Revisiting Service Level Objectives and System Level Metrics in Large Language Model Serving
作者: Zhibin Wang, Shipeng Li, Yuhang Zhou, Xue Li, Zhonghui Zhang, Nguyen Cam-Tu, Rong Gu, Chen Tian, Guihai Chen, Sheng Zhong
分类: cs.LG, cs.AI
发布日期: 2024-10-18 (更新: 2025-10-29)
💡 一句话要点
针对LLM服务,提出与用户体验更一致的SLO和综合性评估框架Smooth Goodput
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型服务 服务水平目标 系统级指标 用户体验 性能评估
📋 核心要点
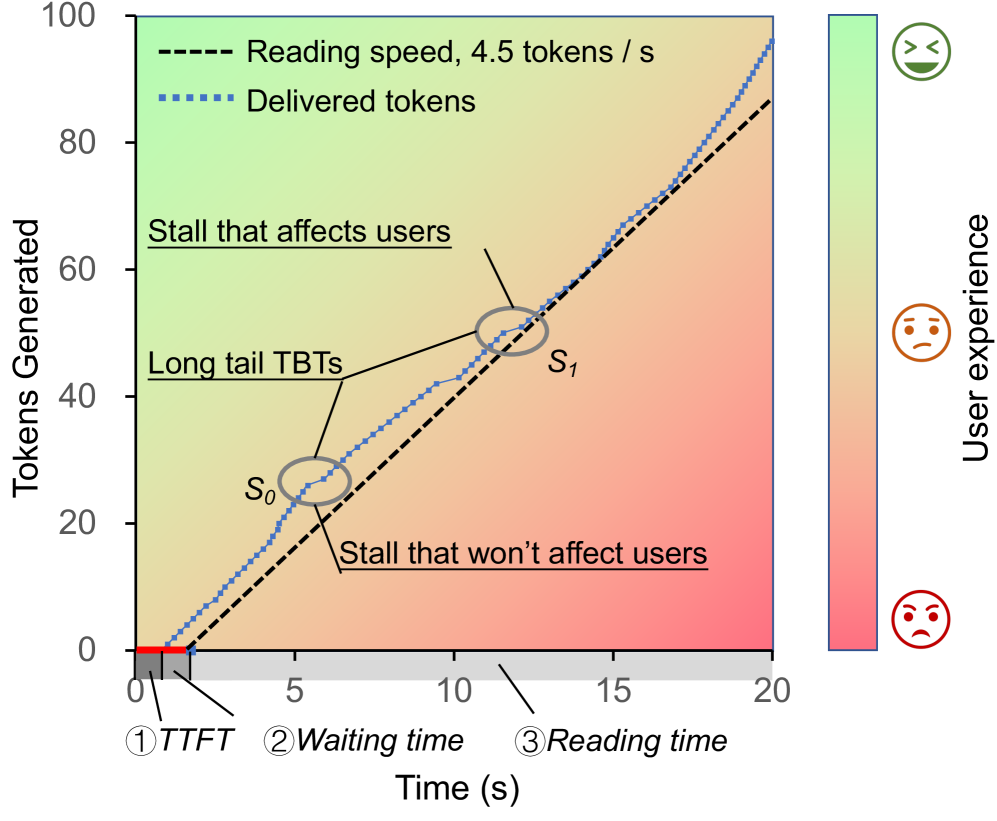
- 现有LLM服务指标存在缺陷,如延迟token交付或放弃请求可提升SLO/SLM,与用户体验相悖。
- 论文提出新的SLO,更贴合用户体验,并构建综合指标框架Smooth Goodput,整合SLO和SLM。
- 实验表明,新框架能更全面评估token交付和请求处理,有效捕捉用户体验和系统性能的最佳平衡。
📝 摘要(中文)
用户体验是大型语言模型(LLM)服务系统必须考虑的关键因素,其中服务水平目标(SLO)和系统级指标(SLM)是衡量性能的两个关键指标。然而,我们观察到现有指标存在两个显著问题:1)手动延迟某些token的交付可以提高SLO;2)主动放弃不符合SLO的请求可以提高SLM,这两种情况都与直觉相悖。本文重新审视了LLM服务中的SLO和SLM,并提出了一种与用户体验更一致的新SLO。基于此SLO,我们提出了一个名为smooth goodput的综合性指标框架,该框架集成了SLO和SLM,以反映LLM服务中用户体验的本质。通过这个统一的框架,我们重新评估了不同LLM服务系统在多种工作负载下的性能。评估结果表明,我们的指标框架提供了更全面的token交付和请求处理视图,并有效地捕捉了不同服务策略下用户体验和系统性能的最佳平衡点。
🔬 方法详解
问题定义:现有LLM服务评估指标(SLO和SLM)存在缺陷,无法真实反映用户体验。具体表现为,通过人为延迟部分token的交付可以提升SLO,而主动放弃不满足SLO的请求反而能提升SLM。这些现象与用户实际感受相悖,表明现有指标体系存在漏洞,需要重新审视和改进。
核心思路:论文的核心在于提出一种新的SLO,使其与用户体验更加一致。同时,构建一个综合性的评估框架,将SLO和SLM整合在一起,从而更全面地反映LLM服务的性能。该框架旨在解决现有指标的片面性,提供更准确、更可靠的性能评估。
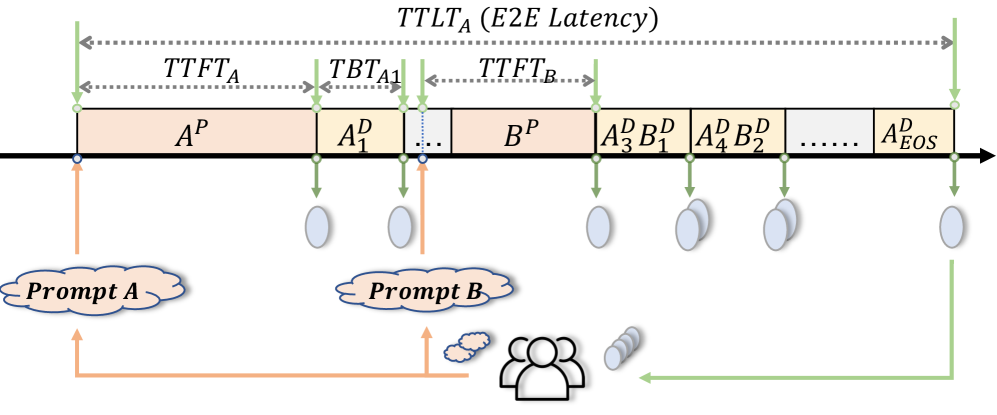
技术框架:论文提出的Smooth Goodput框架,其核心在于重新定义了SLO,并将其与SLM结合。具体流程可能包含以下步骤:首先,收集LLM服务的相关数据,包括请求的响应时间、token生成速度等。然后,根据新的SLO计算每个请求的性能指标。接着,将这些指标与SLM结合,计算Smooth Goodput。最后,利用Smooth Goodput对不同的LLM服务系统进行评估和比较。
关键创新:论文的关键创新在于提出了与用户体验更一致的SLO,并将其融入到一个综合性的评估框架中。与现有方法相比,该框架能够更准确地反映LLM服务的性能,避免了现有指标的片面性和误导性。这种综合性的评估方法为LLM服务的优化和改进提供了更可靠的依据。
关键设计:具体的技术细节(如新的SLO的定义方式、Smooth Goodput的计算公式等)在摘要中没有明确说明,属于未知信息。但可以推测,新的SLO可能考虑了token生成速度的平滑性、响应时间的抖动等因素。Smooth Goodput的计算可能采用加权平均或其他统计方法,以平衡SLO和SLM之间的关系。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了Smooth Goodput框架的有效性,表明该框架能够更全面地评估token交付和请求处理,并有效地捕捉不同服务策略下用户体验和系统性能的最佳平衡点。具体的性能数据和提升幅度在摘要中未给出,属于未知信息,但实验结果证实了新指标框架的优越性。
🎯 应用场景
该研究成果可应用于各种在线LLM服务平台,帮助开发者更准确地评估和优化服务性能,提升用户体验。通过使用Smooth Goodput框架,可以更好地平衡系统吞吐量和用户满意度,从而提高LLM服务的竞争力。此外,该研究也为LLM服务评估指标体系的构建提供了新的思路。
📄 摘要(原文)
User experience is a critical factor Large Language Model (LLM) serving systems must consider, where service level objectives (SLOs) considering the experience of individual requests and system level metrics (SLMs) considering the overall system performance are two key performance measures. However, we observe two notable issues in existing metrics: 1) manually delaying the delivery of some tokens can improve SLOs, and 2) actively abandoning requests that do not meet SLOs can improve SLMs, both of which are counterintuitive. In this paper, we revisit SLOs and SLMs in LLM serving, and propose a new SLO that aligns with user experience. Based on the SLO, we propose a comprehensive metric framework called smooth goodput, which integrates SLOs and SLMs to reflect the nature of user experience in LLM serving. Through this unified framework, we reassess the performance of different LLM serving systems under multiple workloads. Evaluation results show that our metric framework provides a more comprehensive view of token delivery and request processing, and effectively captures the optimal point of user experience and system performance with different serving strategies.