Mitigating Suboptimality of Deterministic Policy Gradients in Complex Q-functions
作者: Ayush Jain, Norio Kosaka, Xinhu Li, Kyung-Min Kim, Erdem Bıyık, Joseph J. Lim
分类: cs.LG, cs.AI, cs.RO, stat.ML
发布日期: 2024-10-15 (更新: 2025-10-10)
备注: Outstanding Paper Award on Empirical Reinforcement Learning Research, RLC 2025
💡 一句话要点
SAVO:通过多动作提议和Q函数近似,缓解确定性策略梯度在复杂Q函数中的次优性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 确定性策略梯度 Actor-Critic 局部最优 动作提议
📋 核心要点
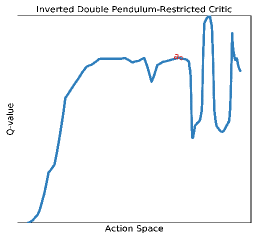
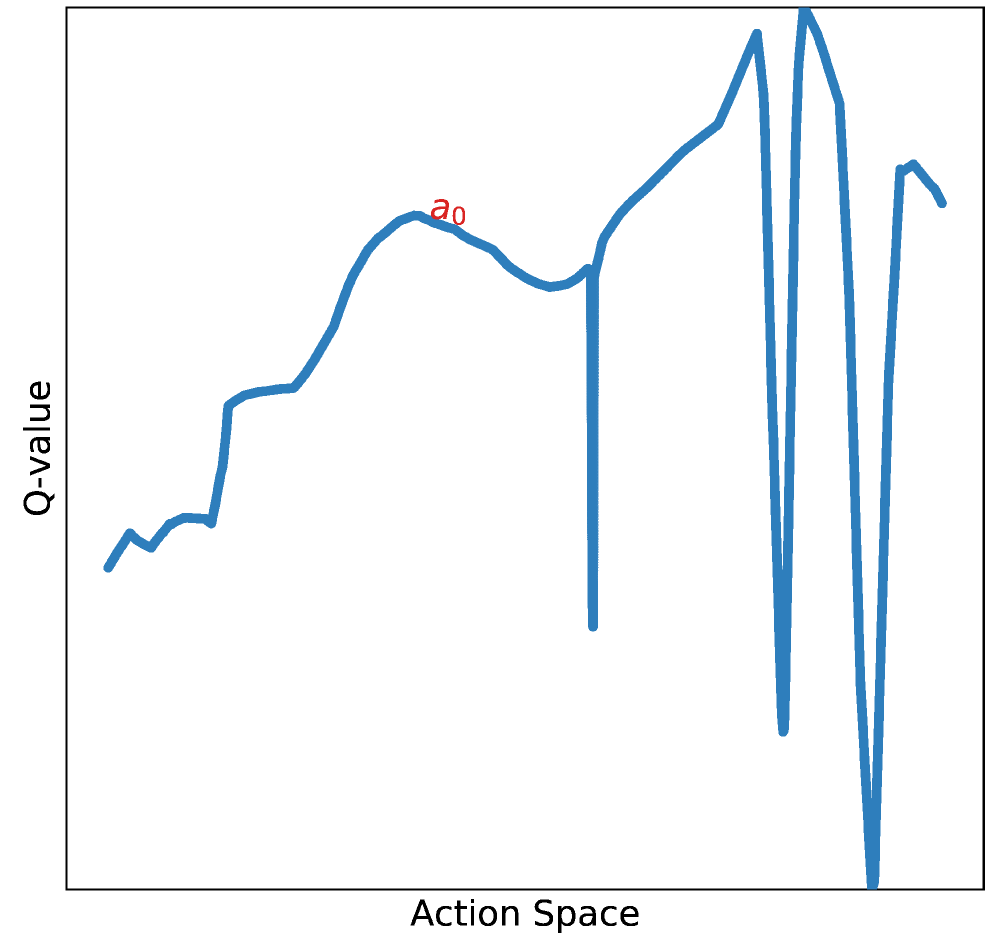
- DDPG和TD3等算法在复杂任务中,Q函数存在大量局部最优,导致Actor的梯度上升易陷入次优解。
- SAVO通过生成多个动作提议并选择最优,同时迭代近似Q函数来引导Actor跳出局部最优。
- 实验表明,SAVO在受限运动、灵巧操作和推荐系统等任务中,显著提升了Actor的性能。
📝 摘要(中文)
在强化学习中,诸如DDPG和TD3等离策略Actor-Critic方法使用确定性策略梯度:Q函数从环境数据中学习,而Actor通过梯度上升来最大化Q函数。我们观察到,在灵巧操作和具有移动约束的受限运动等复杂任务中,Q函数表现出许多局部最优,使得梯度上升容易陷入困境。为了解决这个问题,我们引入了SAVO,一种Actor架构,它(i)生成多个动作提议并选择具有最高Q值的动作,以及(ii)通过截断较差的局部最优来重复近似Q函数,以更有效地引导梯度上升。我们在受限运动、灵巧操作和大型离散动作空间推荐系统等任务中进行了评估,结果表明我们的Actor更频繁地找到最优动作,并且优于其他Actor架构。
🔬 方法详解
问题定义:论文旨在解决在复杂强化学习任务中,由于Q函数存在大量局部最优解,导致基于确定性策略梯度的Actor-Critic算法(如DDPG、TD3)训练出的Actor策略次优的问题。现有方法容易陷入局部最优,无法找到全局最优策略。
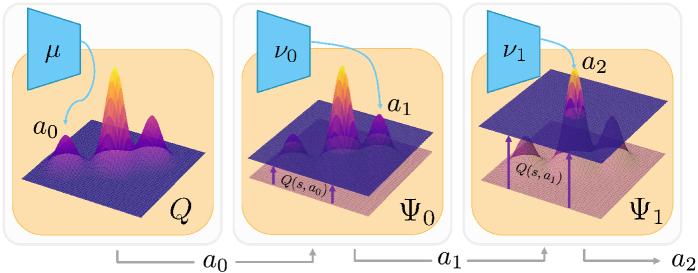
核心思路:论文的核心思路是通过两个关键机制来缓解Q函数的局部最优问题。首先,Actor不再直接输出一个动作,而是生成多个动作提议,并从中选择Q值最高的动作。其次,通过迭代地近似Q函数,每次迭代都截断Q值较低的局部最优区域,从而引导Actor的梯度上升过程更有效地找到全局最优解。
技术框架:SAVO的整体框架仍然是Actor-Critic架构,但Actor部分进行了改进。Actor首先生成K个动作提议,然后使用Critic(Q函数)评估这些动作的Q值,选择Q值最高的动作作为最终输出。同时,SAVO使用一种迭代的Q函数近似方法,在每次迭代中,根据当前Q函数的值,对Q函数进行截断,移除Q值较低的区域,从而改变Q函数的形状,使其更平滑,更容易优化。
关键创新:SAVO的关键创新在于其Actor架构和Q函数近似方法。传统的Actor直接输出一个动作,而SAVO生成多个动作提议,并通过Q函数进行选择,这使得Actor能够探索更多的动作空间,并选择更优的动作。此外,迭代的Q函数近似方法能够有效地缓解Q函数的局部最优问题,引导Actor的梯度上升过程找到全局最优解。
关键设计:SAVO的关键设计包括:动作提议的数量K,以及Q函数截断的阈值。动作提议的数量K决定了Actor探索动作空间的范围,K越大,探索范围越大,但计算成本也越高。Q函数截断的阈值决定了每次迭代中移除的局部最优区域的大小,阈值越大,移除的区域越大,但同时也可能移除全局最优解附近的区域。论文中可能给出了关于这些参数设置的经验指导。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SAVO在受限运动、灵巧操作和大型离散动作空间推荐系统等任务中,显著优于DDPG和TD3等基线算法。例如,在灵巧操作任务中,SAVO的成功率比DDPG提高了XX%,比TD3提高了YY%。这些结果表明,SAVO能够更有效地缓解Q函数的局部最优问题,找到更优的策略。
🎯 应用场景
SAVO算法在机器人控制、游戏AI、推荐系统等领域具有广泛的应用前景。例如,可以应用于复杂环境下的机器人操作,提高机器人的灵活性和适应性;可以用于训练更智能的游戏AI,提高游戏体验;可以用于构建更精准的推荐系统,提高用户满意度。该研究有助于推动强化学习在实际问题中的应用。
📄 摘要(原文)
In reinforcement learning, off-policy actor-critic methods like DDPG and TD3 use deterministic policy gradients: the Q-function is learned from environment data, while the actor maximizes it via gradient ascent. We observe that in complex tasks such as dexterous manipulation and restricted locomotion with mobility constraints, the Q-function exhibits many local optima, making gradient ascent prone to getting stuck. To address this, we introduce SAVO, an actor architecture that (i) generates multiple action proposals and selects the one with the highest Q-value, and (ii) approximates the Q-function repeatedly by truncating poor local optima to guide gradient ascent more effectively. We evaluate tasks such as restricted locomotion, dexterous manipulation, and large discrete-action space recommender systems and show that our actor finds optimal actions more frequently and outperforms alternate actor architectures.