DeepOSets: Non-Autoregressive In-Context Learning with Permutation-Invariance Inductive Bias
作者: Shao-Ting Chiu, Junyuan Hong, Ulisses Braga-Neto
分类: cs.LG
发布日期: 2024-10-11 (更新: 2025-10-30)
备注: Set transformer results in the high-dimensional (d=20) case were added; there is a revised proof of Theorem 1; minor edits were made throughout
💡 一句话要点
提出DeepOSets以解决非自回归上下文学习问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 非自回归 置换不变性 深度学习 回归分析 算子学习 高维数据 模型压缩
📋 核心要点
- 现有方法主要依赖自回归变换器的注意力机制,限制了上下文学习的灵活性和应用范围。
- DeepOSets通过引入硬编码的置换不变性归纳偏置,实现了在非自回归架构中进行上下文学习的能力。
- 实验结果表明,DeepOSets在高维情况下的准确性显著提高,且参数量比传统变换器减少了一个数量级。
📝 摘要(中文)
上下文学习(ICL)是某些机器学习模型在用户提示中通过示例学习的能力,而无需更新模型参数。最初在大型语言模型中观察到ICL,普遍认为其源于自回归变换器中的注意力机制。本文通过风格化回归学习任务,展示了ICL可以在具有硬编码置换不变性归纳偏置的非自回归神经架构中出现。我们提出的DeepOSets架构结合了DeepSets的集合学习特性与Deep Operator Networks的算子学习能力。我们提供了置换不变回归学习算子的表示定理,并证明DeepOSets是该类算子的通用逼近器。通过全面的数值实验,我们评估了DeepOSets在不同噪声水平、维度和样本大小下学习线性、多项式和浅层神经网络回归的能力。
🔬 方法详解
问题定义:本文旨在解决上下文学习在非自回归神经网络中的实现问题。现有方法通常依赖自回归架构,导致灵活性不足和参数效率低下。
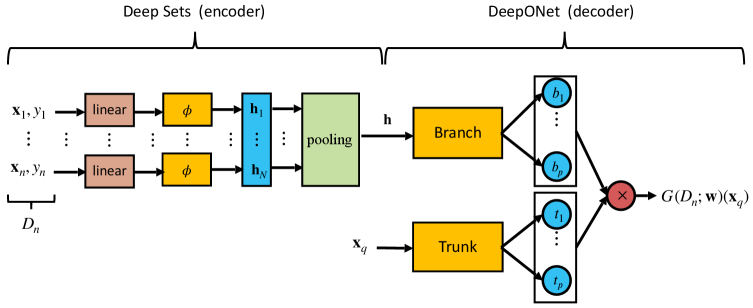
核心思路:提出DeepOSets架构,结合DeepSets的集合学习特性与DeepONets的算子学习能力,通过硬编码置换不变性归纳偏置,使得模型能够在非自回归环境中进行有效的上下文学习。
技术框架:DeepOSets的整体架构包括输入层、置换不变性模块和输出层。输入层接收样本数据,置换不变性模块负责处理输入的排列组合,输出层生成最终的回归结果。
关键创新:DeepOSets的主要创新在于其能够在非自回归架构中实现上下文学习,打破了传统自回归模型的限制,且在参数效率上表现优异。
关键设计:模型设计中使用了置换不变性损失函数,确保模型对输入顺序的鲁棒性。此外,DeepSets层被Set Transformer替代,以提高高维情况下的学习能力。
🖼️ 关键图片
📊 实验亮点
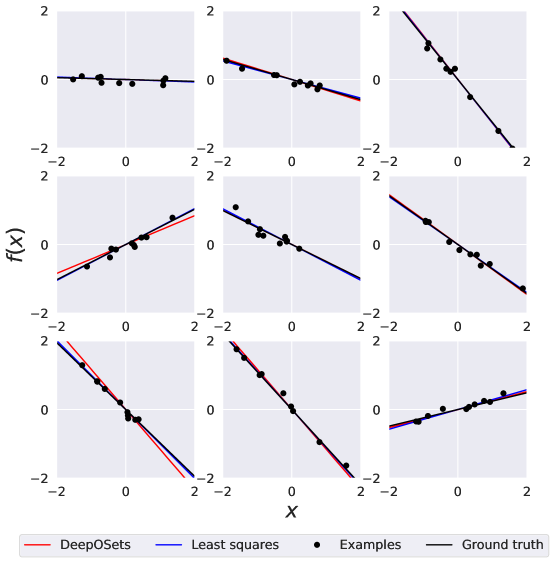
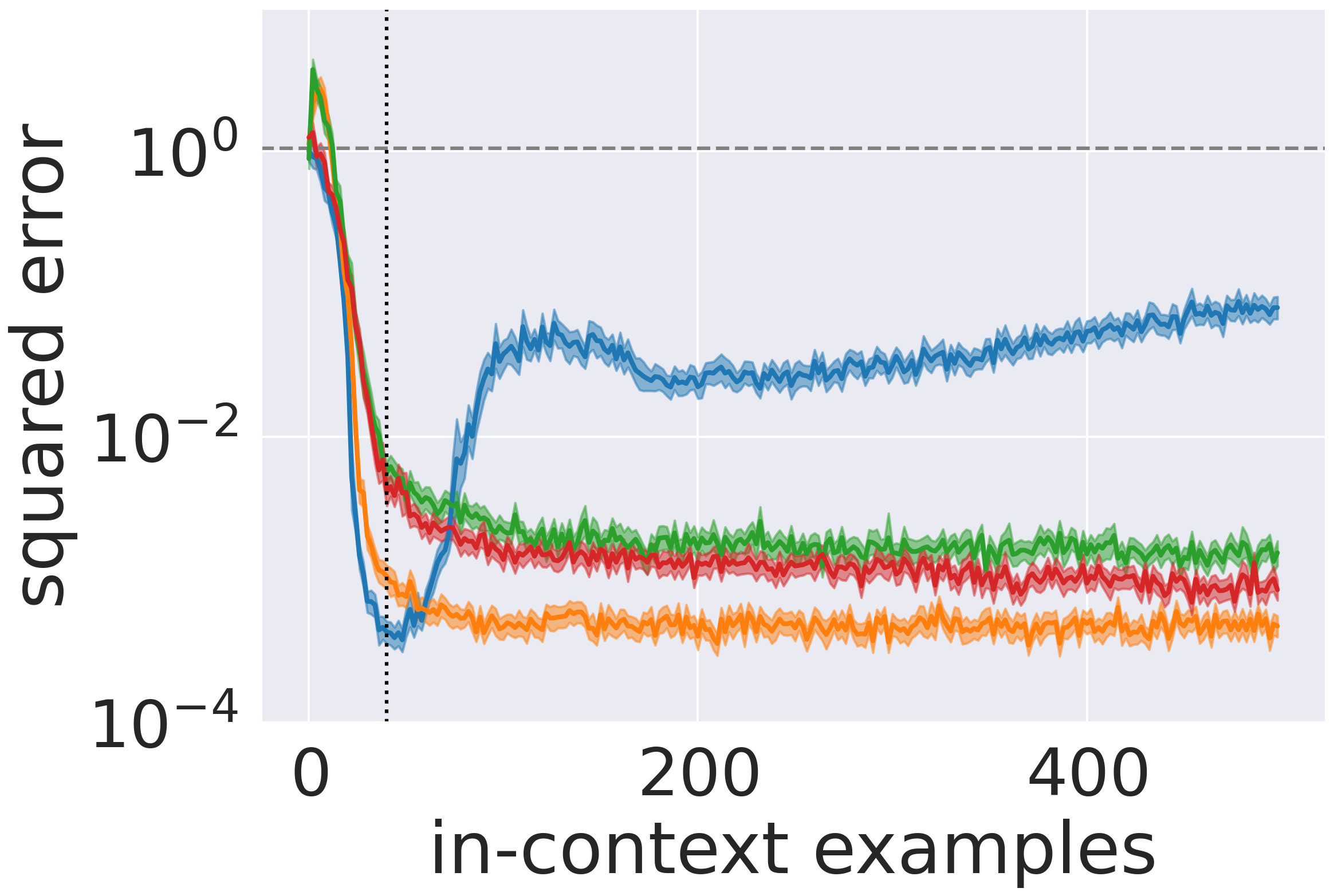
实验结果显示,DeepOSets在学习线性、多项式和浅层神经网络回归任务时,准确性显著提高。在高维情况下,使用Set Transformer替代DeepSets层后,模型的性能提升了一个数量级,同时参数量比传统变换器减少了十倍。
🎯 应用场景
DeepOSets在多个领域具有潜在应用价值,包括金融预测、医疗数据分析和科学计算等。其高效的上下文学习能力能够帮助模型在数据稀缺或高维情况下进行准确预测,未来可能推动更多非自回归模型的研究与应用。
📄 摘要(原文)
In-context learning (ICL) is the remarkable ability displayed by some machine learning models to learn from examples provided in a user prompt without any model parameter updates. ICL was first observed in the domain of large language models, and it has been widely assumed that it is a product of the attention mechanism in autoregressive transformers. In this paper, using stylized regression learning tasks, we demonstrate that ICL can emerge in a non-autoregressive neural architecture with a hard-coded permutation-invariance inductive bias. This novel architecture, called DeepOSets, combines the set learning properties of the DeepSets architecture with the operator learning capabilities of Deep Operator Networks (DeepONets). We provide a representation theorem for permutation-invariant regression learning operators and prove that DeepOSets are universal approximators of this class of operators. We performed comprehensive numerical experiments to evaluate the capabilities of DeepOSets in learning linear, polynomial, and shallow neural network regression, under varying noise levels, dimensionalities, and sample sizes. In the high-dimensional regime, accuracy was enhanced by replacing the DeepSets layer with a Set Transformer. Our results show that DeepOSets deliver accurate and fast results with an order of magnitude fewer parameters than a comparable transformer-based alternative.