COS-DPO: Conditioned One-Shot Multi-Objective Fine-Tuning Framework
作者: Yinuo Ren, Tesi Xiao, Michael Shavlovsky, Lexing Ying, Holakou Rahmanian
分类: cs.LG, cs.CL, math.OC
发布日期: 2024-10-10 (更新: 2025-06-20)
备注: Published at UAI 2025
💡 一句话要点
提出COS-DPO,一种条件式单次多目标微调框架,用于解决多目标优化问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多目标优化 直接偏好优化 条件式微调 帕累托前沿 大型语言模型 学习排序 模型对齐
📋 核心要点
- 现有方法难以同时优化多个目标,尤其是在大型语言模型微调中,需要权衡不同目标。
- COS-DPO通过条件化直接偏好优化,实现单次训练即可获得帕累托前沿,灵活调整目标权重。
- 实验表明,COS-DPO在学习排序和LLM对齐等任务上有效且高效,适用于大规模机器学习部署。
📝 摘要(中文)
在LLM对齐和许多其他机器学习应用中,常常面临多目标微调(MOFT)问题,即同时使用针对不同目标标记的数据集来微调现有模型。为了解决这个挑战,我们提出了一种条件式单次微调框架(COS-DPO),它扩展了直接偏好优化技术,该技术最初是为使用偏好数据高效对齐LLM而开发的,以适应MOFT设置。通过直接调节辅助目标的权重,我们的Weight-COS-DPO方法可以高效地进行单次训练过程,以分析帕累托前沿,并且即使在训练后阶段也能够实现全面的权衡解决方案。基于我们对损失函数线性变换性质的理论发现,我们进一步提出了Temperature-COS-DPO方法,该方法将温度参数添加到模型输入中,从而增强了训练后对主要目标和辅助目标之间权衡的控制灵活性。我们通过将其应用于各种任务(包括学习排序(LTR)和LLM对齐任务)来证明COS-DPO框架的有效性和效率,突出了其在大规模ML部署中的可行性。
🔬 方法详解
问题定义:论文旨在解决多目标微调(MOFT)问题,即如何同时利用多个针对不同目标标注的数据集来微调预训练模型。现有方法通常需要多次训练或复杂的权重调整策略,效率较低,且难以在训练后灵活调整不同目标之间的权衡。
核心思路:COS-DPO的核心思路是将多目标优化问题转化为一个条件偏好优化问题。通过将目标权重作为条件输入到模型中,使得模型能够根据不同的权重组合学习到不同的策略,从而在单次训练中获得帕累托前沿。这样,在训练后,可以通过调整条件权重来灵活地控制不同目标之间的权衡。
技术框架:COS-DPO框架基于直接偏好优化(DPO)技术。DPO是一种高效的LLM对齐方法,它通过优化一个偏好模型来直接学习人类偏好。COS-DPO扩展了DPO,使其能够处理多个目标。框架包含两个主要变体:Weight-COS-DPO和Temperature-COS-DPO。Weight-COS-DPO直接将目标权重作为条件输入。Temperature-COS-DPO则引入温度参数,进一步增强了训练后控制权衡的灵活性。
关键创新:COS-DPO的关键创新在于将目标权重作为条件输入,从而实现了单次训练即可获得帕累托前沿。这与传统的需要多次训练或复杂权重调整的方法不同。此外,Temperature-COS-DPO通过引入温度参数,进一步增强了训练后控制权衡的灵活性。论文还提供了关于损失函数线性变换性质的理论分析,为Temperature-COS-DPO的设计提供了理论依据。
关键设计:Weight-COS-DPO的关键设计是将目标权重向量与输入文本拼接,作为模型的输入。Temperature-COS-DPO则将温度参数添加到模型输入中。损失函数基于DPO的损失函数进行修改,以适应多目标优化。具体来说,损失函数鼓励模型生成更符合给定目标权重的输出。论文还详细描述了如何选择合适的温度参数,以及如何利用帕累托前沿进行决策。
🖼️ 关键图片
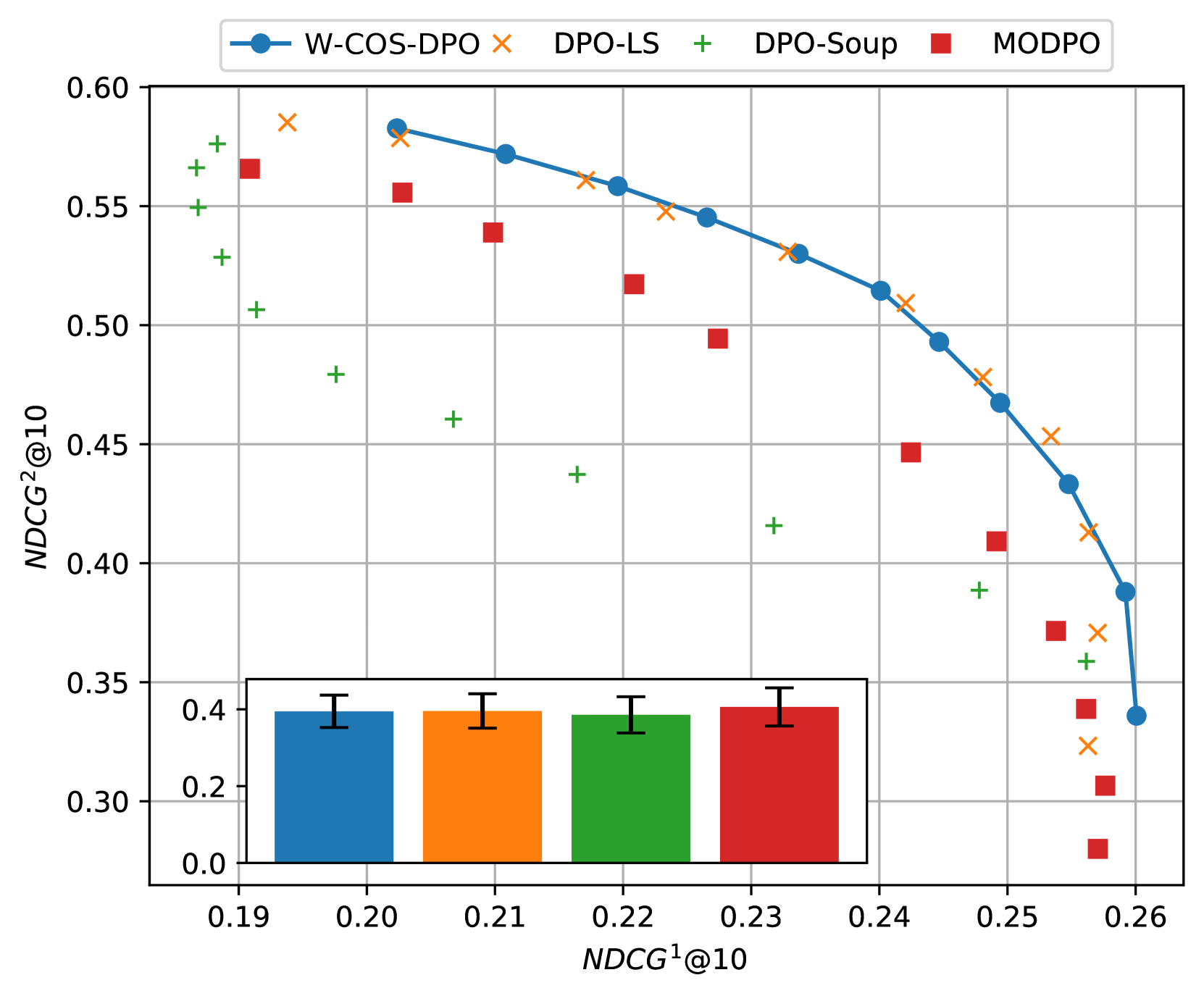
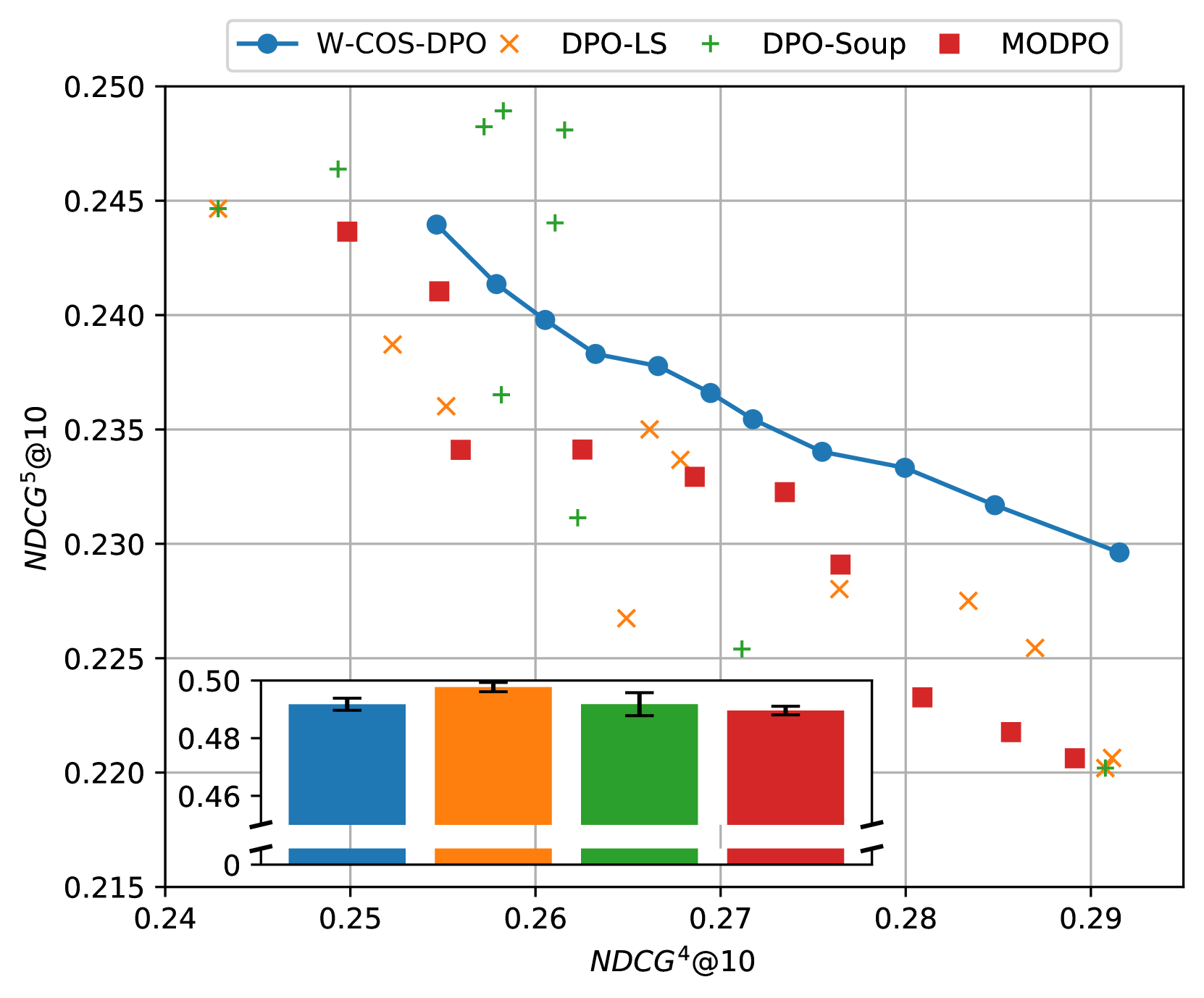
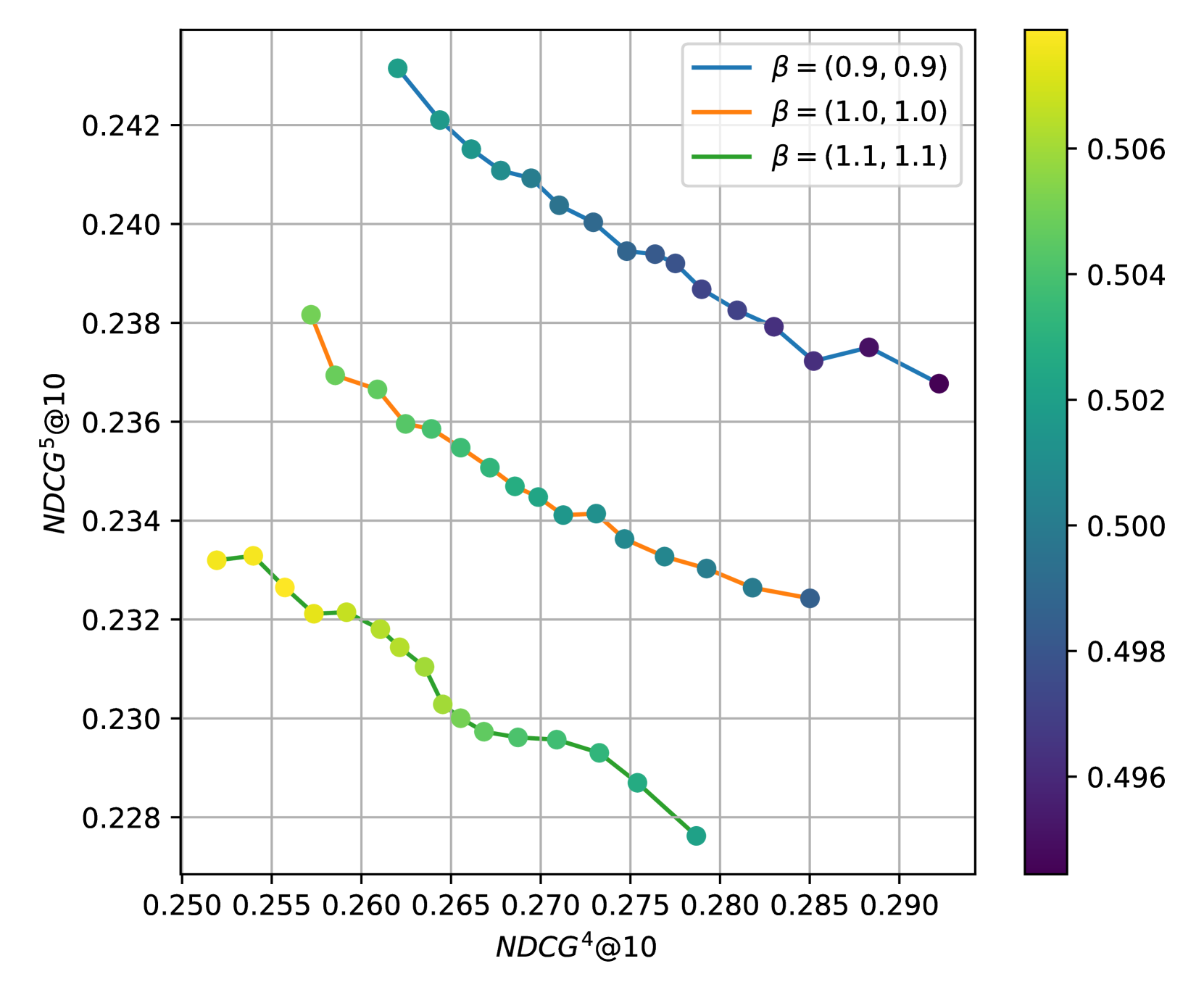
📊 实验亮点
论文通过在学习排序和LLM对齐任务上的实验,验证了COS-DPO的有效性和效率。实验结果表明,COS-DPO能够有效地生成帕累托前沿,并且在训练后能够灵活地调整不同目标之间的权衡。与传统的MOFT方法相比,COS-DPO在训练效率和性能方面均有显著提升。具体性能数据未知。
🎯 应用场景
COS-DPO框架可应用于各种需要多目标优化的机器学习任务,例如学习排序(Learning-to-Rank)、LLM对齐、推荐系统、机器人控制等。该方法能够帮助开发者在不同目标之间找到最佳的权衡方案,提高模型的整体性能和用户满意度。尤其适用于大规模机器学习部署,能够显著降低训练成本和部署复杂度。
📄 摘要(原文)
In LLM alignment and many other ML applications, one often faces the Multi-Objective Fine-Tuning (MOFT) problem, i.e., fine-tuning an existing model with datasets labeled w.r.t. different objectives simultaneously. To address the challenge, we propose a Conditioned One-Shot fine-tuning framework (COS-DPO) that extends the Direct Preference Optimization technique, originally developed for efficient LLM alignment with preference data, to accommodate the MOFT settings. By direct conditioning on the weight across auxiliary objectives, our Weight-COS-DPO method enjoys an efficient one-shot training process for profiling the Pareto front and is capable of achieving comprehensive trade-off solutions even in the post-training stage. Based on our theoretical findings on the linear transformation properties of the loss function, we further propose the Temperature-COS-DPO method that augments the temperature parameter to the model input, enhancing the flexibility of post-training control over the trade-offs between the main and auxiliary objectives. We demonstrate the effectiveness and efficiency of the COS-DPO framework through its applications to various tasks, including the Learning-to-Rank (LTR) and LLM alignment tasks, highlighting its viability for large-scale ML deployments.