CartesianMoE: Boosting Knowledge Sharing among Experts via Cartesian Product Routing in Mixture-of-Experts
作者: Zhenpeng Su, Xing Wu, Zijia Lin, Yizhe Xiong, Minxuan Lv, Guangyuan Ma, Hui Chen, Songlin Hu, Guiguang Ding
分类: cs.LG, cs.CL
发布日期: 2024-10-21 (更新: 2025-02-18)
备注: NAACL2025 Main
💡 一句话要点
提出 CartesianMoE,通过笛卡尔积路由增强MoE模型中专家间的知识共享。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 知识共享 笛卡尔积 大型语言模型 路由算法
📋 核心要点
- MoE模型面临专家间知识共享难题,性能受路由精度影响。
- CartesianMoE借鉴矩阵分解思想,以“乘法”方式促进知识共享。
- 实验表明,CartesianMoE在困惑度和下游任务上优于现有MoE模型,并提升了路由鲁棒性。
📝 摘要(中文)
大型语言模型(LLM)因其在各种下游任务中的卓越性能而备受关注。根据著名的缩放定律,扩大密集LLM的规模可以增强其能力,但也会显著增加计算复杂度。混合专家(MoE)模型通过允许模型规模增长而不大幅增加训练或推理成本来解决这个问题。然而,MoE模型面临着专家之间知识共享的挑战,这使得它们的性能在某种程度上对路由准确性敏感。为了解决这个问题,以前的工作引入了共享专家,并以“加法”方式将它们的输出与top K路由专家的输出结合起来。在本文中,受到集体矩阵分解学习数据间共享知识的启发,我们提出了CartesianMoE,它以更像“乘法”的方式实现专家之间更有效的知识共享。大量的实验结果表明,在困惑度和下游任务性能方面,CartesianMoE优于以往用于构建LLM的MoE模型。并且我们还发现CartesianMoE实现了更好的专家路由鲁棒性。
🔬 方法详解
问题定义:MoE模型中专家之间的知识共享不足,导致模型性能对路由的准确性非常敏感。现有的方法,如共享专家,通过加法的方式融合专家输出,知识共享效率较低。
核心思路:受到集体矩阵分解的启发,CartesianMoE采用“乘法”的方式来融合不同专家的输出,从而更有效地实现专家之间的知识共享。这种方式允许模型学习专家之间的复杂关系,并利用这些关系来提升整体性能。
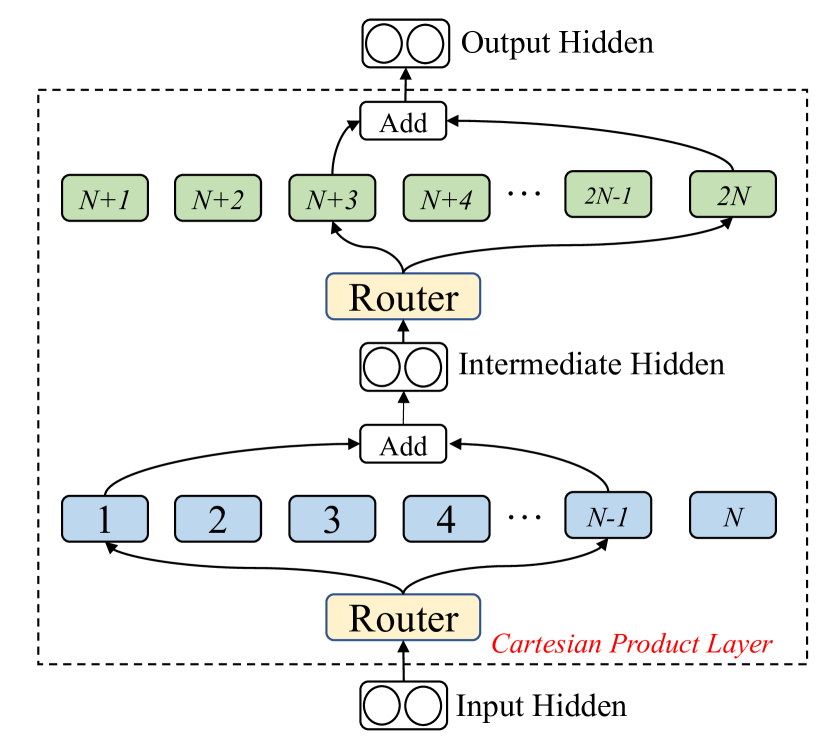
技术框架:CartesianMoE的核心在于使用笛卡尔积来组合不同专家的输出。具体来说,对于每个输入,模型首先选择top-K个专家。然后,CartesianMoE计算这些专家输出的笛卡尔积,并将结果输入到后续层。这种笛卡尔积操作可以有效地捕捉专家之间的交互信息。
关键创新:CartesianMoE的关键创新在于使用笛卡尔积进行专家输出的融合,这与以往的加法融合方式有本质区别。笛卡尔积能够捕捉专家之间的非线性关系,从而实现更有效的知识共享。
关键设计:CartesianMoE的关键设计包括:1)选择合适的top-K专家数量;2)设计有效的笛卡尔积计算方法,以避免计算复杂度过高;3)使用适当的正则化技术,以防止过拟合。
🖼️ 关键图片


📊 实验亮点
实验结果表明,CartesianMoE在困惑度和下游任务性能方面均优于现有的MoE模型。具体来说,CartesianMoE在多个基准数据集上取得了显著的性能提升,并且表现出更好的专家路由鲁棒性,这意味着即使路由出现一定程度的误差,模型仍然能够保持较高的性能。
🎯 应用场景
CartesianMoE可应用于各种需要大规模语言模型的场景,例如机器翻译、文本生成、对话系统等。通过提升MoE模型的性能和鲁棒性,CartesianMoE可以帮助构建更强大、更可靠的AI系统,从而在自然语言处理领域发挥重要作用。
📄 摘要(原文)
Large language models (LLM) have been attracting much attention from the community recently, due to their remarkable performance in all kinds of downstream tasks. According to the well-known scaling law, scaling up a dense LLM enhances its capabilities, but also significantly increases the computational complexity. Mixture-of-Experts (MoE) models address that by allowing the model size to grow without substantially raising training or inference costs. Yet MoE models face challenges regarding knowledge sharing among experts, making their performance somehow sensitive to routing accuracy. To tackle that, previous works introduced shared experts and combined their outputs with those of the top $K$ routed experts in an
addition'' manner. In this paper, inspired by collective matrix factorization to learn shared knowledge among data, we propose CartesianMoE, which implements more effective knowledge sharing among experts in more like amultiplication'' manner. Extensive experimental results indicate that CartesianMoE outperforms previous MoE models for building LLMs, in terms of both perplexity and downstream task performance. And we also find that CartesianMoE achieves better expert routing robustness.