SLaNC: Static LayerNorm Calibration
作者: Mahsa Salmani, Nikita Trukhanov, Ilya Soloveychik
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-10-14
备注: 9 pages, 3 figures, NeurIPS 2024 MLNCP Workshop
💡 一句话要点
提出静态LayerNorm校准(SLaNC)方法,解决LLM量化推理中LayerNorm计算的数值问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 量化 LayerNorm 推理优化 硬件加速
📋 核心要点
- 大型语言模型量化推理时,LayerNorm层的方差计算需要高动态范围,超出硬件能力,导致数值不稳定。
- 提出静态LayerNorm校准(SLaNC)方法,利用前置线性层的静态权重,离线计算LayerNorm输入的缩放因子。
- 该方法无需额外计算开销,即可避免推理过程中的数值问题,实现准确高效的低精度推理。
📝 摘要(中文)
随着大型语言模型(LLM)参数规模不断增长,对专用硬件加速器的需求也日益增加。为了在计算和存储受限的加速器上高效准确地处理LLM,量化技术成为研究重点。然而,低精度量化会带来数值表示范围受限的挑战。在Transformer模型硬件加速中,LayerNorm计算成为主要瓶颈,因为方差累积需要比硬件支持更大的动态范围。本文提出一种计算高效的缩放技术,可在推理期间应用于Transformer模型。该方法基于前置线性层的静态权重缩放LayerNorm输入。缩放因子离线计算,不增加推理延迟和计算开销。该技术确保计算过程中不会发生溢出或下溢等数值问题,从而在各种硬件架构上实现平滑、准确和资源高效的推理。文章提供了理论依据和数值模拟。
🔬 方法详解
问题定义:在Transformer模型的量化推理过程中,LayerNorm层的计算是性能瓶颈。由于LayerNorm需要计算输入数据的方差,而方差的累积需要比低精度量化格式所能提供的更大的动态范围。这会导致计算过程中出现溢出或下溢等数值问题,影响模型的推理精度和稳定性。现有方法通常需要引入额外的计算或存储开销来解决这个问题,例如使用更高精度的数据类型进行计算,或者采用复杂的缩放策略。
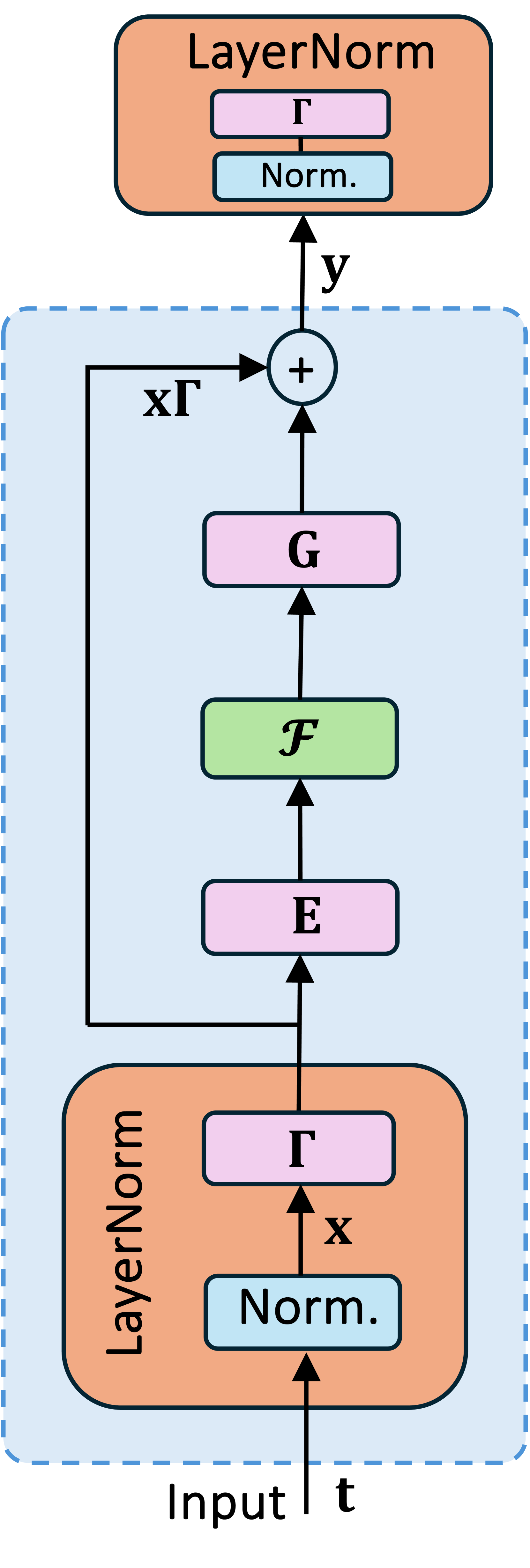
核心思路:SLaNC的核心思路是利用LayerNorm层之前的线性层的静态权重信息,预先计算出一个合适的缩放因子,用于调整LayerNorm的输入。由于线性层的权重在推理过程中是固定的,因此可以离线计算缩放因子,从而避免在推理过程中引入额外的计算开销。通过合理地选择缩放因子,可以有效地控制LayerNorm输入的数值范围,使其适应低精度量化格式的动态范围,从而避免数值问题。
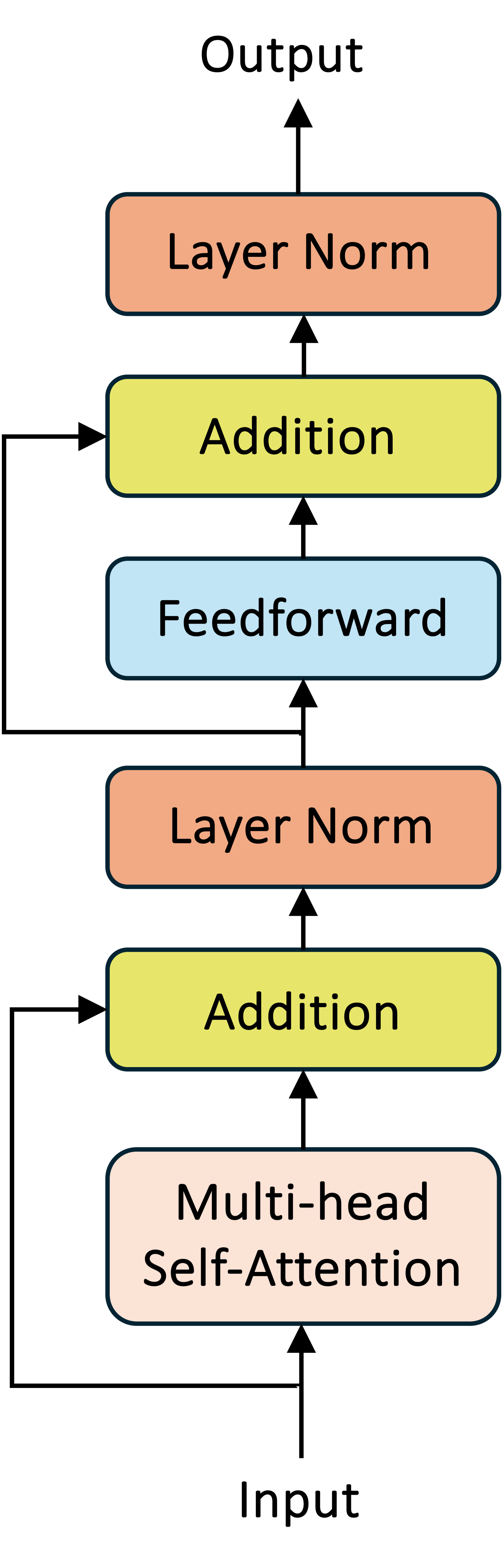
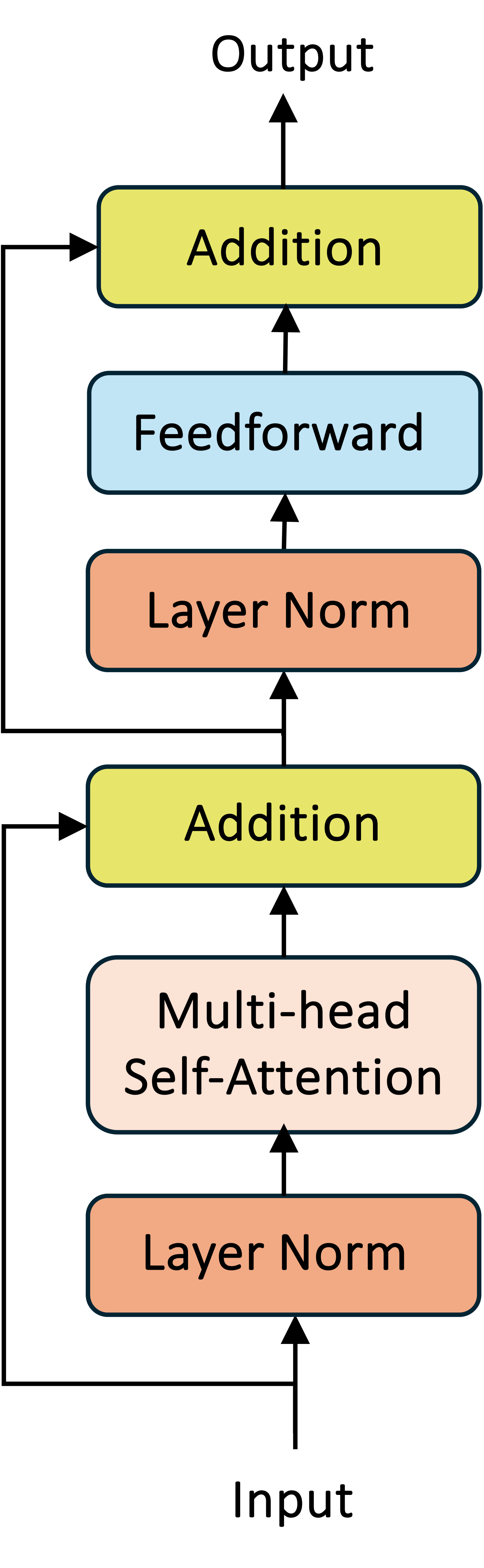
技术框架:SLaNC方法主要包含两个阶段:离线校准阶段和在线推理阶段。在离线校准阶段,首先分析Transformer模型中每个LayerNorm层之前的线性层的权重分布,然后根据权重分布计算出相应的缩放因子。在在线推理阶段,将计算得到的缩放因子应用于LayerNorm的输入,然后再进行后续的LayerNorm计算。整个过程无需修改现有的Transformer模型结构,只需要在推理过程中添加一个简单的缩放操作即可。
关键创新:SLaNC的关键创新在于利用了线性层的静态权重信息来指导LayerNorm的缩放。与传统的动态缩放方法相比,SLaNC无需在推理过程中进行额外的计算,从而降低了计算开销和延迟。此外,SLaNC方法是静态的,这意味着缩放因子在推理过程中是固定的,从而避免了动态缩放可能引入的数值不稳定问题。
关键设计:SLaNC的关键设计在于如何根据线性层的权重分布来计算缩放因子。论文中提出了一种基于权重的统计特性的计算方法,例如权重的最大值、最小值或方差。具体来说,可以根据权重的最大绝对值来确定缩放因子,使得LayerNorm的输入在经过缩放后,其绝对值不会超过低精度量化格式所能表示的最大值。此外,还可以根据权重的方差来调整缩放因子,以更好地适应不同层之间的权重分布差异。
🖼️ 关键图片
📊 实验亮点
论文通过数值模拟验证了SLaNC方法的有效性。实验结果表明,SLaNC能够在不损失推理精度的情况下,有效地避免LayerNorm计算中的数值问题。与不使用缩放的方法相比,SLaNC能够显著提高低精度量化模型的推理稳定性,并使其能够在各种硬件架构上实现平滑、准确和资源高效的推理。
🎯 应用场景
SLaNC方法可广泛应用于各种基于Transformer的大型语言模型的低精度量化推理,尤其是在资源受限的硬件平台上,如移动设备、嵌入式系统和专用加速器。该方法能够提高推理速度、降低功耗并减少存储需求,从而加速LLM在实际应用中的部署,例如智能助手、机器翻译和文本生成等。
📄 摘要(原文)
The ever increasing sizes of Large Language Models (LLMs) beyond hundreds of billions of parameters have generated enormous pressure on the manufacturers of dedicated hardware accelerators and made the innovative design of the latter one of the most rapidly expanding fields of the AI industry. Various approaches have been explored to enable efficient and accurate processing of LLMs on the available accelerators given their computational and storage limitations. Among these, various quantization techniques have become the main focus of the community as a means of reducing the compute, communication and storage requirements. Quantization to lower precision formats naturally poses a number of challenges caused by the limited range of the available value representations. When it comes to processing the popular Transformer models on hardware, one of the main issues becomes calculation of the LayerNorm simply because accumulation of the variance requires a much wider dynamic range than the hardware enables. In this article, we address this matter and propose a computationally-efficient scaling technique that can be easily applied to Transformer models during inference. Our method suggests a straightforward way of scaling the LayerNorm inputs based on the static weights of the immediately preceding linear layers. The scaling factors are computed offline, based solely on the linear layer weights, hence no latency or computational overhead is added during inference. Most importantly, our technique ensures that no numerical issues such as overflow or underflow could happen during the compute. This approach offers smooth, accurate and resource-effective inference across a wide range of hardware architectures. The article provides theoretical justification as well as supporting numerical simulations.