Deep Learning Foundation and Pattern Models: Challenges in Hydrological Time Series
作者: Junyang He, Ying-Jung Chen, Alireza Jafari, Anushka Idamekorala, Geoffrey Fox
分类: cs.LG
发布日期: 2024-10-19 (更新: 2025-09-18)
💡 一句话要点
针对水文时间序列,研究深度学习基础模型和模式模型的挑战与优化。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 水文时间序列 深度学习 外生信息 基础模型 LSTM CAMELS数据集 径流预测
📋 核心要点
- 现有时间序列分析的深度学习方法,特别是基础模型,在科学应用方面考虑不足,忽略了水文等领域数据的复杂性。
- 通过分析水文时间序列数据,研究整合外生信息对模型性能的影响,并比较多种深度学习模型,以提升数据表示能力。
- 实验结果表明,整合外生信息可显著降低均方误差,尤其年度周期性外生时间序列贡献最大,且包含全面数据的模型优于基础模型。
📝 摘要(中文)
本文旨在通过研究水文数据,识别时间序列中的关键特征,尤其关注深度学习方法和基础模型在时间序列分析中的应用。该研究通过强调关键应用特征来推进计算机科学发展,并通过识别有效捕获这些特征的建模方法,为水文学和其他科学领域做出贡献。科学时间序列数据本质上是复杂的,涉及来自多个位置的观测数据,每个位置都有各种随时间变化的数据流和外生因素,这些因素可能是静态的或随时间变化的,并且依赖于应用或纯粹是数学的。本研究分析了来自CAMELS和Caravan全球数据集的水文时间序列,这些数据集包含流域的降雨和径流数据,具有多达六个观测流和大约8,000个位置的209个静态参数。通过八种不同的模型配置评估外生数据对关键水文任务的影响。结果表明,整合外生信息可以增强数据表示,在最大的数据集中将均方误差降低高达40%。此外,我们还详细比较了20多个最先进的模式和基础模型的性能。该分析是完全开源的,由Google Colab上的Jupyter Notebook提供支持,用于基于LSTM的建模、数据预处理和模型比较。使用替代深度学习架构的初步研究结果表明,包含全面观测数据和外生数据的模型优于更有限的方法,包括基础模型。值得注意的是,自然的年度周期性外生时间序列贡献了最显著的改进,尽管静态和其他周期性因素也很有价值。
🔬 方法详解
问题定义:论文旨在解决水文时间序列建模中,如何有效利用外生信息以提升模型预测精度的问题。现有方法在处理此类数据时,往往忽略了外生因素的影响,或者未能充分利用这些信息,导致模型性能受限。此外,现有基础模型在水文领域的适用性也需要进一步评估。
核心思路:论文的核心思路是通过整合全面的观测数据和外生信息,增强模型对水文时间序列的表示能力。特别强调了自然年度周期性外生时间序列的重要性,并探索了静态和其他周期性因素的价值。通过比较多种深度学习模型,找到最适合水文时间序列建模的方法。
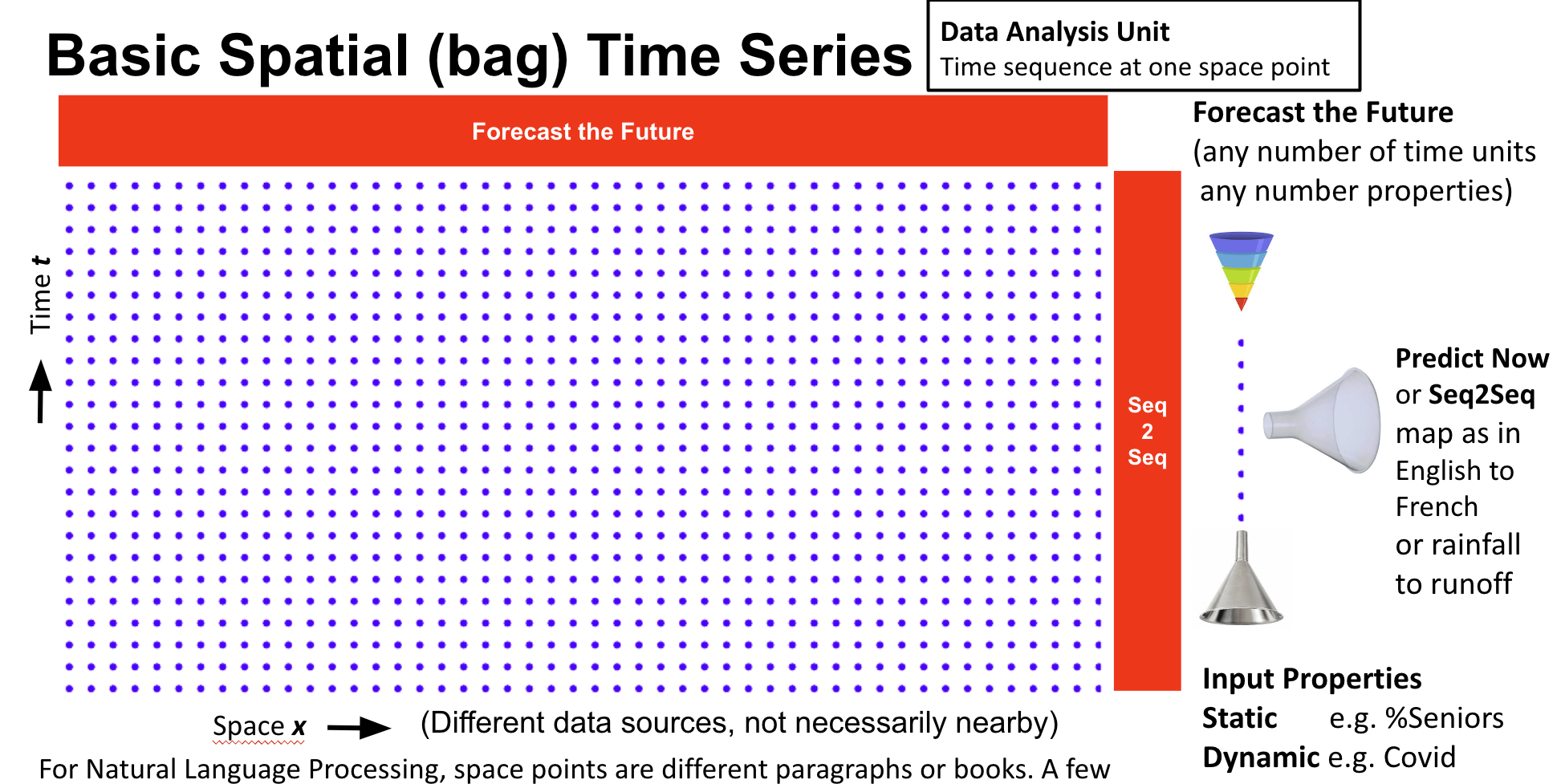
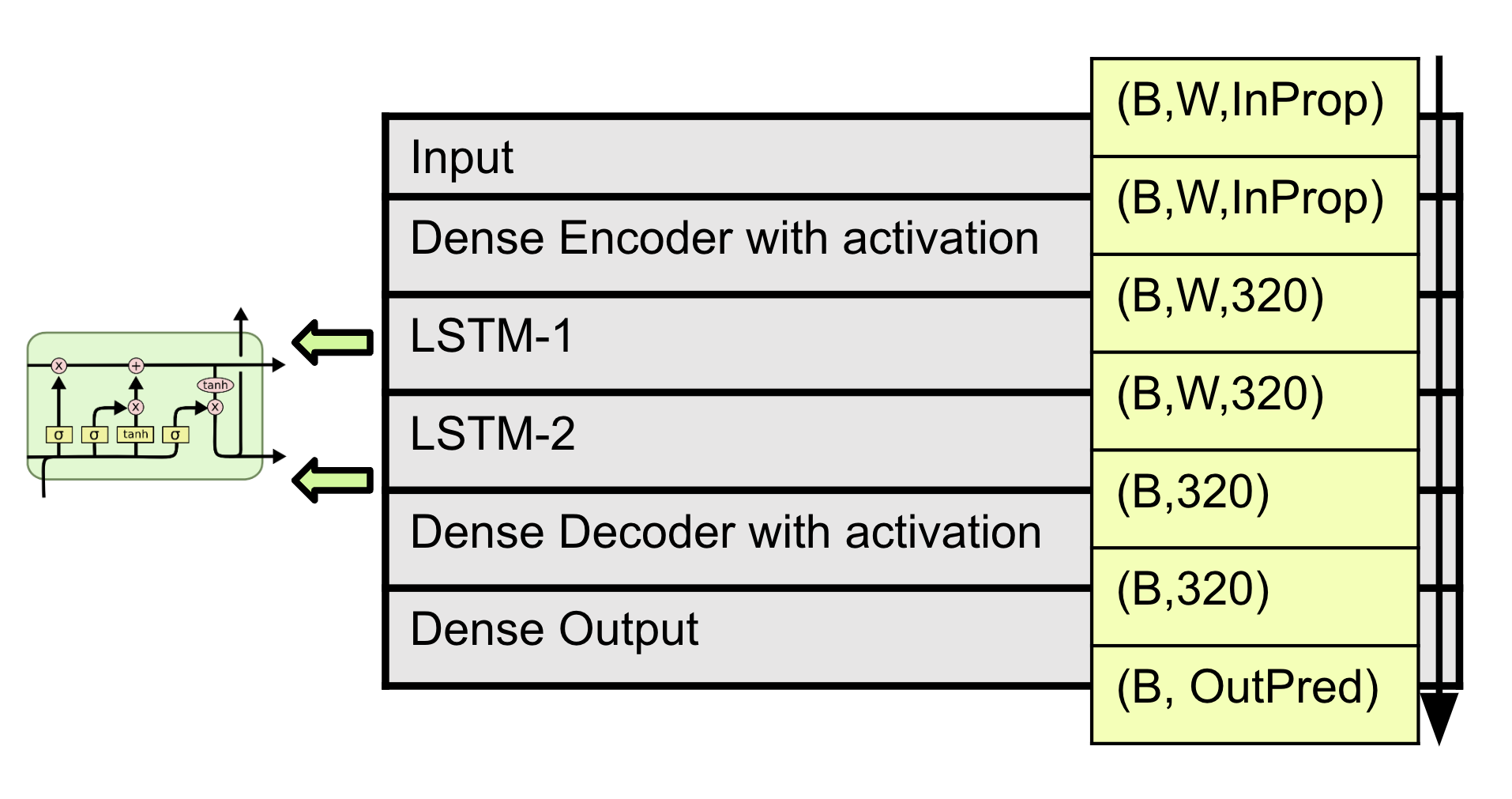
技术框架:整体框架包括数据预处理、模型构建和性能评估三个主要阶段。数据预处理阶段涉及对CAMELS和Caravan数据集中的降雨、径流数据以及静态参数进行清洗和标准化。模型构建阶段则采用了包括LSTM在内的多种深度学习模型,并设计了八种不同的模型配置,以评估外生数据的影响。性能评估阶段使用均方误差等指标来比较不同模型的预测精度。
关键创新:论文的关键创新在于强调了外生信息在水文时间序列建模中的重要性,并证明了整合这些信息可以显著提升模型性能。此外,论文还对多种深度学习模型在水文领域的适用性进行了全面的比较,为后续研究提供了参考。
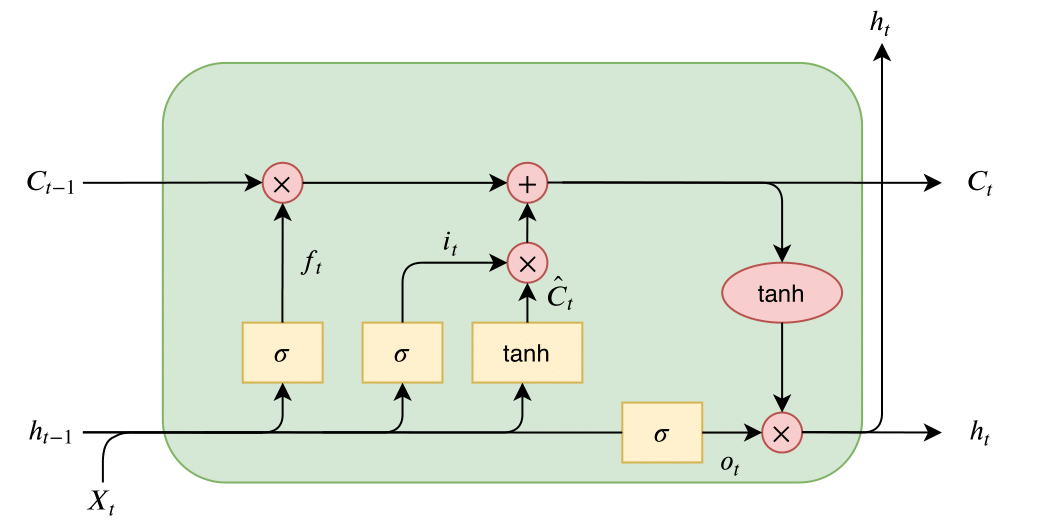
关键设计:论文的关键设计包括:1) 八种不同的模型配置,用于评估不同类型外生数据的影响;2) 使用LSTM等循环神经网络来处理时间序列数据;3) 使用均方误差作为损失函数来优化模型;4) 在Google Colab上使用Jupyter Notebook进行开源分析,方便其他研究者复现和扩展。
🖼️ 关键图片
📊 实验亮点
实验结果表明,整合外生信息可以显著提升水文时间序列的建模精度,在最大的数据集中,均方误差降低高达40%。此外,包含全面观测数据和外生数据的模型优于更有限的方法,包括基础模型。自然年度周期性外生时间序列贡献了最显著的改进。
🎯 应用场景
该研究成果可应用于更精确的水资源管理、洪水预警和干旱预测。通过提升水文时间序列的建模能力,可以为农业、环境科学和城市规划等领域提供更可靠的数据支持,从而促进可持续发展和资源优化配置。
📄 摘要(原文)
There has been active investigation into deep learning approaches for time series analysis, including foundation models. However, most studies do not address significant scientific applications. This paper aims to identify key features in time series by examining hydrology data. Our work advances computer science by emphasizing critical application features and contributes to hydrology and other scientific fields by identifying modeling approaches that effectively capture these features. Scientific time series data are inherently complex, involving observations from multiple locations, each with various time-dependent data streams and exogenous factors that may be static or time-varying and either application-dependent or purely mathematical. This research analyzes hydrology time series from the CAMELS and Caravan global datasets, which encompass rainfall and runoff data across catchments, featuring up to six observed streams and 209 static parameters across approximately 8,000 locations. Our investigation assesses the impact of exogenous data through eight different model configurations for key hydrology tasks. Results demonstrate that integrating exogenous information enhances data representation, reducing mean squared error by up to 40% in the largest dataset. Additionally, we present a detailed performance comparison of over 20 state-of-the-art pattern and foundation models. The analysis is fully open-source, facilitated by Jupyter Notebook on Google Colab for LSTM-based modeling, data preprocessing, and model comparisons. Preliminary findings using alternative deep learning architectures reveal that models incorporating comprehensive observed and exogenous data outperform more limited approaches, including foundation models. Notably, natural annual periodic exogenous time series contribute the most significant improvements, though static and other periodic factors are also valuable.