Understanding Forgetting in LLM Supervised Fine-Tuning and Preference Learning -- A Convex Optimization Perspective
作者: Heshan Fernando, Han Shen, Parikshit Ram, Yi Zhou, Horst Samulowitz, Nathalie Baracaldo, Tianyi Chen
分类: cs.LG, cs.AI, cs.CL, math.OC, stat.ML
发布日期: 2024-10-20 (更新: 2025-11-10)
🔗 代码/项目: GITHUB
💡 一句话要点
提出联合后训练框架XRIGHT,解决LLM监督微调和偏好学习中的遗忘问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 大型语言模型 监督微调 偏好学习 后训练 遗忘问题
📋 核心要点
- 现有LLM后训练方法采用SFT和RLHF/DPO的顺序执行,导致模型在后续阶段遗忘先前学习的知识,影响整体性能。
- 论文提出联合后训练框架XRIGHT,旨在同时优化SFT和偏好学习目标,从而避免顺序训练中的遗忘问题。
- 实验结果表明,XRIGHT在多个LLM评估基准测试中优于顺序后训练,性能提升高达23%,且计算开销很小。
📝 摘要(中文)
大型语言模型(LLM)的后训练,通常包括监督微调(SFT)阶段和偏好学习阶段(RLHF或DPO),对于有效和安全的LLM应用至关重要。目前流行的开源LLM后训练方法是依次执行SFT和RLHF/DPO。然而,这种方法在SFT和RLHF/DPO的权衡方面并非最优:LLM在经历第二阶段的训练时,会逐渐忘记第一阶段的训练内容。这种顺序范式之所以存在,主要是因为它简单且模块化,易于大规模实施和管理,尽管存在局限性。我们从理论上证明了顺序后训练的次优性,并提出了一个实用的联合后训练框架,该框架具有理论收敛保证,并且在多个LLM评估基准测试中,其经验表现优于顺序后训练框架,总体性能提升高达23%,同时计算开销极小。我们的代码可在https://github.com/heshandevaka/XRIGHT 获取。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在后训练阶段,特别是监督微调(SFT)和偏好学习(如RLHF/DPO)的顺序执行过程中出现的“遗忘”问题。现有方法先进行SFT,再进行RLHF/DPO,导致模型在学习偏好的同时,逐渐忘记了SFT阶段学习到的知识,从而影响最终性能。这种顺序训练方式的痛点在于SFT和偏好学习的目标存在冲突,无法同时优化。
核心思路:论文的核心思路是提出一种联合后训练框架,将SFT和偏好学习的目标函数结合起来,同时进行优化。通过这种方式,模型可以在学习偏好的同时,保留SFT阶段学习到的知识,从而避免遗忘问题。联合训练的关键在于如何平衡SFT和偏好学习的目标,避免模型过度拟合其中一个目标。
技术框架:论文提出的联合后训练框架XRIGHT,其整体架构包含两个主要部分:SFT模块和偏好学习模块。这两个模块共享底层LLM的参数,并通过一个联合损失函数进行优化。具体流程如下:首先,使用SFT数据对LLM进行微调;然后,使用偏好数据(例如,人类反馈数据)对LLM进行偏好学习;最后,通过联合损失函数同时优化SFT和偏好学习的目标。
关键创新:论文最重要的技术创新点在于提出了一个具有理论收敛保证的联合后训练框架。与现有的顺序训练方法相比,XRIGHT能够同时优化SFT和偏好学习的目标,从而避免遗忘问题。此外,XRIGHT的计算开销很小,易于大规模实施。XRIGHT本质区别在于其优化方式,从分离的顺序优化转变为联合优化。
关键设计:XRIGHT的关键设计在于联合损失函数的设计。该损失函数需要平衡SFT和偏好学习的目标,避免模型过度拟合其中一个目标。具体来说,论文采用了一种加权损失函数,其中SFT损失和偏好学习损失分别乘以不同的权重。这些权重的选择至关重要,需要根据具体任务和数据集进行调整。此外,论文还考虑了正则化项,以防止模型过拟合。
🖼️ 关键图片
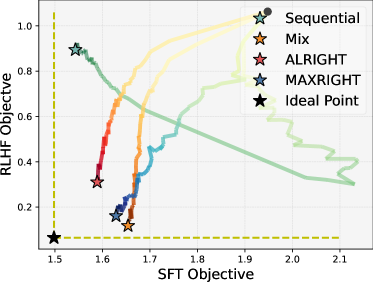
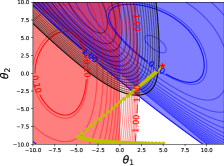
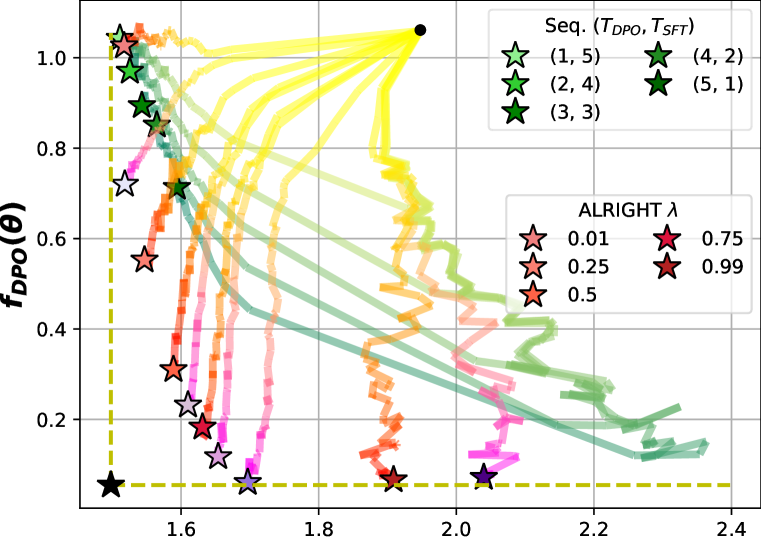
📊 实验亮点
实验结果表明,XRIGHT在多个LLM评估基准测试中优于顺序后训练框架,总体性能提升高达23%。具体来说,XRIGHT在常识推理、文本生成和代码生成等任务上均取得了显著的提升。此外,XRIGHT的计算开销极小,易于大规模实施,使其具有很强的实用价值。
🎯 应用场景
该研究成果可广泛应用于各种需要对LLM进行后训练的场景,例如对话系统、文本生成、代码生成等。通过使用XRIGHT框架,可以显著提高LLM的性能和安全性,使其更好地满足实际应用的需求。该研究对于提升LLM在实际应用中的效果具有重要价值,并为未来的LLM后训练研究提供了新的思路。
📄 摘要(原文)
The post-training of LLMs, which typically consists of the supervised fine-tuning (SFT) stage and the preference learning stage (RLHF or DPO), is crucial to effective and safe LLM applications. The widely adopted approach in post-training popular open-source LLMs is to sequentially perform SFT and RLHF/DPO. However, this is suboptimal in terms of SFT and RLHF/DPO trade-off: the LLM gradually forgets about the first stage's training when undergoing the second stage's training. This sequential paradigm persists largely due to its simplicity and modularity, which make it easier to implement and manage at scale despite its limitations. We theoretically prove the sub-optimality of sequential post-training and propose a practical joint post-training framework which has theoretical convergence guarantees and empirically outperforms sequential post-training framework, with up to 23% overall performance improvement across multiple LLM evaluation benchmarks, while having minimal computational overhead. Our code is available at https://github.com/heshandevaka/XRIGHT.