Adaptive Segment-level Reward: Bridging the Gap Between Action and Reward Space in Alignment
作者: Yanshi Li, Shaopan Xiong, Gengru Chen, Xiaoyang Li, Yijia Luo, Xingyuan Bu, Yingshui Tan, Wenbo Su, Bo Zheng
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-10-23 (更新: 2025-02-25)
💡 一句话要点
提出自适应段落级别奖励,弥合对齐中动作与奖励空间差距
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 对齐 信用分配 段落级别奖励 语义分析 对抗样本 奖励模型
📋 核心要点
- 现有强化学习对齐方法依赖整体序列奖励,面临信用分配难题,难以确定哪些token应该被加强或抑制。
- 提出自适应段落级别奖励方法,利用语义信息自适应地划分段落,从而更精确地分配奖励。
- 实验结果表明,该方法能有效提升模型在对抗样本上的成功率,并在多个评估基准上取得性能提升。
📝 摘要(中文)
强化学习(RL)已被证明在使大型语言模型(LLM)与人类偏好对齐方面非常有效。典型的RL方法在整体序列奖励下进行优化,这可能导致次优的学习过程。这反映了一个关键的信用分配问题:识别哪些token应该被加强或抑制。为了纠正这些缺点,已经提出了步进式和token级别的奖励方法。然而,步进式方法依赖于标点符号分割,仍然无法准确识别关键token。token级别的方法过于细粒度,关注许多不重要的token,从而引入大量噪声。为了给不同的token分配更准确的奖励,改善信用分配,我们提出了一种“自适应段落级别奖励”方法。我们采用语义含义,而不是标点符号,来适应性地划分段落。实验表明,我们的方法可以集成到各种训练方法中。与 extit{没有}我们方法的训练方法相比,我们的方法将对抗样本的成功率提高了10%,并在MMLU、GSM8K、HumanEval等评估基准上实现了1.3%的改进。
🔬 方法详解
问题定义:现有基于强化学习的LLM对齐方法,通常使用序列级别的奖励信号,这导致了信用分配问题。难以确定哪些token的生成应该被鼓励,哪些应该被抑制。步进式方法依赖标点符号分割,不够准确;token级别方法又过于细粒度,引入过多噪声。
核心思路:核心思想是提出一种自适应的段落级别奖励机制,它不像步进式方法那样依赖于标点符号,也不像token级别方法那样过于细粒度。而是利用语义信息,将文本划分为具有语义意义的段落,并为每个段落分配奖励。
技术框架:该方法可以集成到现有的强化学习训练框架中。主要流程包括:1)使用LLM生成文本序列;2)使用语义分析方法将文本序列划分为多个段落;3)根据人类偏好或奖励模型,为每个段落计算奖励;4)使用强化学习算法,根据段落级别的奖励更新LLM的参数。
关键创新:最重要的创新点在于使用语义信息进行自适应的段落划分,而不是依赖于标点符号或固定长度的token序列。这种方法能够更准确地捕捉到文本的语义结构,从而更精确地分配奖励。与现有方法的本质区别在于奖励粒度的选择和划分依据的不同。
关键设计:关键设计包括:1)语义分析方法的选择,用于将文本划分为段落;2)段落级别奖励的计算方式,如何将人类偏好或奖励模型的输出映射到段落级别的奖励;3)强化学习算法的选择,以及如何根据段落级别的奖励更新LLM的参数。具体的参数设置、损失函数和网络结构等细节,论文中可能没有详细说明。
🖼️ 关键图片

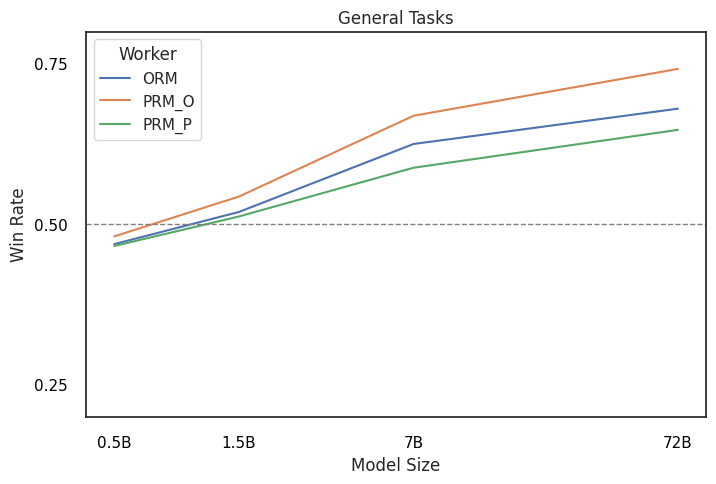

📊 实验亮点
实验结果表明,该方法在对抗样本上的成功率提高了10%,这表明该方法能够更好地应对恶意攻击,提升模型的鲁棒性。此外,在MMLU、GSM8K、HumanEval等多个评估基准上,该方法实现了1.3%的性能提升,证明了其在通用任务上的有效性。这些结果表明,自适应段落级别奖励是一种有效的LLM对齐方法。
🎯 应用场景
该研究成果可应用于提升大型语言模型与人类偏好对齐的各种场景,例如对话系统、文本生成、内容创作等。通过更精确的信用分配,可以训练出更符合人类价值观和需求的LLM,减少有害或不当内容的生成,提高用户体验。未来可进一步探索更有效的语义分析方法和奖励计算方式,以提升对齐效果。
📄 摘要(原文)
Reinforcement Learning (RL) has proven highly effective in aligning Large Language Models (LLMs) with human preferences. Typical RL methods optimize under an overall sequence reward, which can lead to a suboptimal learning process. This reflects a key credit assignment problem: identifying which tokens to reinforce or suppress. To rectify these shortcomings, step-wise and token-wise methods have been proposed. However, step-wise methods rely on punctuation segmentation and still cannot accurately identify the key tokens. The token-level approach is too fine-grained, attending to many unimportant tokens and thus introducing a large amount of noise. To assign more accurate rewards to different tokens, improving credit assignment, we propose the "Adaptive Segment-wise Reward" method. We employ semantic meaning, rather than punctuation, to adaptively delineate segments. Experiments demonstrate that our method can be integrated into various training methods. Compared to training methods \textit{without} our approach, our method improves the success rate on adversarial samples by 10\%, and achieves a 1.3\% improvement on evaluation benchmarks such as MMLU, GSM8K, HumanEval, etc.