WARPD: World model Assisted Reactive Policy Diffusion
作者: Shashank Hegde, Satyajeet Das, Gautam Salhotra, Gaurav S. Sukhatme
分类: cs.LG, cs.AI, cs.RO
发布日期: 2024-10-17 (更新: 2025-12-12)
备注: Outstanding Paper Award at the Embodied World Models for Decision Making Workshop at NeurIPS 2025
💡 一句话要点
提出WARPD以解决扩展动作视野与推理成本问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模仿学习 扩散模型 闭环策略 机器人操控 高频控制 多任务学习 鲁棒性
📋 核心要点
- 现有的扩散策略在高控制频率的机器人任务中面临推理速度慢和模型体积大的挑战。
- WARPD通过直接生成闭环策略,学习参数空间中的行为分布,克服了传统方法的局限性。
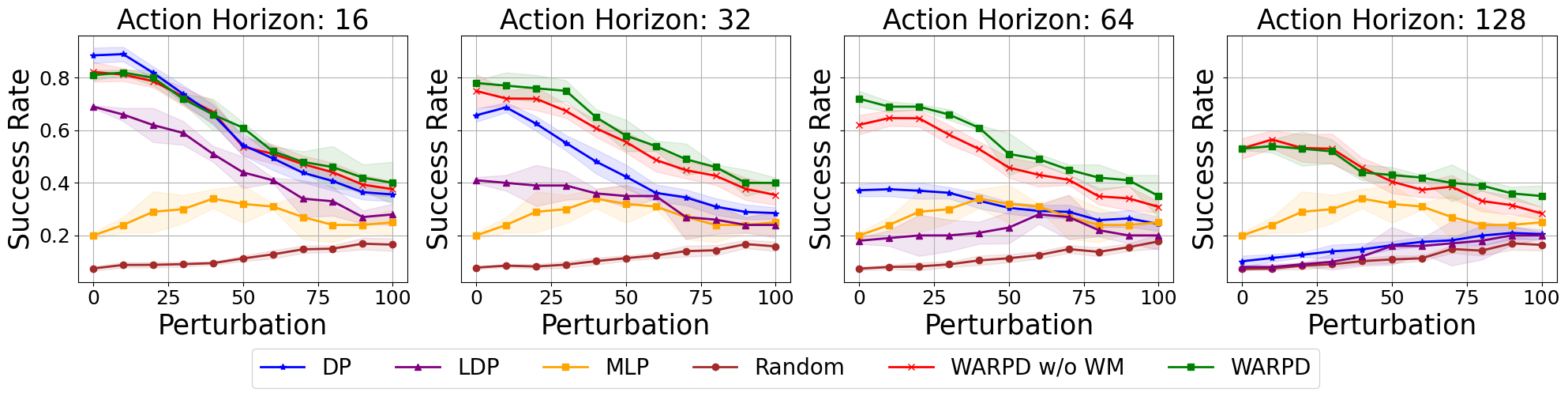
- 实验结果显示,WARPD在长视野和扰动环境中表现优于DP,且推理成本显著降低。
📝 摘要(中文)
随着开源机器人数据的日益丰富,模仿学习成为操控和运动的有前景的方法。扩散模型被广泛应用于训练大型通用策略,尽管其在建模多模态动作分布方面表现出色,但也带来了模型体积大和推理速度慢的问题,尤其在高控制频率的机器人任务中尤为明显。此外,流行的扩散策略(DP)在性能与动作视野之间存在权衡。为了解决这些挑战,本文提出了WARPD(世界模型辅助反应策略扩散),该方法直接生成闭环策略,而非开放式轨迹。通过在参数空间中学习行为分布,WARPD在延长动作视野和降低推理成本方面具有显著优势。实验证明,WARPD在长视野和扰动环境中优于DP,并在多任务性能上与DP相当,但每步推理所需的FLOPs仅为DP的约1/45。
🔬 方法详解
问题定义:本文旨在解决现有扩散策略在高控制频率任务中推理速度慢和模型体积大的问题。传统的扩散策略在性能与动作视野之间存在权衡,导致跟踪误差的累积。
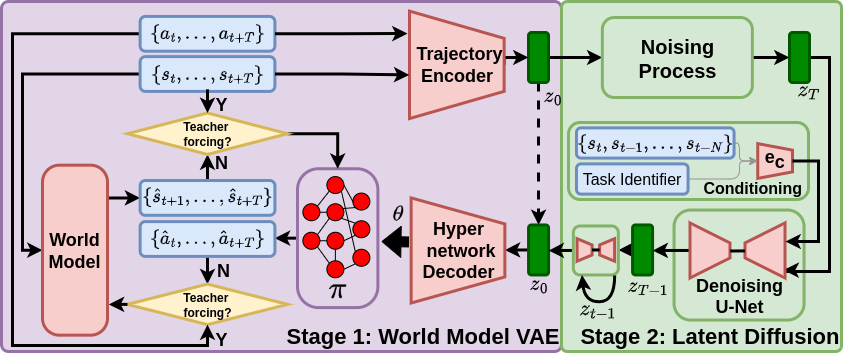
核心思路:WARPD的核心思想是直接生成闭环策略,而非开放式轨迹。这种方法通过在参数空间中学习行为分布,能够延长动作视野并提高对扰动的鲁棒性,同时保持高任务性能。
技术框架:WARPD的整体架构包括数据采集、模型训练和策略生成三个主要模块。首先,通过世界模型获取环境信息,然后在参数空间中训练策略,最后生成闭环控制策略。
关键创新:WARPD的主要创新在于其直接生成闭环策略的能力,区别于传统的开放式轨迹生成方法。这种设计使得模型在面对扰动时更具鲁棒性,并且能够在较长的动作视野内保持高性能。
关键设计:在关键设计方面,WARPD采用了特定的损失函数来优化策略的稳定性,并在网络结构上进行了调整,以适应参数空间中的行为分布学习。
🖼️ 关键图片

📊 实验亮点
实验结果表明,WARPD在长视野和扰动环境中优于传统的扩散策略(DP),在多任务性能上与DP相当,但每步推理所需的FLOPs仅为DP的约1/45,显示出显著的性能提升和效率优化。
🎯 应用场景
WARPD的研究成果在机器人操控、自动驾驶和智能制造等领域具有广泛的应用潜力。通过提高策略生成的效率和鲁棒性,该方法能够在复杂和动态环境中实现更高效的决策,推动智能机器人技术的进步。
📄 摘要(原文)
With the increasing availability of open-source robotic data, imitation learning has become a promising approach for both manipulation and locomotion. Diffusion models are now widely used to train large, generalized policies that predict controls or trajectories, leveraging their ability to model multimodal action distributions. However, this generality comes at the cost of larger model sizes and slower inference, an acute limitation for robotic tasks requiring high control frequencies. Moreover, Diffusion Policy (DP), a popular trajectory-generation approach, suffers from a trade-off between performance and action horizon: fewer diffusion queries lead to larger trajectory chunks, which in turn accumulate tracking errors. To overcome these challenges, we introduce WARPD (World model Assisted Reactive Policy Diffusion), a method that generates closed-loop policies (weights for neural policies) directly, instead of open-loop trajectories. By learning behavioral distributions in parameter space rather than trajectory space, WARPD offers two major advantages: (1) extended action horizons with robustness to perturbations, while maintaining high task performance, and (2) significantly reduced inference costs. Empirically, WARPD outperforms DP in long-horizon and perturbed environments, and achieves multitask performance on par with DP while requiring only ~ 1/45th of the inference-time FLOPs per step.