Lambda-Skip Connections: the architectural component that prevents Rank Collapse
作者: Federico Arangath Joseph, Jerome Sieber, Melanie N. Zeilinger, Carmen Amo Alonso
分类: cs.LG, stat.ML
发布日期: 2024-10-14 (更新: 2025-02-13)
💡 一句话要点
提出Lambda-Skip连接,从架构层面预防序列模型中的秩崩溃问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 秩崩溃 跳跃连接 序列模型 状态空间模型 Transformer 深度学习 架构设计
📋 核心要点
- 序列模型中的秩崩溃现象会导致表达能力下降和训练不稳定,现有方法缺乏通用预防保证。
- 论文提出Lambda-Skip连接,通过参数化跳跃连接,为Transformer和SSM等架构提供秩崩溃预防的保证。
- 通过分析和实验验证了Lambda-Skip连接的有效性,并提供了预防秩崩溃的充分条件。
📝 摘要(中文)
秩崩溃是序列模型中嵌入向量快速收敛到统一token或平衡状态的现象,会导致表达能力降低和梯度消失等训练不稳定问题。经验表明,跳跃连接、LayerNorm和MLP等架构组件在缓解秩崩溃方面起关键作用。虽然该问题在Transformer中已被广泛研究,但对于新兴的状态空间模型(SSM)的类似脆弱性尚未得到充分检验。本文将秩崩溃理论从Transformer扩展到SSM,使用统一框架捕获两种架构。研究了参数化的跳跃连接版本,称为lambda-skip连接,为预防秩崩溃提供保证。通过分析结果,提出了保证所有架构预防秩崩溃的充分条件。还通过消融研究和分析实例研究了该条件的必要性。据我们所知,这是第一个提供预防秩崩溃的通用保证,并研究SSM背景下的秩崩溃的研究,为理论家和实践者提供了有价值的理解。最后,通过实验验证了跳跃连接和门控机制等架构组件在预防秩崩溃中的关键作用。
🔬 方法详解
问题定义:论文旨在解决序列模型中普遍存在的秩崩溃问题。秩崩溃指的是模型中的嵌入向量迅速收敛到一种均匀的状态,导致模型表达能力下降,梯度消失,训练不稳定。现有方法,特别是针对Transformer的,缺乏一种通用的、架构层面的解决方案,并且对于新兴的SSM模型,秩崩溃问题尚未得到充分研究。
核心思路:论文的核心思路是通过引入一种参数化的跳跃连接,即Lambda-Skip连接,来控制信息在网络中的流动,从而防止嵌入向量过快地收敛。这种方法旨在提供一种通用的解决方案,适用于包括Transformer和SSM在内的多种序列模型架构。通过理论分析,论文推导出了保证预防秩崩溃的充分条件。
技术框架:论文构建了一个统一的框架,可以同时分析Transformer和SSM两种架构中的秩崩溃现象。该框架的核心是Lambda-Skip连接,它是一种参数化的跳跃连接,允许模型学习跳跃连接的强度。整体流程包括:1)建立统一的数学模型来描述Transformer和SSM;2)引入Lambda-Skip连接;3)推导预防秩崩溃的充分条件;4)通过实验验证理论结果。
关键创新:论文的关键创新在于提出了Lambda-Skip连接,这是一种参数化的跳跃连接,可以为多种序列模型架构提供秩崩溃预防的保证。与现有方法相比,Lambda-Skip连接提供了一种更通用的、架构层面的解决方案,并且首次将秩崩溃的研究扩展到了SSM模型。此外,论文还提供了预防秩崩溃的充分条件,为模型设计提供了理论指导。
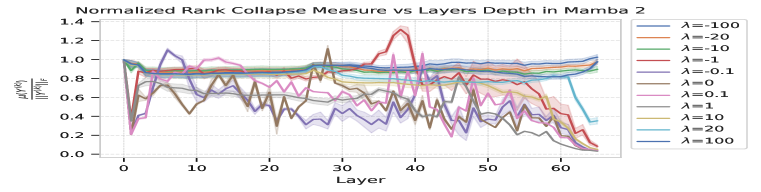
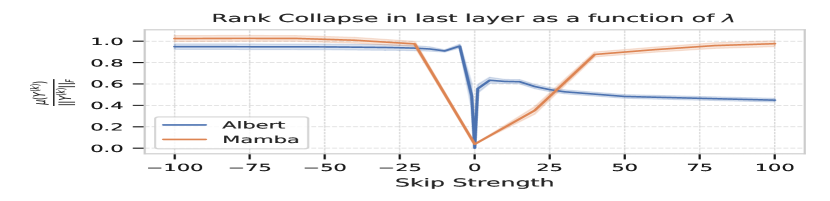
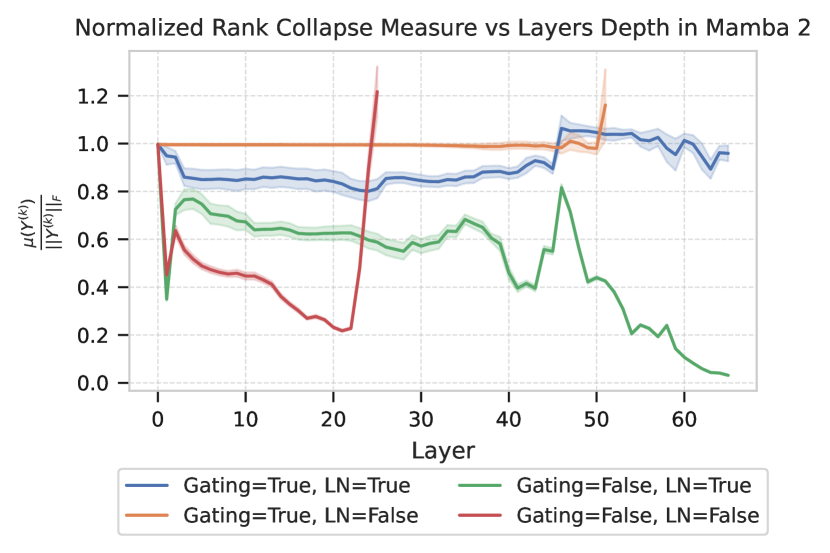
关键设计:Lambda-Skip连接的关键设计在于引入了一个可学习的参数lambda来控制跳跃连接的强度。这个参数允许模型根据任务的需要,自适应地调整跳跃连接的贡献。论文中具体分析了lambda的取值范围对秩崩溃的影响,并给出了保证预防秩崩溃的充分条件。此外,论文还通过消融实验研究了不同架构组件(如LayerNorm和MLP)对秩崩溃的影响。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了Lambda-Skip连接在预防秩崩溃方面的有效性。实验结果表明,使用Lambda-Skip连接可以显著提高模型的表达能力和训练稳定性。此外,消融实验还揭示了跳跃连接和门控机制等架构组件在预防秩崩溃中的关键作用。具体性能数据未知,但论文强调了Lambda-Skip连接相对于基线模型的提升。
🎯 应用场景
该研究成果可应用于各种序列建模任务,例如自然语言处理、语音识别、时间序列预测等。通过使用Lambda-Skip连接,可以提高模型的表达能力和训练稳定性,从而提升模型在这些任务上的性能。该研究对于设计更鲁棒、更高效的序列模型具有重要的实际价值,并可能推动相关领域的发展。
📄 摘要(原文)
Rank collapse, a phenomenon where embedding vectors in sequence models rapidly converge to a uniform token or equilibrium state, has recently gained attention in the deep learning literature. This phenomenon leads to reduced expressivity and potential training instabilities due to vanishing gradients. Empirical evidence suggests that architectural components like skip connections, LayerNorm, and MultiLayer Perceptrons (MLPs) play critical roles in mitigating rank collapse. While this issue is well-documented for transformers, alternative sequence models, such as State Space Models (SSMs), which have recently gained prominence, have not been thoroughly examined for similar vulnerabilities. This paper extends the theory of rank collapse from transformers to SSMs using a unifying framework that captures both architectures. We study how a parametrized version of the classic skip connection component, which we call \emph{lambda-skip connections}, provides guarantees for rank collapse prevention. Through analytical results, we present a sufficient condition to guarantee prevention of rank collapse across all the aforementioned architectures. We also study the necessity of this condition via ablation studies and analytical examples. To our knowledge, this is the first study that provides a general guarantee to prevent rank collapse, and that investigates rank collapse in the context of SSMs, offering valuable understanding for both theoreticians and practitioners. Finally, we validate our findings with experiments demonstrating the crucial role of architectural components such as skip connections and gating mechanisms in preventing rank collapse.