Unsupervised Representation Learning from Sparse Transformation Analysis
作者: Yue Song, Thomas Anderson Keller, Yisong Yue, Pietro Perona, Max Welling
分类: cs.LG, cs.CV
发布日期: 2024-10-07 (更新: 2025-12-15)
备注: T-PAMI journal paper
💡 一句话要点
提出基于稀疏变换分析的无监督表征学习方法,用于解耦序列数据中的潜在因素。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 无监督学习 表征学习 解耦表征 稀疏变换 概率流模型
📋 核心要点
- 现有表征学习方法在编码效率、统计独立性等方面存在局限,难以有效解耦序列数据中的潜在因素。
- 该方法通过将潜在变量的变换分解为稀疏分量,学习独立变换原语,从而实现对序列数据的解耦表征。
- 实验表明,该模型在数据似然和无监督近似等变误差方面均达到了当前最优水平。
📝 摘要(中文)
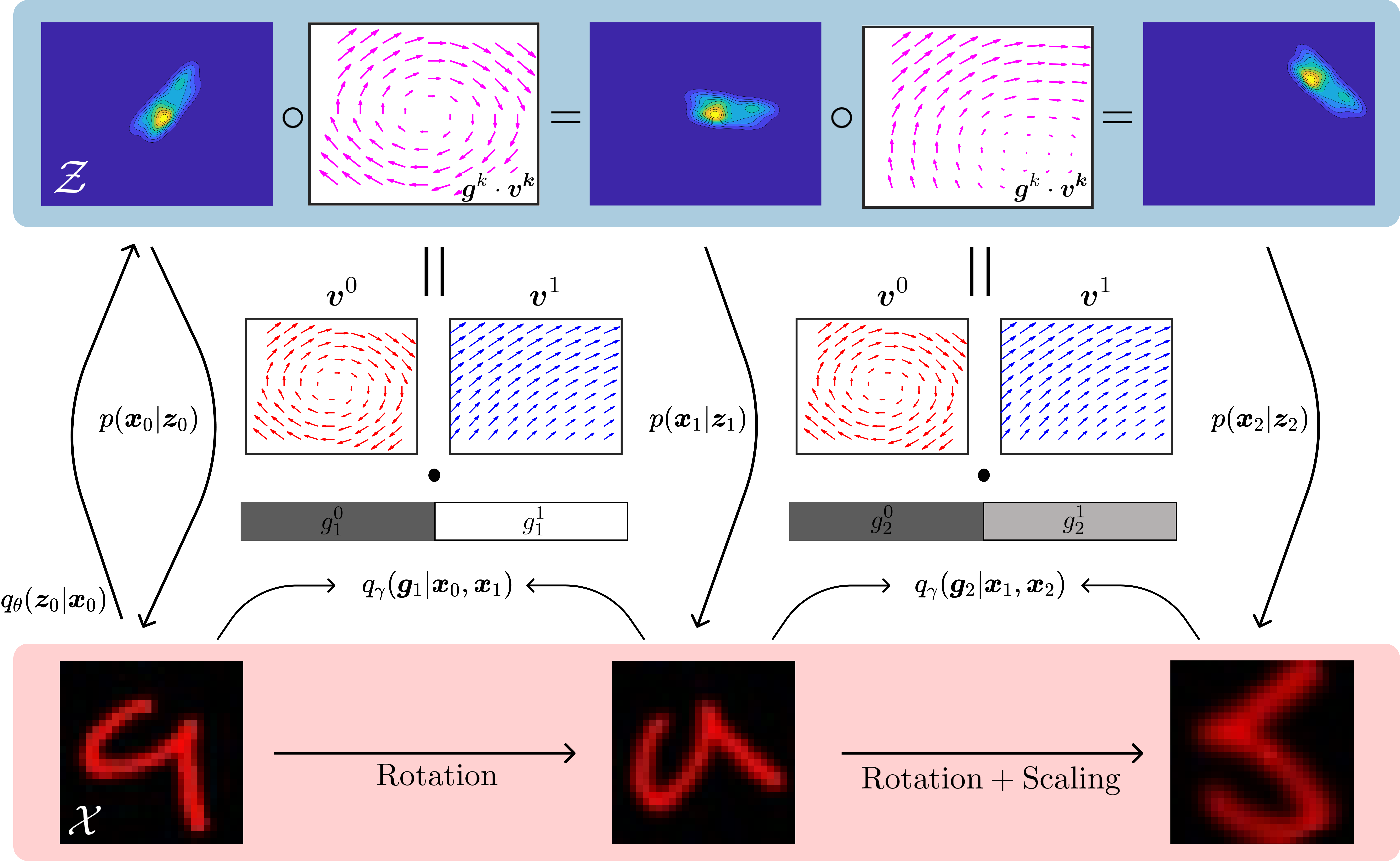
本文提出一种基于稀疏变换分析的表征学习方法,用于从序列数据中进行无监督学习。该方法首先将输入数据编码为潜在激活分布,然后使用概率流模型转换这些分布,最后解码以预测未来的输入状态。概率流模型被分解为若干旋转(无散度)向量场和若干势流(无旋度)场。通过施加稀疏性先验,鼓励在任何时刻只有少量场处于激活状态,并推断概率沿这些场流动的速度。该模型完全以无监督方式训练,使用标准的变分目标,从而产生一种新的解耦表征形式,其中输入不仅由独立因素的组合表示,还由学习到的流场给出的独立变换原语的组合表示。当将变换视为对称性时,可以将其解释为学习近似等变表示。实验结果表明,该模型在由序列变换组成的数据集上,在数据似然和无监督近似等变误差方面均达到了最先进的水平。
🔬 方法详解
问题定义:论文旨在解决从序列数据中无监督地学习解耦表征的问题。现有方法难以有效地将输入数据分解为独立的因素和变换原语,从而限制了模型对序列数据内在结构的理解能力。
核心思路:论文的核心思路是将序列数据中的变换分解为稀疏的、独立的变换原语。通过学习这些原语,模型可以更好地理解序列数据的动态变化,并提取出更具解释性的表征。这种稀疏性约束鼓励模型只关注最相关的变换,从而提高表征的效率和可解释性。
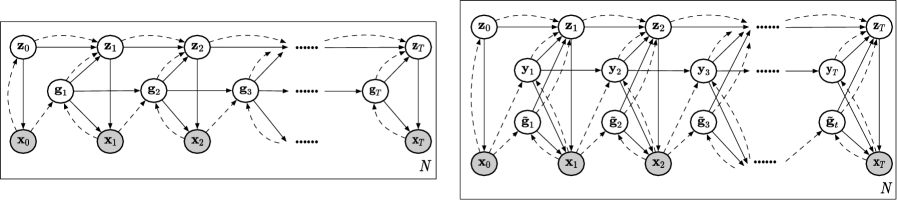
技术框架:该方法包含以下主要模块:1) 编码器:将输入数据编码为潜在激活分布。2) 概率流模型:使用一系列旋转向量场和势流场来转换潜在激活分布。3) 解码器:将转换后的潜在激活分布解码为未来的输入状态。整个框架使用变分自编码器(VAE)结构进行训练。
关键创新:该方法最重要的创新点在于将概率流模型分解为稀疏的旋转向量场和势流场。这种分解方式使得模型能够学习到独立的变换原语,从而实现对序列数据的解耦表征。此外,稀疏性先验的使用进一步提高了表征的效率和可解释性。
关键设计:模型使用标准的变分目标函数进行训练,并引入稀疏性先验来鼓励只有少量流场处于激活状态。具体来说,可以使用L1正则化或其它稀疏性约束方法。旋转向量场和势流场的参数化方式是关键,论文中可能使用了神经网络来学习这些场的参数。概率流动的速度也需要进行推断,这可能涉及到额外的参数或损失函数设计。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该模型在由序列变换组成的数据集上,在数据似然和无监督近似等变误差方面均达到了最先进的水平。这意味着该模型能够更准确地捕捉序列数据的内在结构,并学习到更具泛化能力的表征。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
该研究的潜在应用领域包括视频理解、机器人控制、时间序列分析等。通过学习解耦的表征,模型可以更好地理解和预测序列数据的动态变化,从而提高在这些领域的性能。例如,在机器人控制中,可以学习控制机器人的独立动作原语,从而实现更灵活和高效的控制。
📄 摘要(原文)
There is a vast literature on representation learning based on principles such as coding efficiency, statistical independence, causality, controllability, or symmetry. In this paper we propose to learn representations from sequence data by factorizing the transformations of the latent variables into sparse components. Input data are first encoded as distributions of latent activations and subsequently transformed using a probability flow model, before being decoded to predict a future input state. The flow model is decomposed into a number of rotational (divergence-free) vector fields and a number of potential flow (curl-free) fields. Our sparsity prior encourages only a small number of these fields to be active at any instant and infers the speed with which the probability flows along these fields. Training this model is completely unsupervised using a standard variational objective and results in a new form of disentangled representations where the input is not only represented by a combination of independent factors, but also by a combination of independent transformation primitives given by the learned flow fields. When viewing the transformations as symmetries one may interpret this as learning approximately equivariant representations. Empirically we demonstrate that this model achieves state of the art in terms of both data likelihood and unsupervised approximate equivariance errors on datasets composed of sequence transformations.