Mimetic Initialization Helps State Space Models Learn to Recall
作者: Asher Trockman, Hrayr Harutyunyan, J. Zico Kolter, Sanjiv Kumar, Srinadh Bhojanapalli
分类: cs.LG, cs.CL
发布日期: 2024-10-14
💡 一句话要点
提出一种模仿初始化方法,提升状态空间模型在记忆任务中的学习能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 状态空间模型 Mamba 记忆任务 初始化方法 注意力机制
📋 核心要点
- 状态空间模型在记忆任务中表现不佳,可能并非受限于模型容量,而是由于训练困难。
- 论文提出一种结构化的初始化技术,使状态空间模型更容易模仿注意力机制,从而提升记忆能力。
- 实验表明,该初始化方法显著降低了Mamba学习复制和联想记忆的难度,提升了模型性能。
📝 摘要(中文)
近期的研究表明,由于状态空间模型(如Mamba)的状态大小相对于输入序列长度是恒定的,因此在基于记忆的任务中,其性能明显逊于Transformer。然而,在实践中,状态空间模型具有相当大的状态大小,我们推测它们在这些任务中的表现应该比之前报道的要好得多。我们研究了它们较差的复制和记忆性能,这可能部分是由于训练困难,而不是根本的容量限制。基于对其“注意力”图的观察,我们提出了一种结构化的初始化技术,使状态空间层更容易模仿注意力机制。在各种架构设置中,我们的初始化方法显著降低了Mamba从头开始学习复制和进行联想记忆的难度。
🔬 方法详解
问题定义:状态空间模型(SSM),如Mamba,在需要长程依赖的记忆任务中表现不如Transformer。现有研究认为这是由于SSM的状态大小固定,无法有效存储长序列信息。但作者认为,SSM的实际容量可能被低估,训练困难是导致性能瓶颈的关键因素。
核心思路:论文的核心思路是,通过一种特殊的初始化方法,使SSM的初始状态就具备模仿注意力机制的能力。这样可以引导SSM更快地学习到有效的记忆表示,从而提升其在记忆任务中的性能。这种初始化方式旨在克服训练初期的困难,使模型更容易收敛到好的局部最优解。
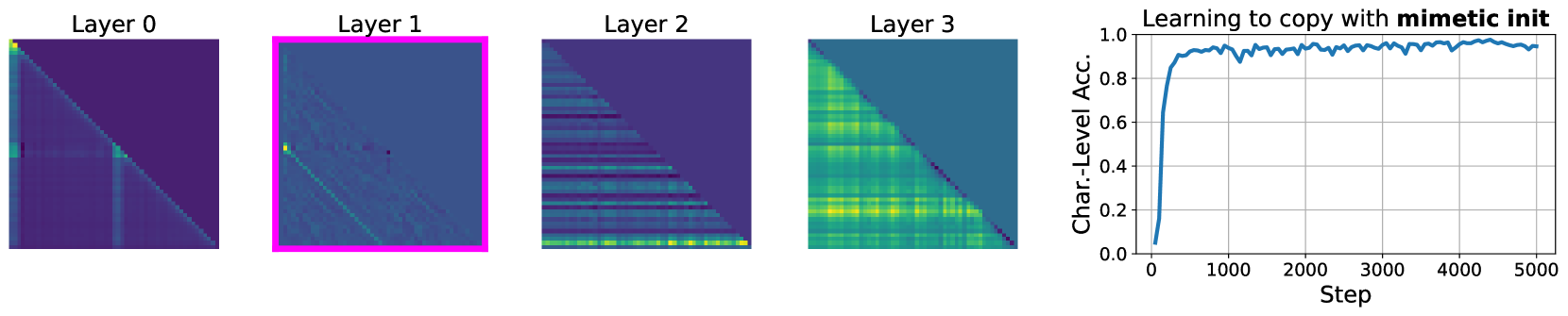
技术框架:论文主要关注Mamba架构,并提出了一种新的初始化策略。该策略的核心是模仿注意力机制的“注意力图”。具体来说,作者观察到注意力机制在记忆任务中会产生稀疏的注意力模式,即某些token会高度关注其他token。论文的目标是设计一种初始化方法,使得SSM的内部状态也能产生类似的稀疏模式。
关键创新:关键创新在于提出了一种结构化的初始化方法,该方法能够使SSM的初始状态模仿注意力机制的稀疏注意力模式。这种初始化方法不是随机的,而是基于对注意力机制的理解,有针对性地设计的。这与传统的随机初始化方法有本质区别,能够显著改善SSM的训练过程。
关键设计:具体的初始化方法涉及到对SSM内部参数的设置,使其能够产生类似注意力机制的稀疏连接。论文可能详细描述了如何根据注意力图的统计特性来设置SSM的参数,例如,如何初始化状态转移矩阵、输入矩阵和输出矩阵等。具体的损失函数和网络结构可能保持不变,重点在于初始化策略的改进。
🖼️ 关键图片


📊 实验亮点
论文通过实验验证了所提出的初始化方法在提升Mamba模型记忆能力方面的有效性。具体性能数据未知,但摘要中提到该初始化方法“显著降低了Mamba从头开始学习复制和进行联想记忆的难度”。这意味着在相同的训练条件下,使用该初始化方法的Mamba模型能够更快地收敛,并达到更高的性能水平。与随机初始化相比,该方法能够带来显著的性能提升。
🎯 应用场景
该研究成果可应用于需要长程依赖建模的序列任务,例如:自然语言处理中的长文本理解、视频分析中的动作识别、以及时间序列预测等领域。通过提升状态空间模型在记忆任务中的性能,可以降低计算成本,提高模型效率,并为开发更强大的序列建模模型奠定基础。
📄 摘要(原文)
Recent work has shown that state space models such as Mamba are significantly worse than Transformers on recall-based tasks due to the fact that their state size is constant with respect to their input sequence length. But in practice, state space models have fairly large state sizes, and we conjecture that they should be able to perform much better at these tasks than previously reported. We investigate whether their poor copying and recall performance could be due in part to training difficulties rather than fundamental capacity constraints. Based on observations of their "attention" maps, we propose a structured initialization technique that allows state space layers to more readily mimic attention. Across a variety of architecture settings, our initialization makes it substantially easier for Mamba to learn to copy and do associative recall from scratch.