Zeroth-Order Fine-Tuning of LLMs in Random Subspaces
作者: Ziming Yu, Pan Zhou, Sike Wang, Jia Li, Mi Tian, Hua Huang
分类: cs.LG, cs.AI
发布日期: 2024-10-11 (更新: 2025-07-24)
备注: ICCV 2025 camera-ready version
🔗 代码/项目: GITHUB
💡 一句话要点
提出SubZero:一种随机子空间零阶优化方法,用于高效微调大型语言模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 零阶优化 随机子空间 低秩扰动 模型微调
📋 核心要点
- 大型语言模型微调面临内存瓶颈,传统反向传播对算力要求高,零阶优化虽内存效率高,但梯度方差随模型维度线性增长。
- SubZero方法通过引入低秩扰动,在随机子空间中进行零阶优化,降低梯度方差,减少内存消耗,提升训练效率。
- 实验证明,SubZero在多种语言建模任务上,相较于MeZO等标准零阶优化方法,实现了更快的收敛速度和更好的微调性能。
📝 摘要(中文)
微调大型语言模型(LLMs)已被证明对各种下游任务有效。然而,随着LLMs规模的增长,反向传播的内存需求变得越来越高。零阶(ZO)优化方法通过使用前向传递来估计梯度,提供了一种内存高效的替代方案,但梯度估计的方差通常与模型的参数维度线性相关——这是LLMs的一个重大问题。在本文中,我们提出了随机子空间零阶(SubZero)优化,以解决LLMs高维度带来的挑战。我们引入了一种为LLMs量身定制的低秩扰动,它显著降低了内存消耗,同时提高了训练性能。此外,我们证明了我们的梯度估计与反向传播梯度非常接近,比传统的ZO方法表现出更低的方差,并确保与SGD结合时的收敛性。实验结果表明,SubZero增强了微调性能,并且在各种语言建模任务中,与标准ZO方法(如MeZO)相比,实现了更快的收敛速度。代码可在https://github.com/zimingyy/SubZero获取。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)微调过程中,由于模型参数量巨大导致的反向传播内存需求过高的问题。现有的零阶优化方法虽然能降低内存需求,但其梯度估计的方差会随着模型维度线性增长,导致训练不稳定和收敛速度慢。
核心思路:论文的核心思路是在随机子空间中进行零阶优化,通过低秩扰动来降低梯度估计的方差。具体来说,不是在整个参数空间进行梯度估计,而是在一个随机选择的低维子空间中进行,从而减少了需要估计的参数数量,降低了方差。
技术框架:SubZero方法主要包含以下几个步骤:1. 随机选择一个低维子空间。2. 在该子空间中对模型参数进行低秩扰动。3. 使用零阶优化方法(例如,通过前向传播估计梯度)在该子空间中更新模型参数。4. 将更新后的参数映射回原始参数空间。这个过程迭代进行,直到模型收敛。
关键创新:SubZero的关键创新在于将零阶优化与随机子空间方法相结合,并引入了针对LLMs的低秩扰动。这种方法有效地降低了梯度估计的方差,同时减少了内存消耗。与传统的零阶优化方法相比,SubZero能够在高维参数空间中更稳定、更高效地进行训练。
关键设计:SubZero的关键设计包括:1. 低秩扰动的具体形式,需要根据LLMs的特点进行设计,以保证扰动后的模型性能不会显著下降。2. 随机子空间的选择策略,需要平衡计算复杂度和梯度估计的准确性。3. 零阶优化器的选择,可以选择不同的零阶优化算法,例如MeZO等。4. 子空间的维度大小,需要根据具体的模型和任务进行调整,以达到最佳的性能。
🖼️ 关键图片
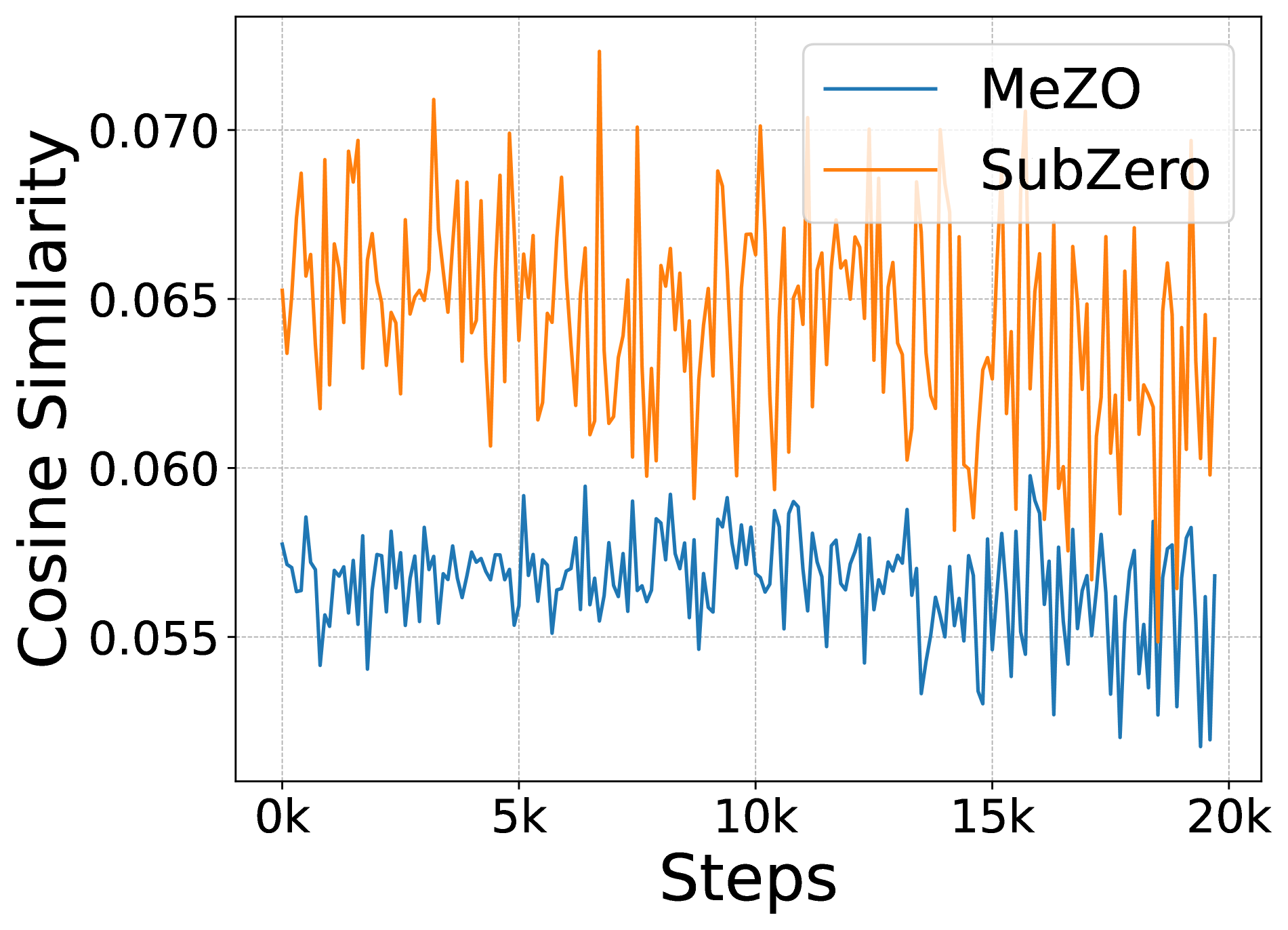


📊 实验亮点
实验结果表明,SubZero方法在各种语言建模任务上,相较于标准零阶优化方法(如MeZO),实现了更快的收敛速度和更好的微调性能。具体而言,SubZero在保持甚至提升模型性能的同时,显著降低了内存消耗,使得在有限的计算资源下微调大型语言模型成为可能。
🎯 应用场景
SubZero方法可广泛应用于各种需要微调大型语言模型的场景,例如自然语言处理、文本生成、机器翻译等。该方法降低了微调LLM的计算资源需求,使得在资源受限的环境下也能进行高效的模型微调,加速LLM在各领域的应用。
📄 摘要(原文)
Fine-tuning Large Language Models (LLMs) has proven effective for a variety of downstream tasks. However, as LLMs grow in size, the memory demands for backpropagation become increasingly prohibitive. Zeroth-order (ZO) optimization methods offer a memory-efficient alternative by using forward passes to estimate gradients, but the variance of gradient estimates typically scales linearly with the model's parameter dimension$\unicode{x2013}$a significant issue for LLMs. In this paper, we propose the random Subspace Zeroth-order (SubZero) optimization to address the challenges posed by LLMs' high dimensionality. We introduce a low-rank perturbation tailored for LLMs that significantly reduces memory consumption while improving training performance. Additionally, we prove that our gradient estimation closely approximates the backpropagation gradient, exhibits lower variance than traditional ZO methods, and ensures convergence when combined with SGD. Experimental results show that SubZero enhances fine-tuning performance and achieves faster convergence compared to standard ZO approaches like MeZO across various language modeling tasks. Code is available at https://github.com/zimingyy/SubZero.