BrainGPT: Unleashing the Potential of EEG Generalist Foundation Model by Autoregressive Pre-training
作者: Tongtian Yue, Xuange Gao, Shuning Xue, Yepeng Tang, Longteng Guo, Jie Jiang, Jing Liu
分类: eess.SP, cs.LG
发布日期: 2024-10-14 (更新: 2025-08-29)
备注: This work has been submitted to the IEEE for possible publication
💡 一句话要点
提出BrainGPT,通过自回归预训练释放脑电图通用基础模型的潜力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 脑电图 通用基础模型 自回归预训练 迁移学习 脑机接口
📋 核心要点
- 现有脑电图模型受限于数据多样性、预训练方法陈旧和迁移学习不足,导致模型通用性差,只能针对特定数据集。
- BrainGPT提出电极建模策略,将每个电极视为基本单元,并采用自回归预训练方法,捕捉脑电信号的时序依赖。
- 实验表明,BrainGPT在多个脑电图任务上超越现有专用模型,验证了其通用性和有效性,并具备良好的可扩展性。
📝 摘要(中文)
脑电图(EEG)信号对于深入了解自发性大脑活动至关重要,在神经科学研究中具有重要意义。然而,由于数据格式多样、预训练范式过时以及迁移学习方法有限,通用脑电图模型的探索受到限制,导致只能在单个数据集上训练出专用模型。本文提出了BrainGPT,这是第一个旨在应对这些挑战的通用脑电图基础模型。首先,我们提出了一种电极建模策略,将每个电极视为一个基本单元,从而能够整合来自多达138个电极的各种脑电图数据集,总共积累了3750万个预训练样本。其次,我们开发了第一个自回归脑电图预训练模型,摆脱了传统的掩码自编码器方法,转向下一个信号预测任务,从而更好地捕捉脑电图数据的序列和时间依赖性。我们还探索了模型扩展规律,模型参数高达11亿,是迄今为止脑电图研究中最大的模型。第三,我们引入了一种多任务迁移学习范式,使用一个跨任务共享的可学习电极图网络,首次证实了多任务的兼容性和协同作用。作为第一个通用脑电图基础模型,BrainGPT显示出与各种信号采集设备、受试者和任务的广泛兼容性。它支持多达138个电极以及它们的任意组合作为输入。此外,我们同时在12个基准上的5个不同任务上评估了它。BrainGPT在所有下游任务中始终优于现有的专用模型,其有效性通过广泛的消融研究得到了进一步验证。这项工作为通用脑电图建模开辟了一个新的方向,为各种脑电图应用提供了更高的可扩展性、可迁移性和适应性。代码和模型将会开源。
🔬 方法详解
问题定义:现有脑电图模型通常是针对特定数据集和任务设计的,缺乏通用性和可迁移性。数据格式多样、预训练方法落后以及迁移学习策略不足是主要痛点。
核心思路:BrainGPT的核心思路是构建一个通用的脑电图基础模型,通过大规模自回归预训练学习脑电信号的通用表示,从而能够适应各种不同的脑电图任务和数据集。通过电极建模策略,将每个电极视为基本单元,整合不同数据集。
技术框架:BrainGPT的整体框架包括三个主要部分:1) 电极建模:将来自不同电极的脑电信号作为独立输入;2) 自回归预训练:使用自回归模型预测下一个时间步的脑电信号;3) 多任务迁移学习:使用可学习的电极图网络在多个任务上进行迁移学习。
关键创新:BrainGPT的关键创新在于:1) 提出了电极建模策略,能够整合来自不同电极的脑电图数据;2) 采用了自回归预训练方法,更好地捕捉脑电信号的时序依赖性;3) 引入了多任务迁移学习范式,提高了模型的泛化能力。
关键设计:BrainGPT使用了Transformer架构作为自回归模型的基础。模型参数规模高达11亿。在多任务迁移学习中,使用可学习的电极图网络来共享不同任务之间的知识。损失函数包括预训练的自回归损失和下游任务的监督学习损失。
🖼️ 关键图片
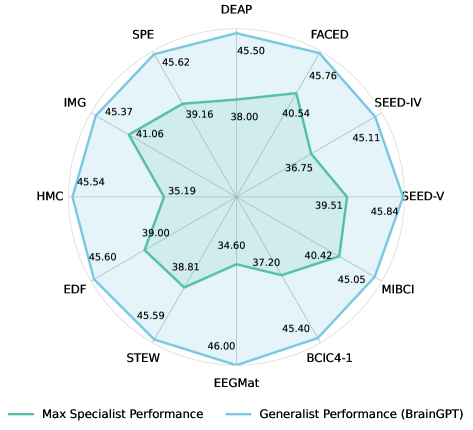
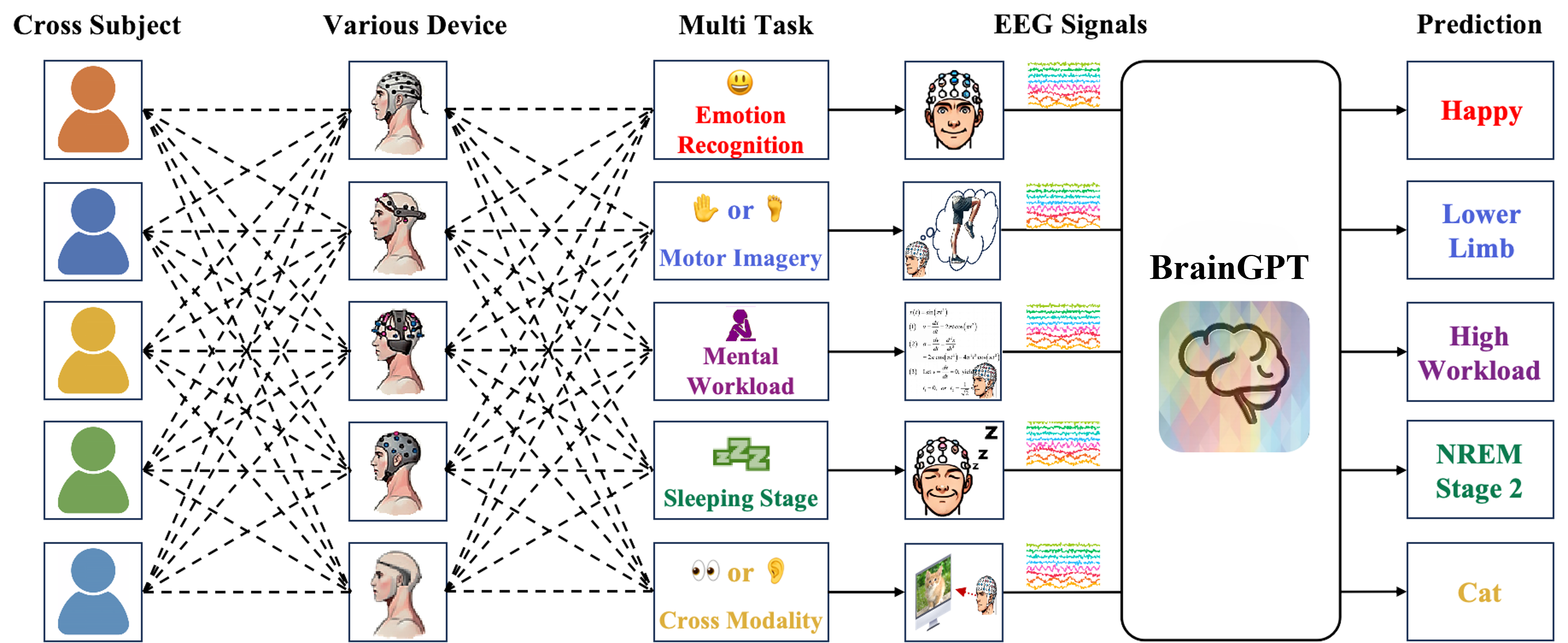

📊 实验亮点
BrainGPT在12个基准数据集上的5个不同任务上进行了评估,结果表明,BrainGPT在所有下游任务中始终优于现有的专用模型。消融研究进一步验证了电极建模策略、自回归预训练和多任务迁移学习的有效性。该模型参数量达到11亿,是目前脑电研究中最大的模型。
🎯 应用场景
BrainGPT的潜在应用领域包括脑机接口、神经疾病诊断、认知状态监测等。该研究的实际价值在于提供了一个通用的脑电图模型,可以降低开发特定脑电图应用的成本和时间。未来,BrainGPT可以进一步扩展到其他神经信号,例如脑磁图(MEG)和颅内脑电图(iEEG),从而构建更强大的神经科学基础模型。
📄 摘要(原文)
Electroencephalogram (EEG) signals are pivotal in providing insights into spontaneous brain activity, highlighting their significant importance in neuroscience research. However, the exploration of versatile EEG models is constrained by diverse data formats, outdated pre-training paradigms, and limited transfer learning methods, only leading to specialist models on single dataset. In this paper, we introduce EEGPT, the first generalist EEG foundation model designed to address these challenges. First, we propose an electrode-wise modeling strategy that treats each electrode as a fundamental unit, enabling the integration of diverse EEG datasets collected from up to 138 electrodes, amassing 37.5M pre-training samples. Second, we develop the first autoregressive EEG pre-trained model, moving away from traditional masked autoencoder approaches to a next signal prediction task that better captures the sequential and temporal dependencies of EEG data. We also explore scaling laws with model up to 1.1B parameters: the largest in EEG research to date. Third, we introduce a multi-task transfer learning paradigm using a learnable electrode graph network shared across tasks, which for the first time confirms multi-task compatibility and synergy. As the first generalist EEG foundation model, EEGPT shows broad compatibility with various signal acquisition devices, subjects, and tasks. It supports up to 138 electrodes and any combination thereof as input. Furthermore, we simultaneously evaluate it on 5 distinct tasks across 12 benchmarks. EEGPT consistently outperforms existing specialist models across all downstream tasks, with its effectiveness further validated through extensive ablation studies. This work sets a new direction for generalist EEG modeling, offering improved scalability, transferability, and adaptability for a wide range of EEG applications. The code and models will be released.