Learning Linear Attention in Polynomial Time
作者: Morris Yau, Ekin Akyürek, Jiayuan Mao, Joshua B. Tenenbaum, Stefanie Jegelka, Jacob Andreas
分类: cs.LG, cs.AI, cs.CL, cs.DS
发布日期: 2024-10-14 (更新: 2025-10-23)
💡 一句话要点
提出线性注意力Transformer多项式时间可学习性理论框架,并验证其在有限自动机等任务上的有效性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 线性注意力 Transformer 可学习性 再生核希尔伯特空间 多项式时间 有限自动机 PAC学习
📋 核心要点
- Transformer模型的可学习性,特别是从数据中学习模拟器的能力,是一个重要的开放问题。
- 论文提出将线性注意力视为RKHS中的线性预测器,从而将学习线性Transformer的问题转化为学习线性预测器的问题。
- 实验验证了理论结果,表明线性注意力Transformer可以在联想记忆、有限自动机等任务上高效学习。
📝 摘要(中文)
本文研究了Transformer模型在模拟布尔电路或图灵机时的计算表达能力,并着重关注了从观测数据中学习这些模拟器的可学习性问题。研究表明,对于具有线性注意力的单层Transformer,首次实现了多项式时间可学习性(具体为强、不可知PAC学习)。线性注意力可以被视为在适当定义的再生核希尔伯特空间(RKHS)中的线性预测器。因此,学习任何线性Transformer的问题可以转化为在扩展特征空间中学习普通线性预测器的问题,并且任何这样的预测器都可以转换回多头线性Transformer。此外,论文还展示了如何有效地识别训练数据集,使得每个经验风险最小化器都等价于(在平凡对称性范围内)生成数据的线性Transformer,从而保证学习的模型可以在所有输入上正确泛化。最后,论文提供了可以通过线性注意力表达并因此可以在多项式时间内学习的计算示例,包括联想记忆、有限自动机以及一类具有多项式有界计算历史的通用图灵机(UTM)。通过在学习随机线性注意力网络、键值关联以及学习执行有限自动机三个任务上的实验验证了理论发现。研究结果弥合了Transformer理论表达能力和可学习性之间的关键差距,并表明灵活和通用的计算模型可以被有效地学习。
🔬 方法详解
问题定义:现有研究虽然探讨了Transformer的计算表达能力,但缺乏对其可学习性的深入研究,尤其是在多项式时间内从数据中学习Transformer模型的能力。现有的方法难以保证学习到的模型能够泛化到未见过的数据上,并且缺乏对学习过程的理论保证。
核心思路:论文的核心思路是将线性注意力机制与再生核希尔伯特空间(RKHS)联系起来。通过将线性注意力视为RKHS中的线性预测器,可以将学习线性Transformer的问题转化为学习线性预测器的问题。这种转化使得可以利用现有的线性学习理论来分析和保证线性Transformer的可学习性。
技术框架:论文的技术框架主要包括以下几个步骤:1) 将线性注意力机制表示为RKHS中的线性预测器;2) 将学习线性Transformer的问题转化为学习线性预测器的问题;3) 利用线性学习理论分析线性Transformer的可学习性,并证明其可以在多项式时间内学习;4) 提出一种识别训练数据集的方法,以保证学习到的模型能够泛化到未见过的数据上。
关键创新:论文最重要的技术创新点在于建立了线性注意力机制与RKHS之间的联系,从而将学习线性Transformer的问题转化为学习线性预测器的问题。这种转化使得可以利用现有的线性学习理论来分析和保证线性Transformer的可学习性,从而解决了现有方法缺乏理论保证的问题。
关键设计:论文的关键设计包括:1) 使用再生核希尔伯特空间(RKHS)来表示线性注意力机制;2) 设计了一种损失函数,用于训练线性Transformer模型;3) 提出了一种识别训练数据集的方法,以保证学习到的模型能够泛化到未见过的数据上。具体的参数设置和网络结构取决于具体的任务和数据集。
🖼️ 关键图片
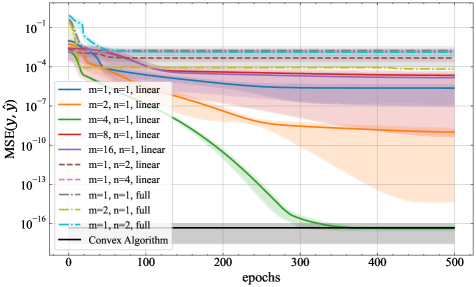
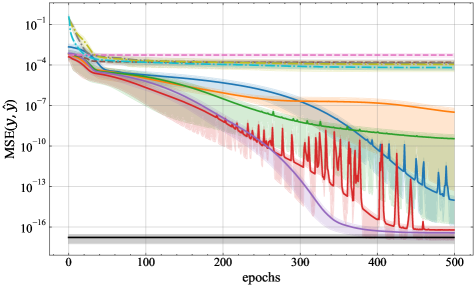
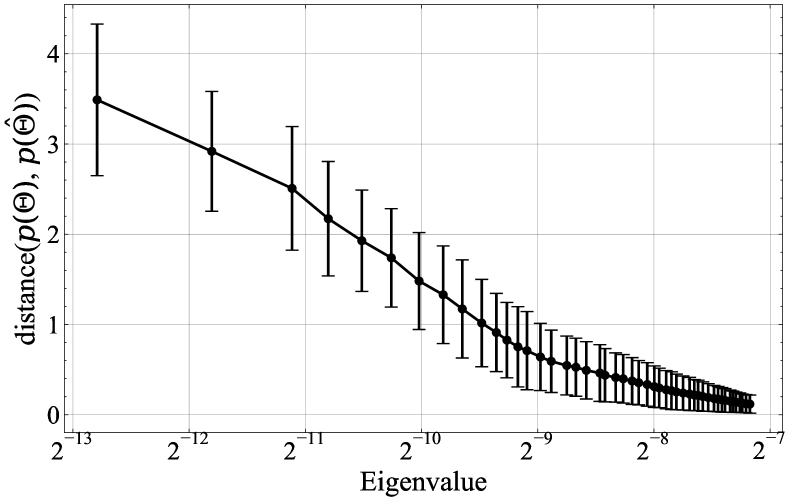
📊 实验亮点
论文通过实验验证了理论结果,在学习随机线性注意力网络、键值关联以及学习执行有限自动机三个任务上取得了良好的效果。实验结果表明,线性注意力Transformer可以在多项式时间内学习到有效的模型,并且能够泛化到未见过的数据上。这些实验结果为该研究的理论贡献提供了有力的支持。
🎯 应用场景
该研究成果可应用于各种需要高效学习和泛化的任务,例如自然语言处理、计算机视觉和机器人控制等领域。特别是在资源受限的环境下,多项式时间可学习性保证了模型能够在合理的时间内学习到有效的策略。此外,该研究为理解和设计更高效、更可解释的Transformer模型提供了理论基础。
📄 摘要(原文)
Previous research has explored the computational expressivity of Transformer models in simulating Boolean circuits or Turing machines. However, the learnability of these simulators from observational data has remained an open question. Our study addresses this gap by providing the first polynomial-time learnability results (specifically strong, agnostic PAC learning) for single-layer Transformers with linear attention. We show that linear attention may be viewed as a linear predictor in a suitably defined RKHS. As a consequence, the problem of learning any linear transformer may be converted into the problem of learning an ordinary linear predictor in an expanded feature space, and any such predictor may be converted back into a multiheaded linear transformer. Moving to generalization, we show how to efficiently identify training datasets for which every empirical risk minimizer is equivalent (up to trivial symmetries) to the linear Transformer that generated the data, thereby guaranteeing the learned model will correctly generalize across all inputs. Finally, we provide examples of computations expressible via linear attention and therefore polynomial-time learnable, including associative memories, finite automata, and a class of Universal Turing Machine (UTMs) with polynomially bounded computation histories. We empirically validate our theoretical findings on three tasks: learning random linear attention networks, key--value associations, and learning to execute finite automata. Our findings bridge a critical gap between theoretical expressivity and learnability of Transformers, and show that flexible and general models of computation are efficiently learnable.