人类偏好至关重要的环境中开发更具包容性的人工智能系统提供了见解。
🔬 方法详解
问题定义:论文旨在解决偏好学习模型中存在的认知公平性问题。现有方法缺乏有效的公平性评估指标,无法量化模型对不同用户偏好的表征偏差,可能导致对某些用户群体的不公正待遇。
核心思路:论文的核心思路是将经济学中的不平等理论(如基尼系数、阿特金森指数和库兹涅茨比率)应用于偏好学习模型的公平性评估。这些指标可以量化模型在不同用户之间的性能差异,从而揭示潜在的认知不公正现象。通过量化不公平性,可以更好地指导模型训练,以减少偏差。
技术框架:该框架主要包含以下几个阶段:1) 使用偏好学习模型(如生成模型)对用户偏好进行建模;2) 使用提出的公平性指标(基尼系数、阿特金森指数和库兹涅茨比率)评估模型在不同用户之间的性能差异;3) 分析评估结果,识别存在认知不公正的用户群体;4) 应用预处理或过程中处理技术(如数据增强、损失函数调整)来缓解不公平现象。
关键创新:该论文的关键创新在于将经济学中的不平等理论引入到偏好学习的公平性评估中。与传统的公平性评估方法不同,该方法能够更全面地量化模型在不同用户之间的性能差异,从而更准确地识别认知不公正现象。此外,该论文还探索了多种缓解不公平现象的策略,为开发更公平的偏好学习模型提供了指导。
关键设计:论文的关键设计包括:1) 选择合适的偏好学习模型,例如生成模型,用于对用户偏好进行建模;2) 根据具体任务选择合适的公平性指标,例如,基尼系数可以用于衡量模型性能的总体不平等程度,阿特金森指数可以用于衡量对特定用户群体的不利影响;3) 设计有效的预处理或过程中处理技术,例如,数据增强可以用于增加代表性不足的用户群体的训练数据,损失函数调整可以用于惩罚对某些用户群体的偏差。
🖼️ 关键图片
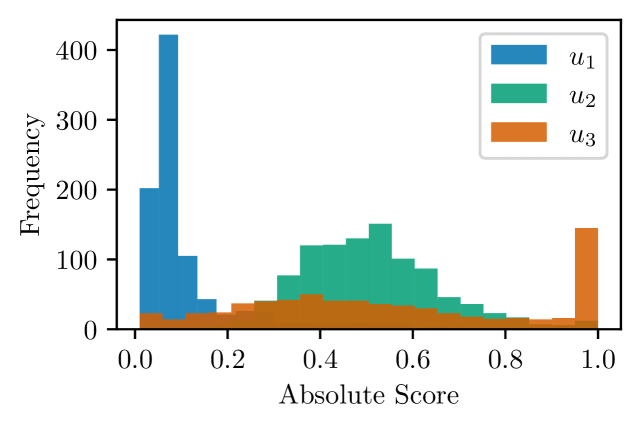

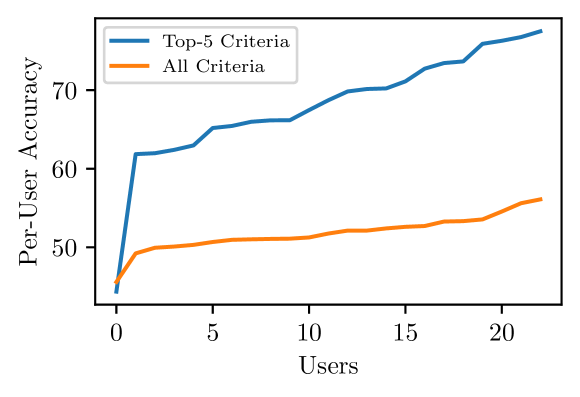
📊 实验亮点
实验结果表明,提出的公平性评估框架能够有效识别偏好学习模型中的认知不公正现象。在AI-EDI-Space和Jester Jokes数据集上,模型性能在不同用户之间存在显著差异,表明存在潜在的认知不公正。通过应用预处理和过程中处理技术,可以有效缓解这些不平等,但同时也揭示了模型效率和公平性之间存在复杂的权衡关系。
🎯 应用场景
该研究成果可应用于各种需要公平表征不同用户偏好的AI系统中,例如推荐系统、内容生成、个性化搜索等。通过评估和改进偏好学习模型的公平性,可以避免对某些用户群体的不公正待遇,提升用户满意度和信任度,促进AI技术的健康发展。
📄 摘要(原文)
As AI systems, particularly generative models, increasingly influence decision-making, ensuring that they are able to fairly represent diverse human preferences becomes crucial. This paper introduces a novel framework for evaluating epistemic fairness in preference learning models inspired by economic theories of inequality and Rawlsian justice. We propose metrics adapted from the Gini Coefficient, Atkinson Index, and Kuznets Ratio to quantify fairness in these models. We validate our approach using two datasets: a custom visual preference dataset (AI-EDI-Space) and the Jester Jokes dataset. Our analysis reveals variations in model performance across users, highlighting potential epistemic injustices. We explore pre-processing and in-processing techniques to mitigate these inequalities, demonstrating a complex relationship between model efficiency and fairness. This work contributes to AI ethics by providing a framework for evaluating and improving epistemic fairness in preference learning models, offering insights for developing more inclusive AI systems in contexts where diverse human preferences are crucial.