Personalized Adaptation via In-Context Preference Learning
作者: Allison Lau, Younwoo Choi, Vahid Balazadeh, Keertana Chidambaram, Vasilis Syrgkanis, Rahul G. Krishnan
分类: cs.LG, cs.CL
发布日期: 2024-10-17
💡 一句话要点
提出Preference Pretrained Transformer (PPT),通过上下文偏好学习实现个性化自适应
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化推荐 上下文学习 Transformer 强化学习 人类反馈 在线学习 偏好建模 自适应学习
📋 核心要点
- 现有强化学习从人类反馈(RLHF)的方法忽略个体用户偏好,导致个性化效果不理想。
- PPT利用Transformer的上下文学习能力,通过离线预训练和在线适应,动态调整模型以适应个体偏好。
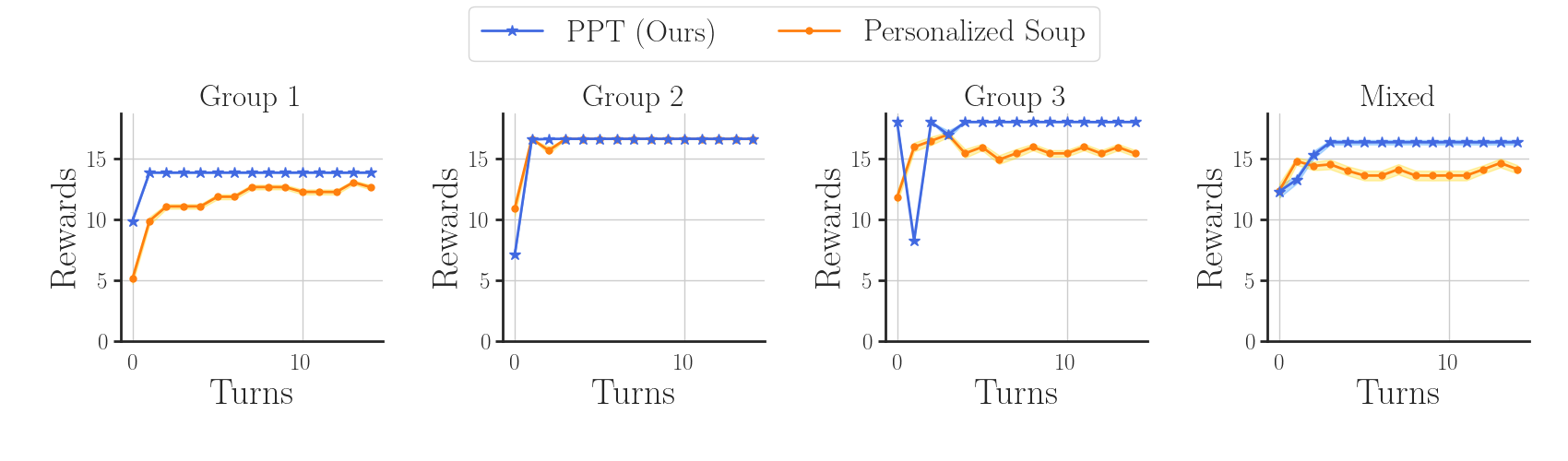
- 实验表明,PPT在个性化适应方面优于现有方法,并显著降低了计算成本,展现了上下文学习的潜力。
📝 摘要(中文)
本文提出Preference Pretrained Transformer (PPT),一种利用在线用户反馈进行自适应个性化的新方法。现有方法通常忽略个体用户偏好,导致个性化效果欠佳。PPT利用Transformer的上下文学习能力,动态适应个体偏好。该方法包含两个阶段:(1) 离线阶段,使用历史依赖损失函数训练单个策略模型;(2) 在线阶段,模型通过上下文学习适应用户偏好。在上下文Bandit设置下,实验结果表明PPT实现了优于现有方法的个性化自适应,并显著降低了计算成本。该研究结果表明,上下文学习在大语言模型中具有实现可扩展和高效个性化的潜力。
🔬 方法详解
问题定义:现有基于人类反馈的强化学习方法在对语言模型进行个性化调整时,通常难以有效捕捉和利用个体用户的偏好信息。这导致模型在服务不同用户时,无法提供最优的个性化体验,用户满意度降低。现有方法的痛点在于无法高效且低成本地实现用户偏好的快速适应。
核心思路:PPT的核心思路是利用Transformer模型的上下文学习能力,将用户的历史反馈作为上下文信息输入模型,使模型能够动态地学习和适应用户的个性化偏好。通过这种方式,模型可以在线地根据用户的实时反馈进行调整,而无需重新训练整个模型。
技术框架:PPT方法包含两个主要阶段:离线预训练阶段和在线适应阶段。在离线预训练阶段,使用历史用户反馈数据,通过一个历史依赖的损失函数训练一个通用的策略模型。该模型学习从历史交互中提取用户偏好的能力。在线适应阶段,将用户的实时反馈作为上下文信息输入预训练好的模型,模型利用上下文学习能力,动态调整策略以适应当前用户的偏好。
关键创新:PPT的关键创新在于将上下文学习应用于个性化偏好建模。与传统的微调方法相比,PPT无需为每个用户单独训练模型,而是通过上下文信息动态调整模型行为,从而显著降低了计算成本和存储需求。此外,历史依赖损失函数的设计使得模型能够更好地学习用户偏好的演变过程。
关键设计:PPT使用Transformer作为其核心架构,利用其强大的上下文建模能力。历史依赖损失函数的设计旨在鼓励模型学习用户偏好的时间依赖性。具体的损失函数形式未知,但其核心思想是考虑历史交互对当前决策的影响。在线适应阶段,上下文信息的组织方式和输入方式对模型的性能至关重要,具体细节未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PPT在上下文Bandit设置下实现了优于现有方法的个性化自适应效果。具体而言,PPT在个性化推荐任务上的性能指标(例如点击率、转化率)显著高于传统的非个性化方法和基于微调的个性化方法。此外,PPT还显著降低了计算成本,使其更适用于大规模用户场景。
🎯 应用场景
PPT方法可应用于各种需要个性化推荐或决策的场景,例如个性化新闻推荐、在线广告投放、智能对话系统等。通过学习和适应个体用户的偏好,PPT可以显著提升用户体验和满意度,并为企业带来更高的收益。未来,该方法有望扩展到更复杂的任务和领域,例如个性化医疗和教育。
📄 摘要(原文)
Reinforcement Learning from Human Feedback (RLHF) is widely used to align Language Models (LMs) with human preferences. However, existing approaches often neglect individual user preferences, leading to suboptimal personalization. We present the Preference Pretrained Transformer (PPT), a novel approach for adaptive personalization using online user feedback. PPT leverages the in-context learning capabilities of transformers to dynamically adapt to individual preferences. Our approach consists of two phases: (1) an offline phase where we train a single policy model using a history-dependent loss function, and (2) an online phase where the model adapts to user preferences through in-context learning. We demonstrate PPT's effectiveness in a contextual bandit setting, showing that it achieves personalized adaptation superior to existing methods while significantly reducing the computational costs. Our results suggest the potential of in-context learning for scalable and efficient personalization in large language models.