KVSharer: Efficient Inference via Layer-Wise Dissimilar KV Cache Sharing
作者: Yifei Yang, Zouying Cao, Qiguang Chen, Libo Qin, Dongjie Yang, Hai Zhao, Zhi Chen
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-10-24
备注: Under Review by ICLR2025
💡 一句话要点
KVSharer:通过层间差异性KV缓存共享实现高效推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 KV缓存 层间压缩 模型推理 内存优化
📋 核心要点
- 现有大语言模型推理时,KV缓存占用大量GPU内存,而现有压缩方法主要集中在单层内部,忽略了层间压缩的可能性。
- KVSharer通过在不同层之间共享KV缓存来实现层间压缩,并反直觉地发现共享差异性更大的KV缓存能更好地保持模型性能。
- 实验表明,KVSharer能有效减少KV缓存计算量,降低内存消耗,加速生成过程,并且可以与现有层内压缩方法结合使用。
📝 摘要(中文)
大型语言模型(LLMs)的发展显著增加了模型规模,导致推理过程中对GPU内存的需求巨大。KV(键-值)缓存中注意力映射的键和值存储占用了超过80%的内存消耗。目前,大多数现有的KV缓存压缩方法侧重于单个Transformer层内的层内压缩,而很少有工作考虑层间压缩。本文提出了一种名为 extit{KVSharer}的即插即用方法,该方法在层之间共享KV缓存以实现层间压缩。与直观地基于更高相似性进行共享不同,我们发现了一个违反直觉的现象:共享不同的KV缓存能更好地保持模型性能。实验表明, extit{KVSharer}可以减少30%的KV缓存计算,从而降低内存消耗,而不会显着影响模型性能,并且还可以实现至少1.3倍的生成加速。此外,我们验证了 extit{KVSharer}与现有的层内KV缓存压缩方法兼容,并且结合使用两者可以进一步节省内存。
🔬 方法详解
问题定义:现有的大型语言模型在推理时,KV缓存占据了大量的GPU内存,成为性能瓶颈。虽然已经有一些层内压缩方法,但它们忽略了Transformer层间KV缓存的冗余性,未能充分利用层间压缩的潜力。因此,如何有效利用层间信息,降低KV缓存的内存占用,同时保持模型性能,是一个亟待解决的问题。
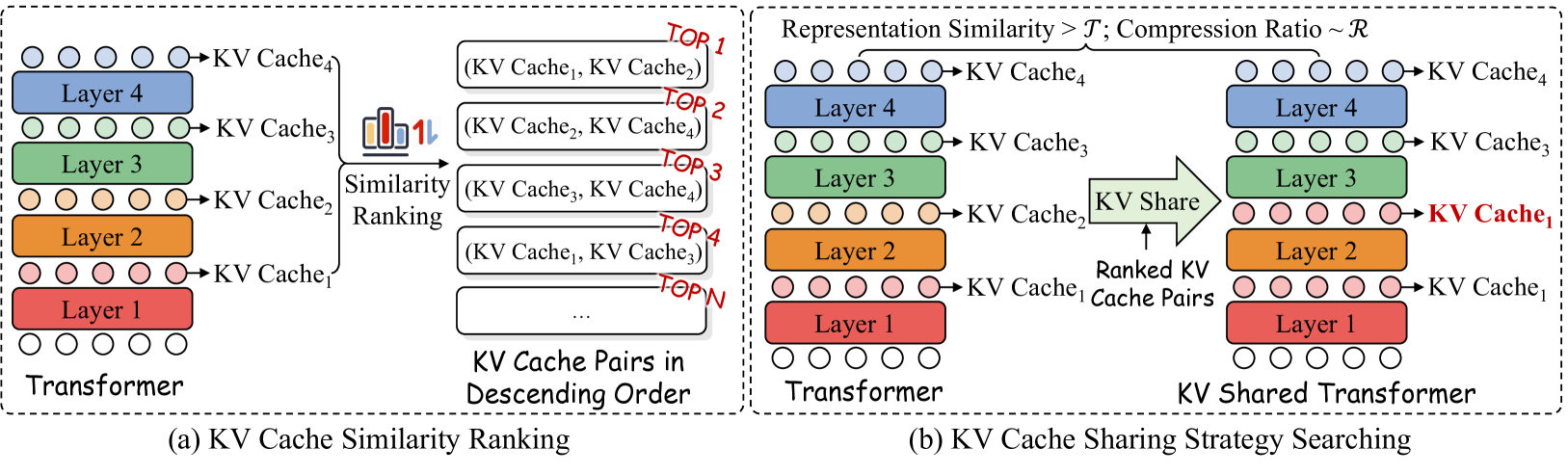
核心思路:KVSharer的核心思想是在Transformer的不同层之间共享KV缓存。作者反直觉地发现,共享差异性更大的KV缓存反而能更好地保持模型性能。这种差异性共享策略能够更好地捕捉不同层之间的互补信息,从而在压缩KV缓存的同时,避免模型性能的显著下降。
技术框架:KVSharer是一个即插即用的模块,可以方便地集成到现有的Transformer架构中。其主要流程包括:首先,选择需要共享KV缓存的层;然后,将这些层的KV缓存进行合并和压缩;最后,在推理过程中,这些层共享同一个压缩后的KV缓存。该框架可以与现有的层内KV缓存压缩方法相结合,进一步提升压缩效果。
关键创新:KVSharer最关键的创新在于其反直觉的差异性共享策略。与以往基于相似性的共享方法不同,KVSharer通过共享差异性更大的KV缓存,更好地保持了模型性能。这种策略能够更有效地利用层间互补信息,避免了信息冗余,从而在压缩KV缓存的同时,保证了模型的表达能力。
关键设计:KVSharer的关键设计包括:1) 如何选择需要共享KV缓存的层。作者可能采用了一些策略来评估层间的差异性,并选择差异性较大的层进行共享。2) 如何合并和压缩KV缓存。作者可能使用了诸如量化、剪枝等技术来压缩KV缓存,同时保证信息的完整性。3) 如何在推理过程中高效地访问共享的KV缓存。作者可能设计了一些索引结构或缓存机制,以加速KV缓存的访问速度。
🖼️ 关键图片


📊 实验亮点
实验结果表明,KVSharer可以在减少30%的KV缓存计算量的同时,不会显著影响模型性能,并且可以实现至少1.3倍的生成加速。此外,KVSharer与现有的层内KV缓存压缩方法兼容,结合使用两者可以进一步节省内存。这些结果表明,KVSharer是一种高效且实用的KV缓存压缩方法。
🎯 应用场景
KVSharer具有广泛的应用前景,尤其是在资源受限的场景下,如移动设备、边缘计算等。通过降低KV缓存的内存占用,KVSharer可以使大型语言模型在这些平台上运行成为可能。此外,KVSharer还可以应用于云端推理服务,降低推理成本,提高服务效率。未来,KVSharer有望成为大型语言模型部署和应用的关键技术之一。
📄 摘要(原文)
The development of large language models (LLMs) has significantly expanded model sizes, resulting in substantial GPU memory requirements during inference. The key and value storage of the attention map in the KV (key-value) cache accounts for more than 80\% of this memory consumption. Nowadays, most existing KV cache compression methods focus on intra-layer compression within a single Transformer layer but few works consider layer-wise compression. In this paper, we propose a plug-and-play method called \textit{KVSharer}, which shares the KV cache between layers to achieve layer-wise compression. Rather than intuitively sharing based on higher similarity, we discover a counterintuitive phenomenon: sharing dissimilar KV caches better preserves the model performance. Experiments show that \textit{KVSharer} can reduce KV cache computation by 30\%, thereby lowering memory consumption without significantly impacting model performance and it can also achieve at least 1.3 times generation acceleration. Additionally, we verify that \textit{KVSharer} is compatible with existing intra-layer KV cache compression methods, and combining both can further save memory.