Evolutionary Contrastive Distillation for Language Model Alignment
作者: Julian Katz-Samuels, Zheng Li, Hyokun Yun, Priyanka Nigam, Yi Xu, Vaclav Petricek, Bing Yin, Trishul Chilimbi
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-10-10
💡 一句话要点
提出进化对比蒸馏(ECD)方法,提升LLM在复杂指令跟随任务上的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 指令跟随 对比学习 蒸馏训练 进化算法
📋 核心要点
- 现有LLM在复杂指令跟随方面存在不足,难以满足实际应用需求。
- ECD通过进化指令生成高质量对比数据,区分正确与细微错误响应,提升模型辨别能力。
- 实验表明,ECD训练的7B模型在复杂指令跟随上超越现有7B模型,媲美70B模型。
📝 摘要(中文)
大型语言模型(LLM)执行复杂指令的能力对其现实应用至关重要。然而,最近的研究表明,LLM在处理具有挑战性的指令时表现不佳。本文提出了一种新的方法,即进化对比蒸馏(ECD),用于生成高质量的合成偏好数据,旨在增强语言模型执行复杂指令的能力。ECD生成的数据专门用于区分成功遵循复杂指令的响应和高质量但存在细微错误的响应。通过提示LLM逐步将简单指令演变为更复杂的指令来实现这一点。当指令的复杂性增加时,原始指令的成功响应将成为新指令的“难负例”响应,它几乎满足新指令的要求,但仅缺少一两个方面。通过将好的响应与这样的难负例响应配对,并采用对比学习算法(如DPO),我们提高了语言模型遵循复杂指令的能力。实验结果表明,我们的方法产生了一个7B模型,其复杂指令跟随性能超过了当前SOTA的7B模型,甚至可以与开源的70B模型相媲美。
🔬 方法详解
问题定义:现有大型语言模型在处理复杂指令时表现不佳,难以准确理解并执行指令中的细微差别。现有的指令微调方法难以有效区分高质量但略有偏差的响应和完全正确的响应,导致模型在复杂场景下性能受限。
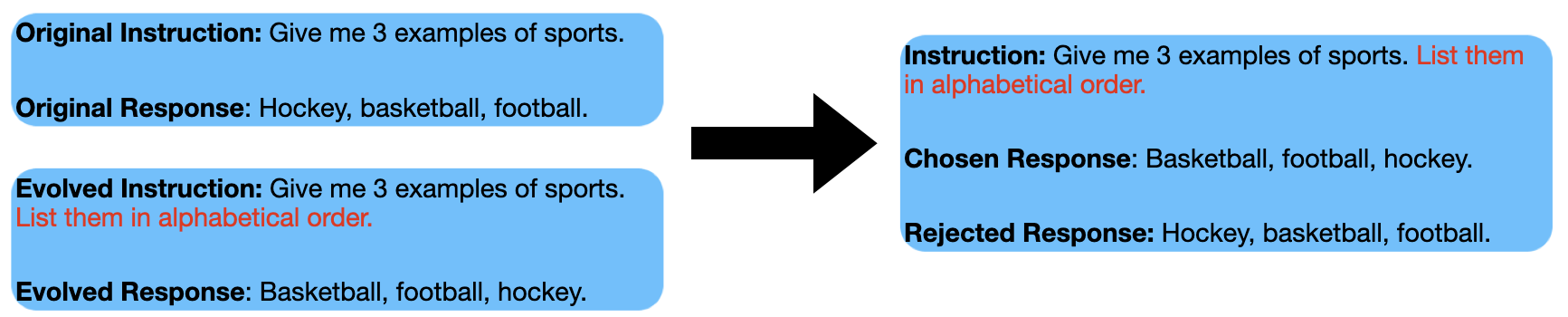
核心思路:论文的核心思路是通过进化生成的方式,构建高质量的对比学习数据。具体来说,从简单指令出发,逐步演化成复杂指令,并将原始指令的正确回复作为新指令的“难负例”。这种难负例与正确回复构成对比对,能够有效训练模型区分细微差别。
技术框架:ECD方法包含以下主要步骤:1) 指令进化:利用LLM将简单指令逐步演化为复杂指令。2) 响应生成:对于每个指令,生成一个“好”的响应和一个“难负例”响应(即原始指令的正确回复)。3) 对比学习:使用生成的对比数据,通过对比学习算法(如DPO)微调LLM,提升其区分复杂指令的能力。
关键创新:ECD的关键创新在于其数据生成方式。传统的指令微调方法通常依赖人工标注或简单的数据增强,难以生成高质量的对比数据。ECD通过指令进化,自动生成既具有挑战性又具有区分度的对比数据,从而更有效地提升模型性能。
关键设计:在指令进化阶段,论文使用了特定的prompt来引导LLM生成更复杂的指令。在对比学习阶段,论文采用了Direct Preference Optimization (DPO) 算法,该算法能够直接优化模型的偏好,而无需显式地建模奖励函数。具体的参数设置和超参数优化细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用ECD方法训练的7B模型在复杂指令跟随任务上取得了显著的性能提升,超过了当前SOTA的7B模型,并且能够与开源的70B模型相媲美。这表明ECD方法能够有效地提升小模型的性能,使其在资源受限的场景下也能表现出色。具体的性能指标和对比结果在论文中有详细展示。
🎯 应用场景
该研究成果可广泛应用于需要复杂指令跟随的场景,例如智能助手、自动化客服、代码生成等。通过提升LLM对复杂指令的理解和执行能力,可以显著提高这些应用的智能化水平和用户体验。未来,该方法可以进一步扩展到其他模态,例如图像、视频等,以提升多模态模型的指令跟随能力。
📄 摘要(原文)
The ability of large language models (LLMs) to execute complex instructions is essential for their real-world applications. However, several recent studies indicate that LLMs struggle with challenging instructions. In this paper, we propose Evolutionary Contrastive Distillation (ECD), a novel method for generating high-quality synthetic preference data designed to enhance the complex instruction-following capability of language models. ECD generates data that specifically illustrates the difference between a response that successfully follows a set of complex instructions and a response that is high-quality, but nevertheless makes some subtle mistakes. This is done by prompting LLMs to progressively evolve simple instructions to more complex instructions. When the complexity of an instruction is increased, the original successful response to the original instruction becomes a "hard negative" response for the new instruction, mostly meeting requirements of the new instruction, but barely missing one or two. By pairing a good response with such a hard negative response, and employing contrastive learning algorithms such as DPO, we improve language models' ability to follow complex instructions. Empirically, we observe that our method yields a 7B model that exceeds the complex instruction-following performance of current SOTA 7B models and is competitive even with open-source 70B models.