Burning RED: Unlocking Subtask-Driven Reinforcement Learning and Risk-Awareness in Average-Reward Markov Decision Processes
作者: Juan Sebastian Rojas, Chi-Guhn Lee
分类: cs.LG, cs.AI
发布日期: 2024-10-14 (更新: 2025-08-28)
备注: In Reinforcement Learning Journal 2025
💡 一句话要点
提出RED框架,解决平均奖励MDP中子任务学习和风险感知强化学习问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 平均奖励MDP 风险感知 多目标学习 条件风险价值 在线学习 差分奖励
📋 核心要点
- 现有强化学习方法主要集中于折扣MDP,而对平均奖励MDP的探索不足,限制了其在某些场景下的应用。
- 论文提出Reward-Extended Differential (RED)强化学习框架,利用平均奖励MDP的结构特性,实现多目标或子任务的同步学习。
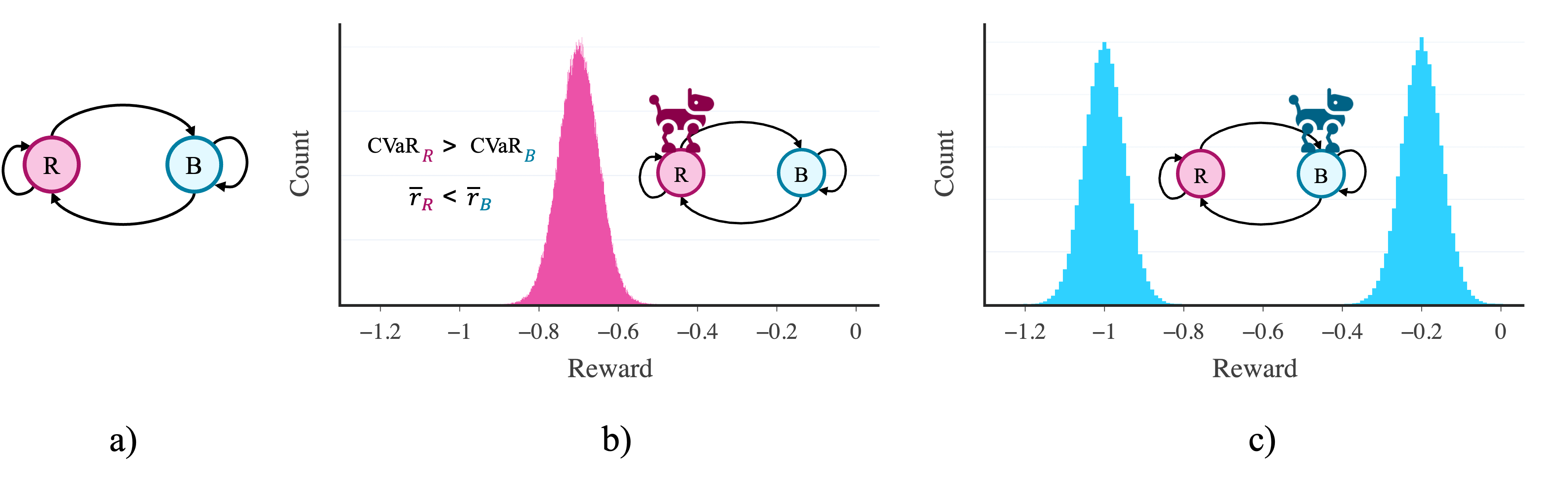
- RED框架下的算法,首次在完全在线的设置下优化了条件风险价值(CVaR)风险度量,无需复杂的双层优化或状态空间增强。
📝 摘要(中文)
平均奖励马尔可夫决策过程(MDP)为不确定性下的序贯决策提供了一个基础框架。然而,在强化学习(RL)领域,平均奖励MDP的研究在很大程度上仍未被探索,大多数基于RL的工作都集中在折扣MDP上。本文研究了平均奖励MDP的一个独特的结构属性,并利用它来引入奖励扩展差分(RED)强化学习:一种新颖的RL框架,可用于在平均奖励设置中同时有效且高效地解决各种学习目标或子任务。我们为预测和控制引入了一系列RED学习算法,包括经过验证的表格情况下的收敛算法。然后,我们通过展示这些算法如何用于首次以完全在线的方式优化众所周知的条件风险价值(CVaR)风险度量,而无需使用显式的双层优化方案或增强的状态空间,来展示这些算法的强大功能。
🔬 方法详解
问题定义:论文旨在解决平均奖励MDP中,如何高效地学习多个子任务,并同时考虑风险的问题。现有方法要么集中于折扣MDP,要么在平均奖励MDP中需要复杂的双层优化或状态空间增强来处理风险度量,计算效率较低,且难以在线学习。
核心思路:论文的核心思路是利用平均奖励MDP的特殊结构属性,设计一种新的强化学习框架RED,该框架能够同时学习多个奖励函数,并将其差分值作为学习信号,从而实现多目标学习和风险感知。通过这种方式,避免了显式的双层优化和状态空间增强,提高了学习效率。
技术框架:RED框架包含预测和控制两个部分。预测部分用于估计状态值函数和平均奖励,控制部分则利用这些估计值来更新策略。整体流程如下:首先,使用RED算法估计每个子任务的差分值函数;然后,利用这些差分值函数来构建一个策略,该策略能够平衡多个子任务的目标,并考虑风险因素;最后,通过与环境交互,不断更新值函数和策略,直至收敛。
关键创新:RED框架的关键创新在于其利用差分奖励的思想,将多个子任务的学习转化为对差分值函数的学习。这种方法避免了直接优化复杂的风险度量,而是通过学习差分值函数来间接实现风险感知。此外,RED框架能够在完全在线的环境下学习,无需离线数据或预训练。
关键设计:RED框架的关键设计包括:1) 定义了Reward-Extended Differential (RED)的概念,用于表示状态值函数相对于平均奖励的差分;2) 设计了一系列RED学习算法,包括用于预测和控制的算法,并证明了表格情况下的收敛性;3) 利用RED框架,首次实现了在平均奖励MDP中在线优化CVaR风险度量,无需显式的双层优化或增强的状态空间。
🖼️ 关键图片


📊 实验亮点
论文通过实验验证了RED框架的有效性。实验结果表明,RED算法能够在平均奖励MDP中有效地学习多个子任务,并成功地优化了CVaR风险度量。与现有方法相比,RED算法能够在完全在线的环境下学习,且无需复杂的双层优化或状态空间增强,显著提高了学习效率。
🎯 应用场景
RED框架可应用于资源分配、金融交易、机器人导航等领域,在这些场景中,需要在不确定性环境下做出序贯决策,并同时考虑多个目标和风险因素。例如,在自动驾驶中,RED可以用于同时优化行驶速度、安全性、燃油效率等多个目标,并避免高风险行为。
📄 摘要(原文)
Average-reward Markov decision processes (MDPs) provide a foundational framework for sequential decision-making under uncertainty. However, average-reward MDPs have remained largely unexplored in reinforcement learning (RL) settings, with the majority of RL-based efforts having been allocated to discounted MDPs. In this work, we study a unique structural property of average-reward MDPs and utilize it to introduce Reward-Extended Differential (or RED) reinforcement learning: a novel RL framework that can be used to effectively and efficiently solve various learning objectives, or subtasks, simultaneously in the average-reward setting. We introduce a family of RED learning algorithms for prediction and control, including proven-convergent algorithms for the tabular case. We then showcase the power of these algorithms by demonstrating how they can be used to learn a policy that optimizes, for the first time, the well-known conditional value-at-risk (CVaR) risk measure in a fully-online manner, without the use of an explicit bi-level optimization scheme or an augmented state-space.