Benchmark Inflation: Revealing LLM Performance Gaps Using Retro-Holdouts
作者: Jacob Haimes, Cenny Wenner, Kunvar Thaman, Vassil Tashev, Clement Neo, Esben Kran, Jason Schreiber
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-10-11
💡 一句话要点
提出Retro-Holdouts方法,揭示LLM在TruthfulQA上的benchmark膨胀问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 基准测试 数据污染 性能评估 Retro-Holdouts
📋 核心要点
- 现有LLM基准测试易受训练数据污染,导致模型在公开数据集上表现虚高,无法真实反映模型能力。
- 论文提出Retro-Holdouts方法,通过回顾性构建与原始数据集统计不可区分的holdout集,评估模型真实性能。
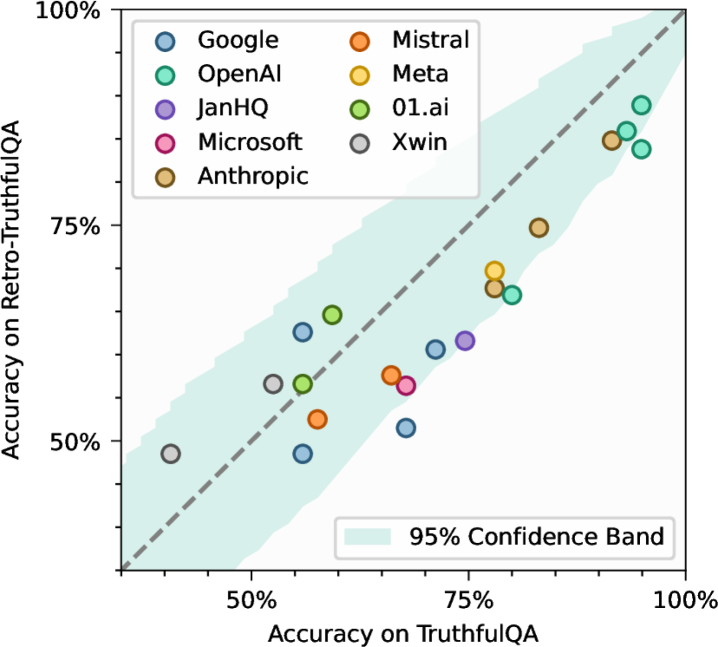
- 实验表明,部分LLM在TruthfulQA上的分数膨胀高达16个百分点,验证了该方法有效性,并揭示了benchmark的局限性。
📝 摘要(中文)
许多大型语言模型(LLM)的训练数据被测试数据污染。这意味着用于评估LLM的公共基准测试受到了损害,表明基准分数与实际能力之间存在性能差距。理想情况下,可以使用私有holdout集来准确验证分数。不幸的是,对于大多数基准测试来说,这种数据集并不存在,并且事后构建足够相似的数据集并非易事。为了解决这些问题,我们引入了一种系统的方法,用于(i)回顾性地构建目标数据集的holdout数据集,(ii)证明该retro-holdout数据集的统计不可区分性,以及(iii)比较两个数据集上的LLM,以量化由于数据集的公开可用性而导致的性能差距。将这些方法应用于TruthfulQA,我们构建并发布了Retro-Misconceptions,我们在其上评估了20个LLM,发现一些LLM的分数膨胀了高达16个百分点。我们的结果表明,公共基准分数并不总是能准确评估模型属性,并强调了改进该领域数据实践的重要性。
🔬 方法详解
问题定义:论文旨在解决LLM在公共基准测试中性能虚高的问题。由于训练数据污染,LLM可能记忆了测试集,导致在benchmark上表现优异,但实际能力并未相应提升。现有方法缺乏有效的私有holdout集来评估模型的真实泛化能力,且重新构建相似数据集成本高昂。
核心思路:论文的核心思路是回顾性地构建一个与原始数据集统计上不可区分的holdout集,称为Retro-Holdout。通过比较模型在原始数据集和Retro-Holdout上的表现,可以量化由于数据污染导致的性能膨胀。这种方法无需重新收集数据,而是利用现有数据生成更可靠的评估集。
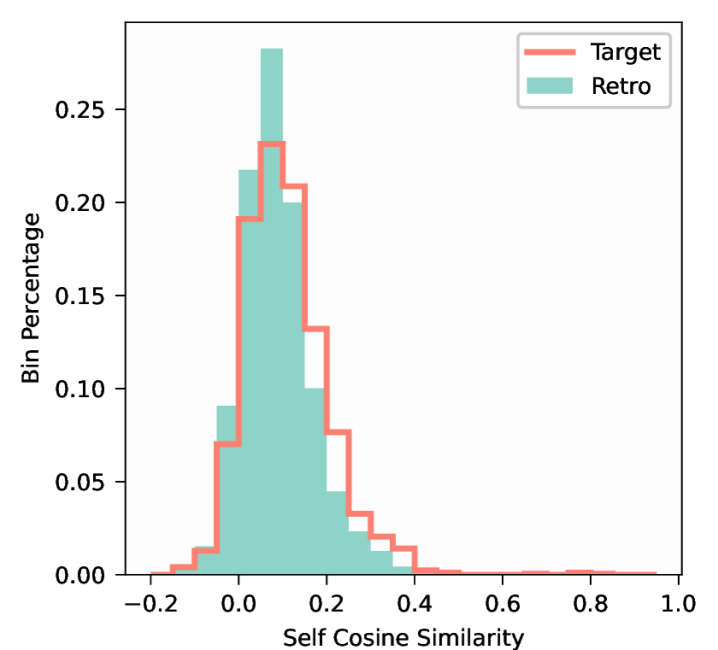
技术框架:该方法包含三个主要步骤:1) Retro-Holdout构建:从原始数据集中选择一部分样本,并进行轻微修改,使其在语义上与原始数据集相似,但在字面上有所不同。2) 统计不可区分性验证:使用统计检验方法(如最大平均差异MMD)验证Retro-Holdout与原始数据集在统计分布上是否相似,确保模型无法轻易区分两者。3) 性能评估与差距量化:在原始数据集和Retro-Holdout上评估LLM的性能,并计算两者之间的性能差距,以此量化数据污染导致的性能膨胀。
关键创新:该方法最重要的创新在于其回顾性构建holdout集的能力。与传统的holdout集不同,Retro-Holdout是在已知原始数据集的情况下构建的,因此需要确保其与原始数据集在统计上不可区分。这种方法避免了重新收集数据的成本,并提供了一种量化数据污染影响的有效途径。
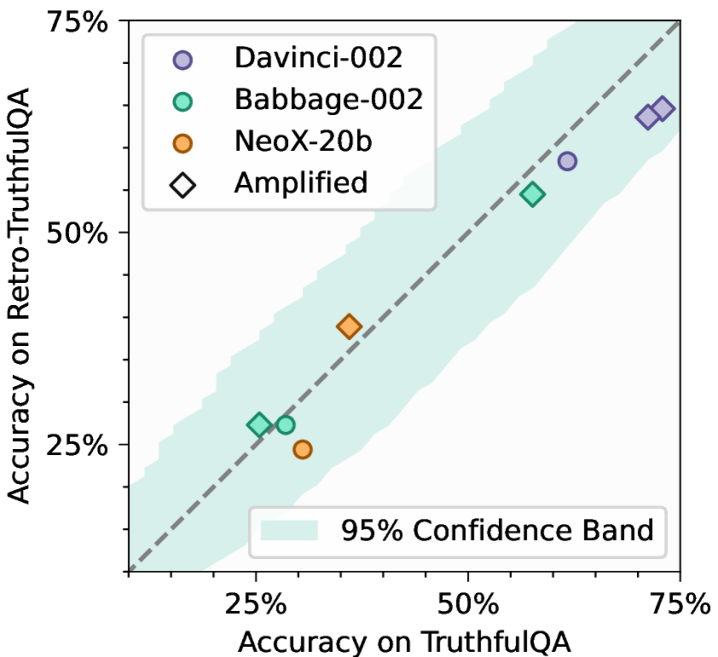
关键设计:在TruthfulQA数据集上,论文构建了Retro-Misconceptions数据集。关键设计包括:1) 使用基于规则的方法修改原始问题,例如替换关键词或改变句子结构,以生成新的问题。2) 使用MMD检验确保Retro-Misconceptions与TruthfulQA在统计分布上相似。3) 使用准确率作为评估指标,比较LLM在两个数据集上的表现。
🖼️ 关键图片
📊 实验亮点
实验结果表明,部分LLM在TruthfulQA上的准确率高达70%以上,但在Retro-Misconceptions上的准确率下降至54%左右,性能差距高达16个百分点。这表明公共benchmark分数存在显著的膨胀现象。实验对比了20个LLM,揭示了不同模型受数据污染影响的程度差异。
🎯 应用场景
该研究成果可应用于LLM的公平评估和模型选择。通过构建Retro-Holdouts,可以更准确地评估LLM的真实能力,避免因数据污染而选择性能虚高的模型。该方法还可用于检测和缓解训练数据中的污染问题,提高LLM的鲁棒性和可靠性。未来,该方法可推广到其他NLP任务和数据集,促进更可靠的AI模型开发。
📄 摘要(原文)
The training data for many Large Language Models (LLMs) is contaminated with test data. This means that public benchmarks used to assess LLMs are compromised, suggesting a performance gap between benchmark scores and actual capabilities. Ideally, a private holdout set could be used to accurately verify scores. Unfortunately, such datasets do not exist for most benchmarks, and post-hoc construction of sufficiently similar datasets is non-trivial. To address these issues, we introduce a systematic methodology for (i) retrospectively constructing a holdout dataset for a target dataset, (ii) demonstrating the statistical indistinguishability of this retro-holdout dataset, and (iii) comparing LLMs on the two datasets to quantify the performance gap due to the dataset's public availability. Applying these methods to TruthfulQA, we construct and release Retro-Misconceptions, on which we evaluate twenty LLMs and find that some have inflated scores by as much as 16 percentage points. Our results demonstrate that public benchmark scores do not always accurately assess model properties, and underscore the importance of improved data practices in the field.