Overcoming Slow Decision Frequencies in Continuous Control: Model-Based Sequence Reinforcement Learning for Model-Free Control
作者: Devdhar Patel, Hava Siegelmann
分类: cs.LG, cs.AI
发布日期: 2024-10-11 (更新: 2025-07-26)
备注: 30 pages, 14 figures, 7 tables. Presented at the Thirteenth International Conference on Learning Representations (ICLR 2025), Singapore, April 24-28, 2025
💡 一句话要点
提出序列强化学习(SRL),解决连续控制中低决策频率下的控制难题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 序列强化学习 低频控制 连续控制 模型辅助 Actor-Critic 时间回溯 机器人控制
📋 核心要点
- 现有强化学习算法需要极高的决策频率,这在现实世界应用中构成挑战,限制了其应用范围。
- SRL算法通过生成动作序列,并结合模型和Actor-Critic架构,实现在低决策频率下的有效控制。
- 实验表明,SRL在连续控制任务中表现出色,并引入频率平均分数(FAS)指标来评估不同决策频率下的性能。
📝 摘要(中文)
强化学习(RL)在控制能力上正迅速达到甚至超越人类水平。然而,最先进的RL算法通常需要比人类能力快得多的时间步长和反应时间,这在现实环境中是不切实际的,并且通常需要专门的硬件。我们引入序列强化学习(SRL),这是一种RL算法,旨在为给定的输入状态生成一系列动作,从而能够在较低的决策频率下进行有效的控制。SRL通过采用在不同时间尺度上运行的模型和Actor-Critic架构来解决学习动作序列的挑战。我们提出了一种“时间回溯”机制,其中Critic使用模型来估计原始动作之间的中间状态,为序列中的每个单独动作提供学习信号。一旦训练完成,Actor可以独立于模型生成动作序列,从而以较低的频率实现无模型的控制。我们在一套连续控制任务上评估SRL,证明它在显著降低Actor样本复杂度的同时,实现了与最先进算法相当的性能。为了更好地评估不同决策频率下的性能,我们引入了频率平均分数(FAS)指标。我们的结果表明,SRL在FAS方面显著优于传统的RL算法,使其特别适用于需要可变决策频率的应用。此外,我们将SRL与基于模型的在线规划进行比较,表明SRL在利用在线规划器在训练期间使用的相同模型的同时,实现了相当的FAS。
🔬 方法详解
问题定义:现有强化学习算法在连续控制任务中,通常需要非常高的决策频率才能达到良好的控制效果。这在实际应用中,例如机器人控制等场景,由于硬件限制或环境交互的固有延迟,难以满足。因此,如何在低决策频率下实现高效的连续控制是一个关键问题。现有方法的痛点在于,要么需要昂贵的硬件支持,要么在低频控制下性能显著下降。
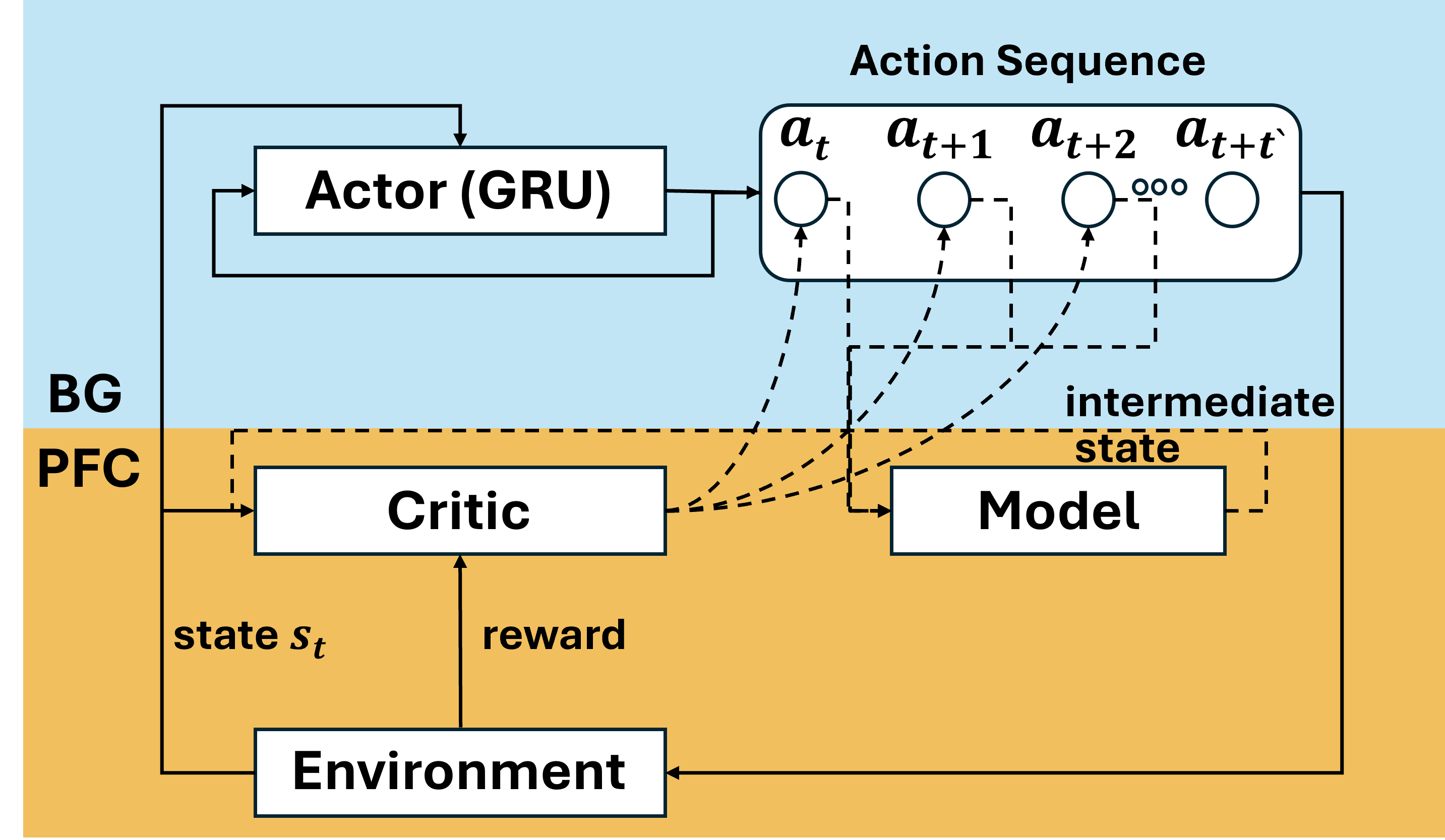
核心思路:SRL的核心思路是将单个动作扩展为动作序列,从而降低决策频率。通过学习生成一系列动作,Actor可以在更长的时间跨度内影响环境,而无需频繁地进行决策。此外,SRL利用一个模型来辅助训练,Critic通过该模型估计动作序列中的中间状态,为每个动作提供更丰富的学习信号。训练完成后,Actor可以独立于模型运行,实现无模型的低频控制。
技术框架:SRL的整体架构包含一个Actor、一个Critic和一个环境模型。Actor负责生成动作序列,Critic评估动作序列的价值,环境模型用于估计动作序列执行过程中的中间状态。训练过程如下:1) Actor根据当前状态生成一个动作序列;2) 环境执行该动作序列;3) Critic使用环境模型估计动作序列执行过程中的中间状态,并计算TD误差;4) Actor和Critic根据TD误差进行更新。训练完成后,Actor可以独立运行,直接生成动作序列进行控制。
关键创新:SRL的关键创新在于“时间回溯”机制和模型辅助训练。时间回溯机制允许Critic利用环境模型来估计动作序列中的中间状态,从而为每个动作提供更精细的奖励信号。这种机制解决了在低频决策下,奖励信号稀疏的问题。模型辅助训练则允许Actor在训练阶段利用模型进行探索,提高训练效率,并在训练完成后实现无模型的控制。
关键设计:SRL的关键设计包括:1) 动作序列的长度:需要根据具体任务进行调整,以平衡决策频率和控制精度;2) 环境模型的选择:可以使用已知的环境动力学模型,也可以通过学习得到;3) Critic的网络结构:需要能够处理动作序列和中间状态的信息;4) 损失函数:通常使用TD误差作为Critic的损失函数,并使用策略梯度方法更新Actor。
🖼️ 关键图片
📊 实验亮点
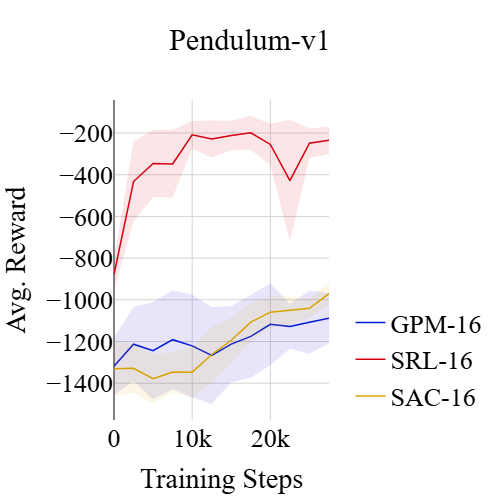
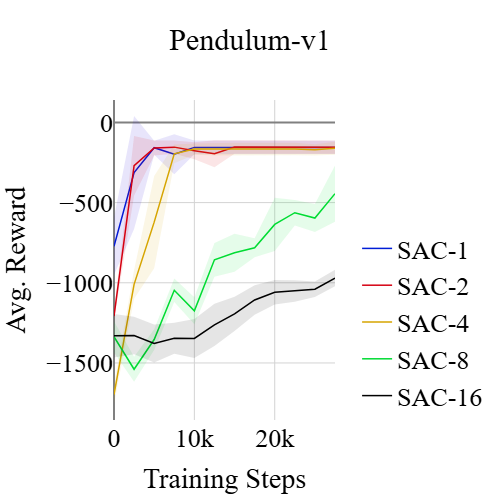
SRL在连续控制任务中取得了显著的成果。与传统的RL算法相比,SRL在降低决策频率的同时,保持了相当的性能水平。在某些任务中,SRL甚至超过了最先进的RL算法。此外,SRL在频率平均分数(FAS)指标上表现出色,表明其在不同决策频率下具有良好的鲁棒性。与基于模型的在线规划相比,SRL在利用相同模型的情况下,实现了相当的FAS,同时避免了在线规划的计算开销。
🎯 应用场景
SRL算法在机器人控制、自动驾驶、游戏AI等领域具有广泛的应用前景。例如,在机器人控制中,SRL可以用于控制机械臂完成复杂的装配任务,而无需高频率的控制信号。在自动驾驶中,SRL可以用于生成车辆的行驶轨迹,从而实现更平稳和安全的驾驶体验。此外,SRL还可以应用于资源受限的嵌入式系统,降低计算和通信开销。
📄 摘要(原文)
Reinforcement learning (RL) is rapidly reaching and surpassing human-level control capabilities. However, state-of-the-art RL algorithms often require timesteps and reaction times significantly faster than human capabilities, which is impractical in real-world settings and typically necessitates specialized hardware. We introduce Sequence Reinforcement Learning (SRL), an RL algorithm designed to produce a sequence of actions for a given input state, enabling effective control at lower decision frequencies. SRL addresses the challenges of learning action sequences by employing both a model and an actor-critic architecture operating at different temporal scales. We propose a "temporal recall" mechanism, where the critic uses the model to estimate intermediate states between primitive actions, providing a learning signal for each individual action within the sequence. Once training is complete, the actor can generate action sequences independently of the model, achieving model-free control at a slower frequency. We evaluate SRL on a suite of continuous control tasks, demonstrating that it achieves performance comparable to state-of-the-art algorithms while significantly reducing actor sample complexity. To better assess performance across varying decision frequencies, we introduce the Frequency-Averaged Score (FAS) metric. Our results show that SRL significantly outperforms traditional RL algorithms in terms of FAS, making it particularly suitable for applications requiring variable decision frequencies. Furthermore, we compare SRL with model-based online planning, showing that SRL achieves comparable FAS while leveraging the same model during training that online planners use for planning.