Model-based Large Language Model Customization as Service
作者: Zhaomin Wu, Jizhou Guo, Junyi Hou, Bingsheng He, Lixin Fan, Qiang Yang
分类: cs.LG, cs.AI, cs.CR
发布日期: 2024-10-14 (更新: 2025-10-22)
备注: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP 2025)
💡 一句话要点
Llamdex:一种基于模型上传的LLM定制服务,保护用户数据隐私
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型定制 数据隐私保护 差分隐私 模型连接 领域特定模型
📋 核心要点
- 现有LLM定制服务依赖用户上传数据微调,存在严重的数据隐私泄露风险,差分隐私数据合成方法效果不佳。
- Llamdex框架允许用户上传预训练的领域模型,通过连接模块注入LLM,无需上传敏感数据。
- 实验表明,Llamdex在保护数据隐私的同时,显著提升了LLM在特定领域的准确性,并保持了推理效率。
📝 摘要(中文)
来自OpenAI和Google等提供商的大型语言模型(LLM)服务在通用任务中表现出色,但在特定领域的应用中通常表现不佳。目前针对这些LLM的定制服务通常需要用户上传数据进行微调,这带来了严重的数据隐私风险。差分隐私(DP)数据合成是一种潜在的替代方案,但由于在数据上引入过多的噪声,其应用通常效果不佳。为了克服这个问题,我们引入了Llamdex,这是一个新颖的框架,它促进了LLM定制即服务,其中客户端上传预训练的领域特定模型而不是数据。这个客户端上传的模型,可以选择用低得多的噪声进行DP保护,通过连接模块插入到基础LLM中。重要的是,这些连接模块的训练不需要敏感的领域数据,使客户端能够在保护数据隐私的同时定制LLM服务。实验表明,在相同的隐私约束下,Llamdex在特定领域的准确性比最先进的私有数据合成方法提高了高达26%,并且由于无需用户在查询中提供领域上下文,因此保持了与原始LLM服务相当的推理效率。
🔬 方法详解
问题定义:现有LLM定制服务需要用户上传敏感数据进行微调,存在严重的数据隐私泄露风险。差分隐私数据合成虽然可以保护隐私,但由于引入了过多的噪声,导致模型在特定领域的性能显著下降。因此,如何在保护用户数据隐私的前提下,有效定制LLM以适应特定领域的需求,是一个亟待解决的问题。
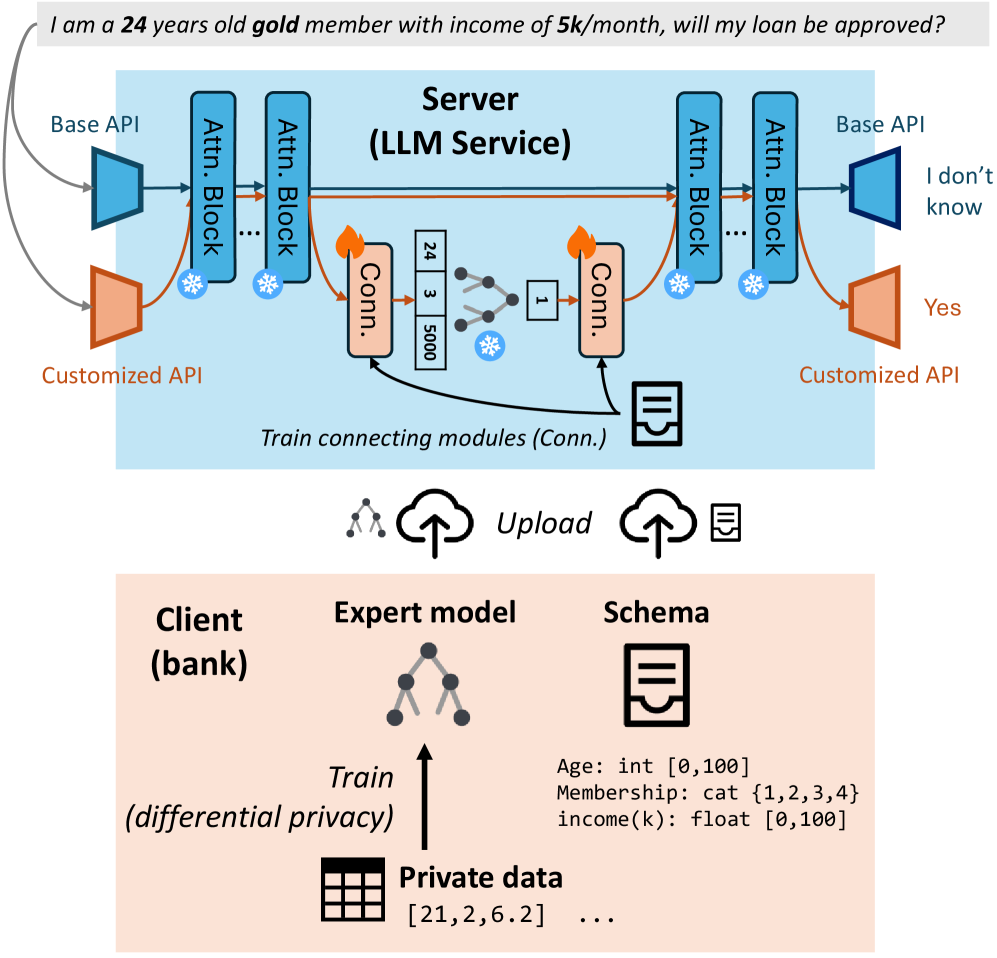
核心思路:Llamdex的核心思路是让用户上传预训练的领域特定模型,而不是原始数据。通过将用户上传的模型与基础LLM连接,实现领域知识的注入,从而避免了直接暴露用户数据。同时,连接模块的训练不需要敏感数据,进一步增强了隐私保护。
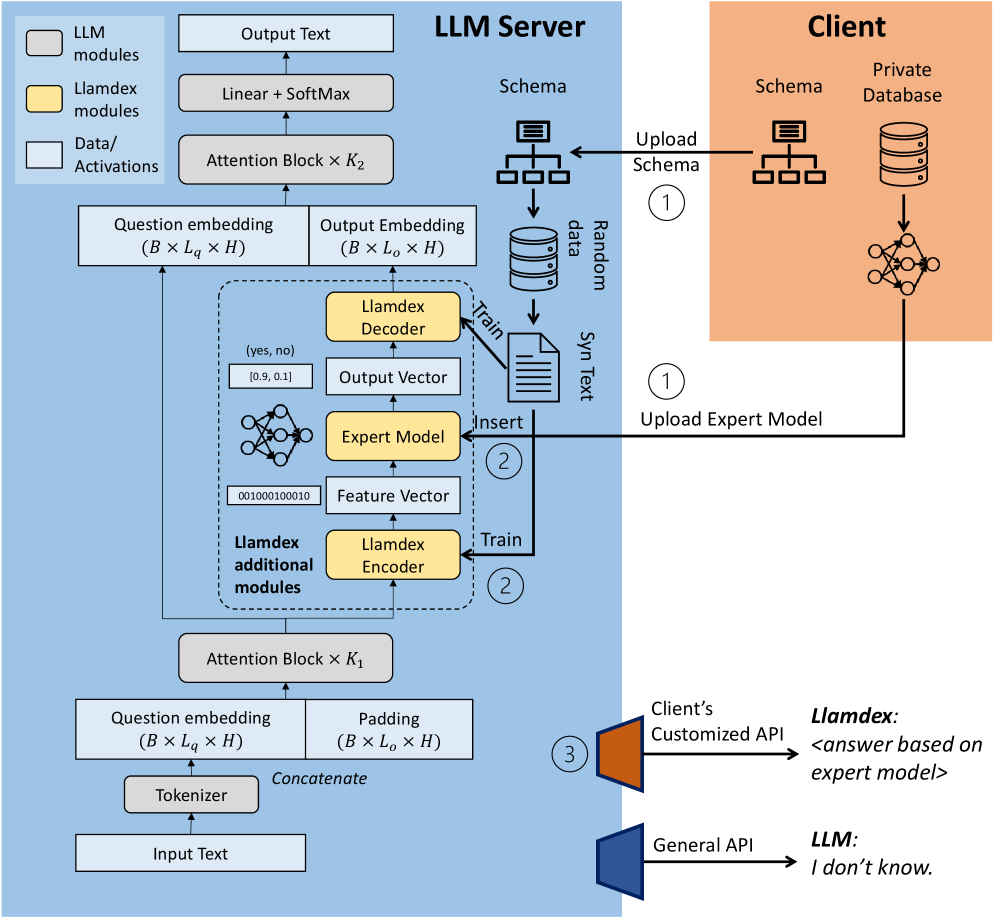
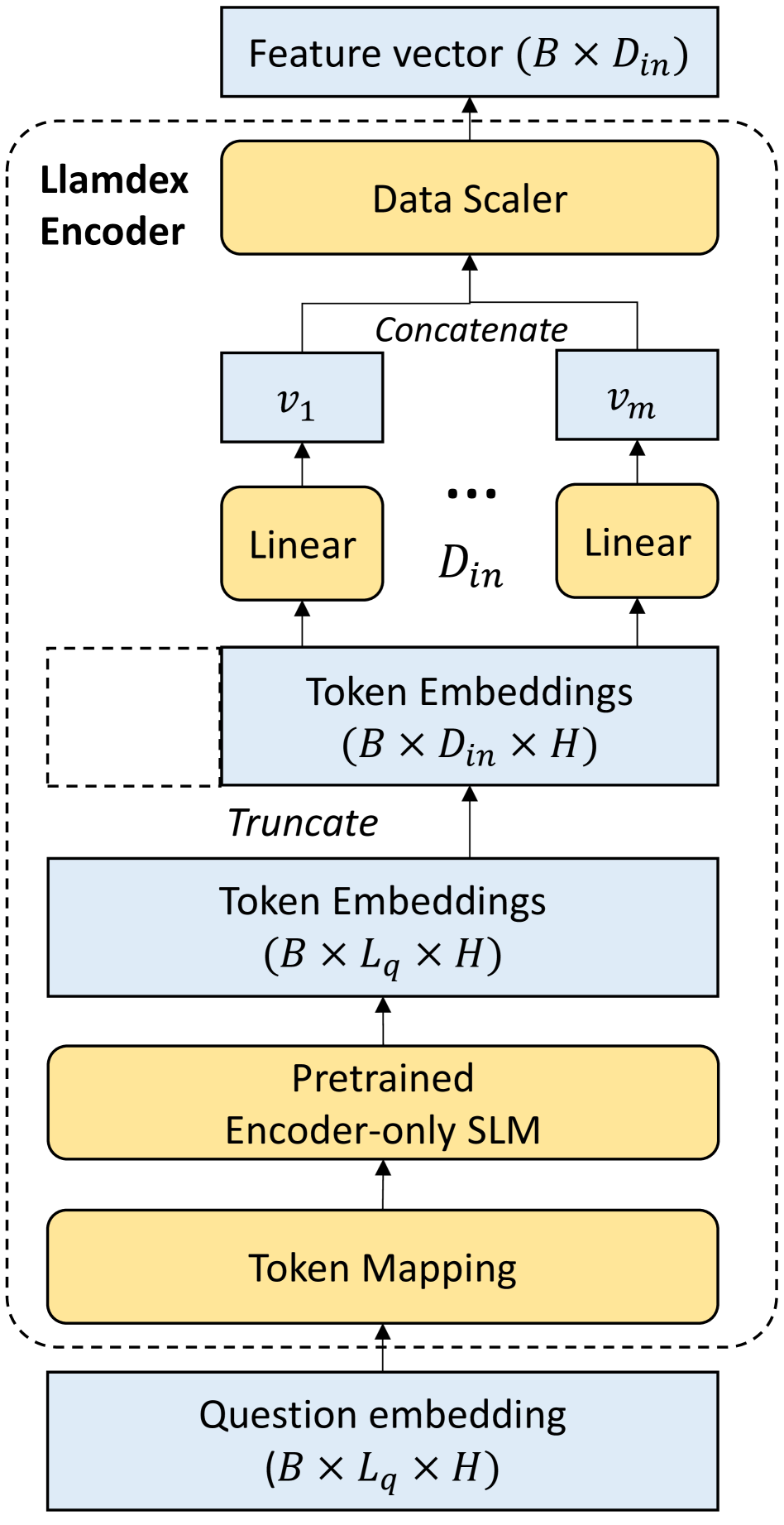
技术框架:Llamdex框架包含以下几个主要模块:1) 客户端上传预训练的领域特定模型;2) 对上传的模型进行差分隐私保护(可选),添加噪声以保护模型参数;3) 连接模块,负责将领域模型与基础LLM连接,实现知识的传递和融合;4) 训练连接模块,使用非敏感数据训练连接模块,使其能够有效地利用领域模型的知识。
关键创新:Llamdex的关键创新在于将LLM定制问题转化为模型连接问题,避免了直接使用用户数据进行微调。通过上传预训练模型,并在连接模块中进行知识融合,实现了在保护数据隐私的同时,有效提升LLM在特定领域的性能。
关键设计:Llamdex的关键设计包括:1) 连接模块的结构,需要根据基础LLM和领域模型的特点进行设计,以实现最佳的知识传递效果;2) 差分隐私保护的噪声添加策略,需要在隐私保护程度和模型性能之间进行权衡;3) 连接模块的训练数据选择,需要选择与领域相关的非敏感数据,以保证训练效果。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在相同的隐私约束下,Llamdex在特定领域的准确性比最先进的私有数据合成方法提高了高达26%。此外,Llamdex无需用户在查询中提供领域上下文,因此保持了与原始LLM服务相当的推理效率。这些结果表明,Llamdex在保护数据隐私的同时,能够有效地提升LLM在特定领域的性能。
🎯 应用场景
Llamdex可应用于金融、医疗、法律等对数据隐私要求极高的领域。例如,在金融领域,可以使用Llamdex定制LLM,使其能够理解和处理金融领域的专业术语和知识,从而提高金融风险评估、投资决策等任务的准确性。在医疗领域,可以利用Llamdex构建能够理解医学文献和病历的LLM,辅助医生进行诊断和治疗。
📄 摘要(原文)
Prominent Large Language Model (LLM) services from providers like OpenAI and Google excel at general tasks but often underperform on domain-specific applications. Current customization services for these LLMs typically require users to upload data for fine-tuning, posing significant privacy risks. While differentially private (DP) data synthesis presents a potential alternative, its application commonly results in low effectiveness due to the introduction of excessive noise on data for DP. To overcome this, we introduce Llamdex, a novel framework that facilitates LLM customization as a service, where the client uploads pre-trained domain-specific models rather than data. This client-uploaded model, optionally protected by DP with much lower noise, is inserted into the base LLM via connection modules. Significantly, these connecting modules are trained without requiring sensitive domain data, enabling clients to customize LLM services while preserving data privacy. Experiments demonstrate that Llamdex improves domain-specific accuracy by up to 26% over state-of-the-art private data synthesis methods under identical privacy constraints and, by obviating the need for users to provide domain context within queries, maintains inference efficiency comparable to the original LLM service.