UnStar: Unlearning with Self-Taught Anti-Sample Reasoning for LLMs
作者: Yash Sinha, Murari Mandal, Mohan Kankanhalli
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-10-22
💡 一句话要点
UnStar:利用自学习反样本推理实现LLM的知识遗忘
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识遗忘 反样本学习 大型语言模型 隐私保护 模型修复
📋 核心要点
- 现有LLM知识遗忘方法缺乏对特定知识的精准删除能力,容易影响模型性能。
- UnSTAR通过引入反样本概念,利用误导性理由生成反样本,逆转已学习的关联。
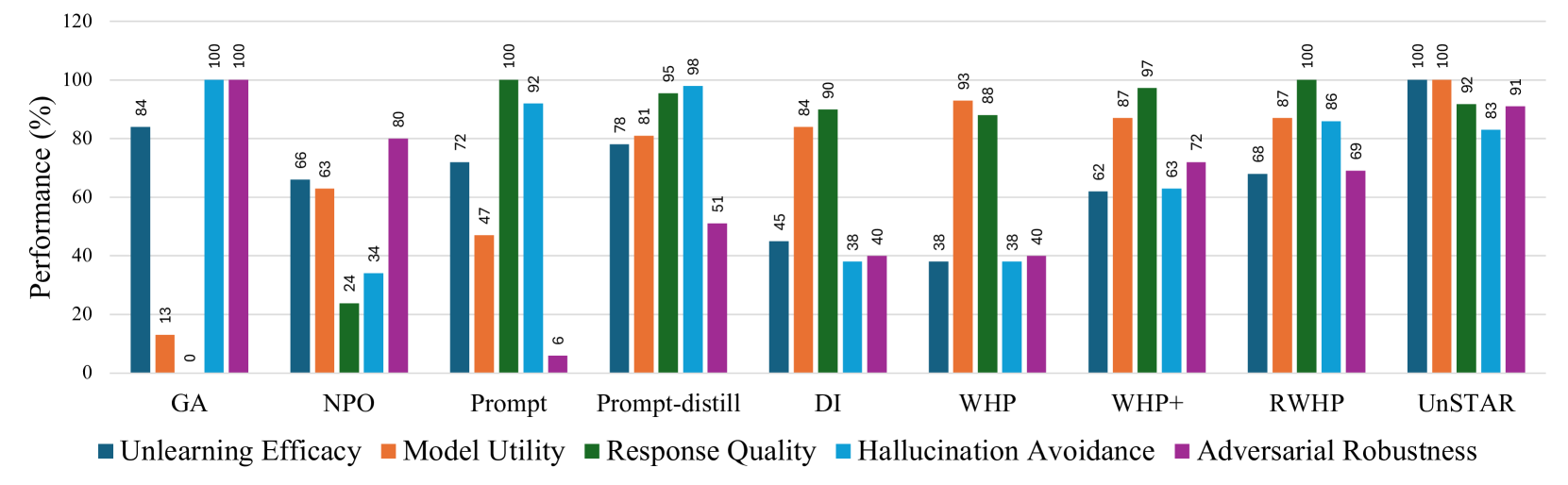
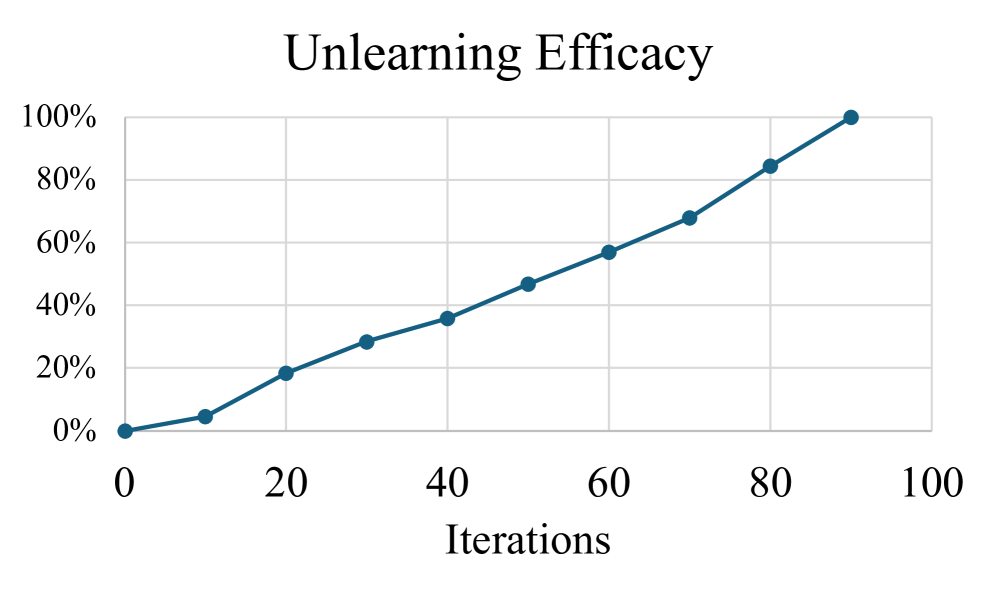
- 实验表明,UnSTAR能够高效、有针对性地遗忘LLM中的特定知识,且不影响相关知识。
📝 摘要(中文)
机器学习的关键组成部分是用于训练的数据样本、用于学习模式的模型以及用于优化准确性的损失函数。类似地,知识遗忘可以通过反数据样本(或反样本)、遗忘方法和反向损失函数来实现。虽然之前的研究已经探索了遗忘方法和反向损失函数,但反样本的潜力在很大程度上尚未开发。在本文中,我们介绍了UnSTAR:利用大型语言模型(LLM)的自学习反样本推理进行知识遗忘。我们的贡献有三方面:首先,我们提出了反样本诱导遗忘的新概念;其次,我们通过利用误导性理由来生成反样本,这有助于逆转已学习的关联并加速遗忘过程;第三,我们实现了细粒度的目标遗忘,允许选择性地删除特定的关联,而不会影响相关的知识——这是以前的工作无法实现的。结果表明,反样本为LLM提供了一种高效、有针对性的遗忘策略,为保护隐私的机器学习和模型修改开辟了新途径。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)知识遗忘方法,例如微调或正则化,通常难以实现细粒度的知识删除,容易对模型性能产生负面影响。它们无法精确地移除特定的关联,并且可能会影响到相关的知识,导致模型遗忘不应该遗忘的内容。因此,如何实现高效、有针对性的LLM知识遗忘,同时保持模型性能,是一个重要的研究问题。
核心思路:UnSTAR的核心思路是利用“反样本”来诱导模型遗忘。反样本是指与目标知识相反或矛盾的样本,通过训练模型识别并“学习”这些反样本,从而逆转模型中已存在的关于目标知识的关联。这种方法类似于“以毒攻毒”,通过引入与目标知识相悖的信息,来抵消模型中原有的知识。
技术框架:UnSTAR的技术框架主要包含以下几个阶段:1) 反样本生成:利用误导性理由(misleading rationales)来生成反样本。这些理由旨在引导模型产生与目标知识相反的推理结果。2) 反样本训练:使用生成的反样本对LLM进行微调,目标是让模型学习到反样本所蕴含的“错误”知识。3) 知识遗忘评估:评估模型在目标知识上的遗忘程度,以及在相关知识上的保留程度。
关键创新:UnSTAR最重要的技术创新点在于提出了“反样本诱导遗忘”的概念,并设计了一种基于误导性理由的反样本生成方法。与传统的知识遗忘方法相比,UnSTAR能够更精确地定位和删除特定的知识关联,同时减少对模型整体性能的影响。此外,UnSTAR还实现了细粒度的目标遗忘,允许选择性地删除特定的关联,而不会影响相关的知识。
关键设计:在反样本生成阶段,UnSTAR利用了误导性理由来引导模型生成与目标知识相反的推理结果。例如,如果要遗忘“巴黎是法国的首都”这一知识,可以生成一个反样本,其中包含一个误导性理由,例如“巴黎位于意大利北部”,从而引导模型认为巴黎不是法国的首都。在反样本训练阶段,可以使用标准的交叉熵损失函数来优化模型,目标是最小化模型在反样本上的预测误差。
🖼️ 关键图片

📊 实验亮点
实验结果表明,UnSTAR能够有效地遗忘LLM中的特定知识,同时保持模型在相关知识上的性能。与现有的知识遗忘方法相比,UnSTAR在遗忘效率和知识保留方面都取得了显著的提升。例如,在某个特定任务上,UnSTAR能够将模型对目标知识的准确率降低到接近于0,同时仅对相关知识的准确率造成微小的影响。
🎯 应用场景
UnSTAR在多个领域具有广泛的应用前景,包括:1) 隐私保护:可以用于删除LLM中包含的敏感信息,保护用户隐私。2) 模型修复:可以用于修复LLM中存在的错误或偏见。3) 模型定制:可以用于根据特定需求修改LLM的知识库。未来,UnSTAR有望成为一种通用的LLM知识遗忘工具,促进LLM在各个领域的应用。
📄 摘要(原文)
The key components of machine learning are data samples for training, model for learning patterns, and loss function for optimizing accuracy. Analogously, unlearning can potentially be achieved through anti-data samples (or anti-samples), unlearning method, and reversed loss function. While prior research has explored unlearning methods and reversed loss functions, the potential of anti-samples remains largely untapped. In this paper, we introduce UnSTAR: Unlearning with Self-Taught Anti-Sample Reasoning for large language models (LLMs). Our contributions are threefold; first, we propose a novel concept of anti-sample-induced unlearning; second, we generate anti-samples by leveraging misleading rationales, which help reverse learned associations and accelerate the unlearning process; and third, we enable fine-grained targeted unlearning, allowing for the selective removal of specific associations without impacting related knowledge - something not achievable by previous works. Results demonstrate that anti-samples offer an efficient, targeted unlearning strategy for LLMs, opening new avenues for privacy-preserving machine learning and model modification.