M$^3$-Impute: Mask-guided Representation Learning for Missing Value Imputation
作者: Zhongyi Yu, Zhenghao Wu, Shuhan Zhong, Weifeng Su, S. -H. Gary Chan, Chul-Ho Lee, Weipeng Zhuo
分类: cs.LG, cs.AI
发布日期: 2024-10-11
💡 一句话要点
M$^3$-Impute:利用掩码引导的表征学习进行缺失值插补
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 缺失值插补 图神经网络 表征学习 掩码机制 特征相关性
📋 核心要点
- 现有插补方法忽略了缺失信息,且对特征和样本间的复杂关联建模不足,导致插补性能受限。
- M$^3$-Impute通过掩码机制显式利用缺失信息,并设计特征相关单元和样本相关单元来捕获特征和样本相关性。
- 在25个基准数据集上的实验表明,M$^3$-Impute在不同缺失设置下均表现出色,取得了显著的性能提升。
📝 摘要(中文)
缺失值是数据分析和机器学习中一个常见的问题,对数据质量和模型性能构成重大挑战。为了准确填充缺失值,提升数据集的整体质量和效用,开发有效的插补方法至关重要。然而,现有的插补方法在嵌入初始化阶段未能显式考虑数据中的“缺失性”信息,并且在学习过程中对纠缠的特征和样本相关性建模不足,导致性能不佳。为此,我们提出了M$^3$-Impute,旨在通过新颖的掩码方案显式地利用缺失性信息和这种相关性。M$^3$-Impute首先将数据建模为二分图,并使用图神经网络来学习节点嵌入,其中改进的嵌入初始化过程直接结合了缺失性信息。然后,通过M$^3$-Impute的新型特征相关单元(FRU)和样本相关单元(SRU)对其进行优化,有效地捕获特征和样本相关性以进行插补。在三种不同的缺失设置下,对25个基准数据集的实验结果表明了M$^3$-Impute的有效性,平均实现了20个最佳和4个次佳的MAE分数。
🔬 方法详解
问题定义:论文旨在解决数据缺失值插补问题。现有方法的痛点在于,它们通常忽略了数据缺失的模式(即哪些值缺失,以及缺失的原因),并且未能充分利用特征之间以及样本之间的相关性来进行更准确的插补。这导致插补结果的准确性降低,影响后续数据分析和机器学习任务的性能。
核心思路:论文的核心思路是显式地将缺失信息纳入到模型的学习过程中,并充分利用特征和样本之间的相关性。通过引入掩码机制来表示缺失信息,并设计专门的模块来捕获特征和样本之间的依赖关系,从而实现更准确的缺失值插补。这种方法的核心在于将缺失模式视为一种有用的信息,而不是需要简单忽略的噪声。
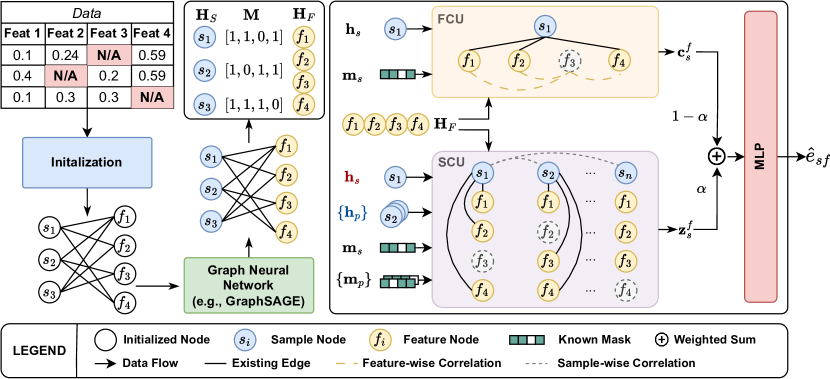
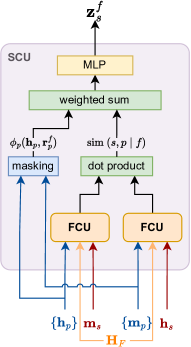
技术框架:M$^3$-Impute的整体框架包括以下几个主要步骤:1) 将数据建模为二分图,其中节点表示特征和样本。2) 使用图神经网络(GNN)学习节点嵌入,并在嵌入初始化阶段显式地结合缺失信息。3) 通过特征相关单元(FRU)和样本相关单元(SRU)来优化嵌入,这两个单元分别用于捕获特征和样本之间的相关性。4) 使用学习到的嵌入来预测缺失值。
关键创新:M$^3$-Impute的关键创新在于:1) 显式地利用缺失信息进行嵌入初始化,这与传统方法忽略缺失模式的做法不同。2) 提出了特征相关单元(FRU)和样本相关单元(SRU),用于有效地捕获特征和样本之间的复杂相关性。3) 将数据建模为二分图,并使用GNN进行表征学习,这使得模型能够更好地处理高维数据和复杂的依赖关系。
关键设计:在嵌入初始化阶段,论文使用掩码向量来表示每个数据点的缺失模式,并将这些掩码向量与原始特征向量连接起来,作为GNN的输入。FRU和SRU的具体实现细节未知,但可以推测它们可能使用了注意力机制或其他相关性建模技术。损失函数的设计也未知,但很可能包括一个重构损失,用于衡量插补值的准确性。
🖼️ 关键图片
📊 实验亮点
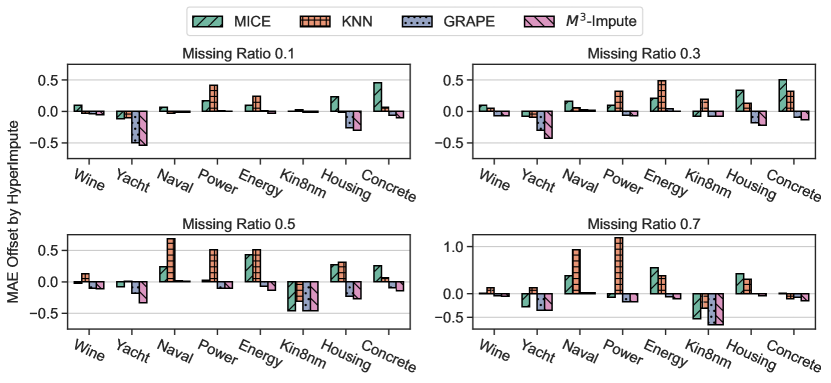
M$^3$-Impute在25个基准数据集上进行了广泛的实验,并在三种不同的缺失设置下进行了评估。实验结果表明,M$^3$-Impute在平均MAE指标上取得了20个最佳和4个次佳的成绩,显著优于现有的插补方法。这些结果充分证明了M$^3$-Impute在缺失值插补方面的有效性和优越性。
🎯 应用场景
M$^3$-Impute可广泛应用于各种存在数据缺失的领域,如医疗健康、金融、推荐系统等。在医疗领域,可以用于填充患者病历中的缺失数据,提高诊断的准确性。在金融领域,可以用于填充信用评分中的缺失信息,提升风险评估的可靠性。在推荐系统中,可以用于填充用户行为数据中的缺失值,改善推荐效果。该研究的实际价值在于提高数据质量,提升下游任务的性能,并为未来的缺失值插补研究提供新的思路。
📄 摘要(原文)
Missing values are a common problem that poses significant challenges to data analysis and machine learning. This problem necessitates the development of an effective imputation method to fill in the missing values accurately, thereby enhancing the overall quality and utility of the datasets. Existing imputation methods, however, fall short of explicitly considering the `missingness' information in the data during the embedding initialization stage and modeling the entangled feature and sample correlations during the learning process, thus leading to inferior performance. We propose M$^3$-Impute, which aims to explicitly leverage the missingness information and such correlations with novel masking schemes. M$^3$-Impute first models the data as a bipartite graph and uses a graph neural network to learn node embeddings, where the refined embedding initialization process directly incorporates the missingness information. They are then optimized through M$^3$-Impute's novel feature correlation unit (FRU) and sample correlation unit (SRU) that effectively captures feature and sample correlations for imputation. Experiment results on 25 benchmark datasets under three different missingness settings show the effectiveness of M$^3$-Impute by achieving 20 best and 4 second-best MAE scores on average.