The Good, the Bad and the Ugly: Meta-Analysis of Watermarks, Transferable Attacks and Adversarial Defenses
作者: Grzegorz Głuch, Berkant Turan, Sai Ganesh Nagarajan, Sebastian Pokutta
分类: cs.LG, cs.AI, cs.CR
发布日期: 2024-10-11 (更新: 2026-01-21)
备注: 47 pages, 3 figures, 4 tables, preliminary version published in ICML 2024 (Workshop on Theoretical Foundations of Foundation Models) and , see https://openreview.net/pdf?id=WMaFRiggwV
💡 一句话要点
形式化分析水印、可迁移攻击与对抗防御的权衡,揭示三者至少存在其一
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction)
关键词: 水印攻击 对抗防御 可迁移攻击 全同态加密 模型安全性
📋 核心要点
- 现有研究主要关注水印与对抗防御的权衡,忽略了可迁移攻击这一关键因素。
- 论文将水印、对抗防御和可迁移攻击三者置于统一框架下,证明三者至少存在其一。
- 利用全同态加密构建可迁移攻击,并证明其在水印与对抗防御权衡中的必要性。
📝 摘要(中文)
本文形式化并分析了基于后门的水印和对抗防御之间的权衡,将其构建为验证者和证明者之间的交互协议。以往工作主要关注这种权衡,而本文通过将可迁移攻击识别为第三种反直觉但必要的选择,扩展了这一分析。我们的主要结果表明,对于所有学习任务,水印、对抗防御或可迁移攻击这三者中至少存在一个。所谓可迁移攻击,指的是一种高效的算法,可以生成与数据分布无法区分的查询,并且能够欺骗所有高效的防御者。我们利用密码学技术,特别是全同态加密,构建了一种可迁移攻击,并证明了其在这种权衡中的必要性。最后,我们表明,VC维有界的任务允许对抗所有攻击者的对抗防御,而一个子类允许针对快速对抗者的安全水印。
🔬 方法详解
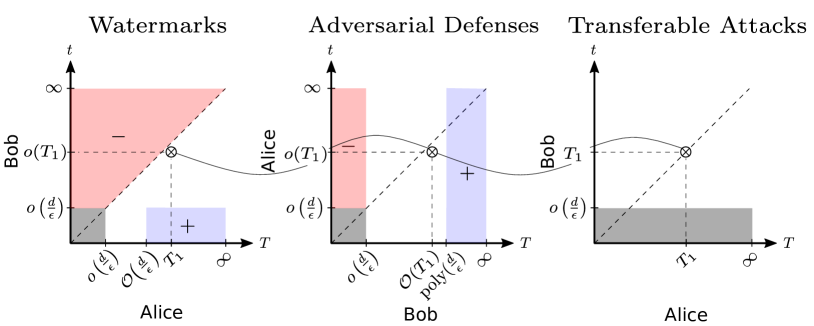
问题定义:论文旨在解决机器学习模型安全领域中,水印(watermark)、对抗防御(adversarial defense)和可迁移攻击(transferable attack)三者之间的复杂关系。现有方法通常只关注水印和对抗防御的权衡,忽略了可迁移攻击的影响,导致对模型安全性的理解不完整。此外,缺乏一个统一的理论框架来分析这三者之间的相互作用。
核心思路:论文的核心思路是将水印、对抗防御和可迁移攻击视为一个三方博弈,并证明对于任何学习任务,这三者中至少存在一个。这意味着如果一个模型既没有有效的水印,也没有可靠的对抗防御,那么它就必然容易受到可迁移攻击。这种思路强调了模型安全性的整体性,不能只关注单一的防御手段。
技术框架:论文将水印验证过程形式化为一个验证者(verifier)和证明者(prover)之间的交互协议。验证者试图验证模型是否包含特定的水印,而证明者试图证明模型是合法的,或者攻击者试图欺骗验证者。论文使用密码学中的全同态加密(Fully Homomorphic Encryption, FHE)技术来构建可迁移攻击。FHE允许在加密数据上进行计算,而无需解密,这使得攻击者可以生成与真实数据分布难以区分的查询,从而绕过对抗防御。
关键创新:论文最重要的技术创新在于证明了水印、对抗防御和可迁移攻击三者之间的必然联系,并利用全同态加密技术构建了可迁移攻击。这种攻击能够绕过现有的对抗防御机制,揭示了模型安全性的潜在漏洞。此外,论文还分析了VC维对模型安全性的影响,表明VC维有界的任务允许对抗所有攻击者的对抗防御。
关键设计:论文使用全同态加密来生成可迁移攻击的查询。具体来说,攻击者首先加密一些随机数据,然后使用全同态加密在加密数据上执行一些计算,生成新的加密查询。由于计算是在加密数据上进行的,因此攻击者无需知道真实的数据分布,也无需访问模型的内部参数。这种方法使得攻击具有很强的可迁移性,可以攻击各种不同的模型和防御机制。论文还分析了不同类型的学习任务对水印和对抗防御的影响,例如,VC维有界的任务允许更强的对抗防御。
🖼️ 关键图片

📊 实验亮点
论文的主要实验结果是证明了可迁移攻击的存在性,并利用全同态加密构建了具体的攻击方法。虽然论文没有提供具体的性能数据,但理论分析表明,这种攻击能够绕过现有的对抗防御机制。此外,论文还证明了VC维有界的任务允许对抗所有攻击者的对抗防御,为模型安全性的理论研究提供了新的视角。
🎯 应用场景
该研究成果可应用于提升机器学习模型的安全性,尤其是在模型部署到开放环境时。通过理解水印、对抗防御和可迁移攻击之间的权衡,开发者可以更好地设计和评估模型的安全性,并选择合适的防御策略。此外,该研究对于开发更安全的联邦学习系统和保护用户隐私具有重要意义。
📄 摘要(原文)
We formalize and analyze the trade-off between backdoor-based watermarks and adversarial defenses, framing it as an interactive protocol between a verifier and a prover. While previous works have primarily focused on this trade-off, our analysis extends it by identifying transferable attacks as a third, counterintuitive, but necessary option. Our main result shows that for all learning tasks, at least one of the three exists: a watermark, an adversarial defense, or a transferable attack. By transferable attack, we refer to an efficient algorithm that generates queries indistinguishable from the data distribution and capable of fooling all efficient defenders. Using cryptographic techniques, specifically fully homomorphic encryption, we construct a transferable attack and prove its necessity in this trade-off. Finally, we show that tasks of bounded VC-dimension allow adversarial defenses against all attackers, while a subclass allows watermarks secure against fast adversaries.