SGLP: A Similarity Guided Fast Layer Partition Pruning for Compressing Large Deep Models
作者: Yuqi Li, Yao Lu, Junhao Dong, Zeyu Dong, Chuanguang Yang, Xin Yin, Yihao Chen, Jianping Gou, Yingli Tian, Tingwen Huang
分类: cs.LG, cs.CV
发布日期: 2024-10-14 (更新: 2025-11-14)
备注: 16 pages
💡 一句话要点
提出SGLP:一种基于相似性引导的快速层划分剪枝方法,用于压缩大型深度模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 层剪枝 模型压缩 深度学习 表示相似性 中心核对齐 Fisher最优分割 GradNorm
📋 核心要点
- 现有层剪枝方法忽略了深度网络中层间的内在联系,导致剪枝后模型难以有效保留预训练网络的关键特征。
- SGLP通过计算层间表示相似性,将网络划分为语义连贯的层段,并在段内进行有针对性的剪枝。
- 实验表明,SGLP在图像分类和大型语言模型上,相比现有方法,实现了更高的压缩率和更小的性能损失。
📝 摘要(中文)
层剪枝是一种有效的减少网络大小和提高计算效率的方法,它通过移除预训练网络中的冗余层来实现。然而,现有的层剪枝方法大多忽略了复杂深度神经网络中不同层之间的内在联系和相互依赖性。这种疏忽可能导致剪枝后的模型无法像预期的那样有效地保留预训练网络的基本特征。为了解决这些限制,我们提出了一种相似性引导的层划分(SGLP)剪枝方法,这是一种新颖的剪枝框架,它利用表示相似性来指导高效且知情的层移除,从而压缩大型深度模型。我们的方法首先采用中心核对齐(CKA)来量化层之间的表示相似性,从而揭示网络中的结构模式。然后,我们将Fisher最优分割应用于相似性矩阵,将网络划分为语义连贯的层段。这种分割允许剪枝决策尊重层间的相互依赖性并保留必要的知识。在每个段内,我们引入了一种无需微调的重要性评估方法GradNorm,以有针对性的、分段的方式识别和移除冗余层。在图像分类任务和大型语言模型(LLM)上的实验结果表明,我们提出的SGLP在准确性和效率方面均优于最先进的方法。我们的方法实现了显著的模型压缩,同时性能下降最小,使其非常适合在资源受限的环境中部署。
🔬 方法详解
问题定义:论文旨在解决大型深度模型层剪枝过程中,忽略层间依赖关系导致剪枝后模型性能下降的问题。现有方法通常独立地评估和剪枝每一层,未能充分利用网络结构信息,导致剪枝后的模型丢失了重要的知识表示。
核心思路:论文的核心思路是利用层之间的表示相似性来指导层剪枝过程。通过计算层之间的相似性,可以将网络划分为多个语义相关的层段,然后在每个层段内进行剪枝,从而在保证模型性能的同时,减少模型的参数量和计算复杂度。这种方法能够更好地保留预训练模型的知识,避免过度剪枝。
技术框架:SGLP框架主要包含三个阶段:1) 相似性计算:使用Centered Kernel Alignment (CKA) 计算网络中各层之间的表示相似性,构建相似性矩阵。2) 层划分:利用Fisher Optimal Segmentation算法,基于相似性矩阵将网络划分为多个语义相关的层段。3) 层剪枝:在每个层段内,使用GradNorm评估各层的重要性,并移除冗余层。
关键创新:SGLP的关键创新在于:1) 提出了一种基于表示相似性的层划分策略,能够有效地识别网络中的语义模块。2) 结合CKA和Fisher Optimal Segmentation,实现了一种自动化的层划分方法,无需人工干预。3) 使用GradNorm进行无微调的重要性评估,降低了剪枝过程的计算成本。
关键设计:CKA用于计算层间相似性,其值越高表示两层之间的表示越相似。Fisher Optimal Segmentation算法用于寻找最佳的层划分方案,目标是最小化层段内的相似性差异,最大化层段间的相似性差异。GradNorm用于评估层的重要性,其值越大表示该层越重要。具体参数设置和损失函数细节在论文中未明确给出,属于未知信息。
🖼️ 关键图片

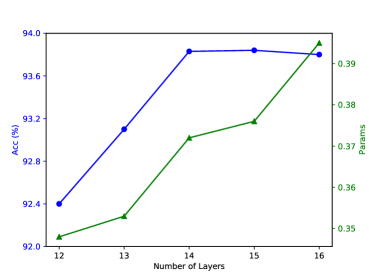
📊 实验亮点
SGLP在图像分类任务和大型语言模型上均取得了显著的性能提升。在图像分类任务中,SGLP在保持相当精度的前提下,实现了比现有方法更高的压缩率。对于大型语言模型,SGLP能够在减少模型参数的同时,保持甚至提高模型的性能。具体的性能数据和对比基线在论文中进行了详细的展示。
🎯 应用场景
SGLP适用于各种需要部署大型深度模型的场景,尤其是在资源受限的边缘设备上,如移动设备、嵌入式系统和物联网设备。通过压缩模型大小和提高计算效率,SGLP可以降低模型的存储成本、功耗和延迟,从而实现更高效的AI应用。此外,该方法还可以应用于模型加速、知识蒸馏等领域,具有广泛的应用前景。
📄 摘要(原文)
Layer pruning has emerged as a potent approach to remove redundant layers in the pre-trained network on the purpose of reducing network size and improve computational efficiency. However, existing layer pruning methods mostly overlook the intrinsic connections and inter-dependencies between different layers within complicated deep neural networks. This oversight can result in pruned models that do not preserve the essential characteristics of the pre-trained network as effectively as desired. To address these limitations, we propose a Similarity-Guided Layer Partition (SGLP) Pruning, a novel pruning framework that exploits representation similarity to guide efficient and informed layer removal for compressing large deep models. Our method begins by employing Centered Kernel Alignment (CKA) to quantify representational similarity between layers, uncovering structural patterns within the network. We then apply Fisher Optimal Segmentation on the similarity matrix to partition the network into semantically coherent layer segments. This segmentation allows pruning decisions to respect layer interdependencies and preserve essential knowledge. Within each segment, we introduce a fine-tuning-free importance evaluation using GradNorm, identifying and removing redundant layers in a targeted, segment-wise manner. Experimental results on both image classification tasks and large language models (LLMs) demonstrate that our proposed SGLP outperforms the state-of-the-art methods in accuracy and efficiency. Our approach achieves significant model compression with minimal performance degradation, making it well-suited for deployment in resource-limited environments.