RespLLM: Unifying Audio and Text with Multimodal LLMs for Generalized Respiratory Health Prediction
作者: Yuwei Zhang, Tong Xia, Aaqib Saeed, Cecilia Mascolo
分类: cs.LG, cs.AI, cs.SD, eess.AS
发布日期: 2024-10-07
💡 一句话要点
RespLLM:利用多模态LLM统一音频和文本,实现广义呼吸系统健康预测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 呼吸系统健康 音频文本融合 指令调优
📋 核心要点
- 现有呼吸系统疾病预测方法依赖有限数据和简单融合,泛化性不足,难以处理异构数据。
- RespLLM利用多模态LLM统一文本和音频,通过跨模态注意力融合,并使用指令调优提升泛化性。
- 实验表明RespLLM在多个数据集上优于现有方法,并在零样本预测中表现出色,具有实际应用潜力。
📝 摘要(中文)
呼吸系统疾病的高发病率和死亡率凸显了早期筛查的重要性。机器学习模型可以自动化临床咨询和听诊,为该领域提供重要支持。然而,相关数据(包括人口统计学信息、病史、症状和呼吸音频)是异构且复杂的。现有的方法通常依赖于有限的训练数据、基本融合技术和特定于任务的模型,因此不足且缺乏泛化能力。本文提出了RespLLM,一种新颖的多模态大型语言模型(LLM)框架,它统一了文本和音频表示,用于呼吸系统健康预测。RespLLM利用了预训练LLM的广泛先验知识,并通过跨模态注意力实现有效的音频-文本融合。采用指令调优来整合来自多个来源的多样化数据,确保模型的泛化性和通用性。在五个真实世界数据集上的实验表明,RespLLM在已训练任务上的表现优于领先的基线平均4.6%,在未见数据集上的表现优于7.9%,并促进了新任务的零样本预测。我们的工作为可以感知、倾听和理解异构数据的多模态模型奠定了基础,为可扩展的呼吸系统健康诊断铺平了道路。
🔬 方法详解
问题定义:现有呼吸系统疾病预测方法面临数据异构性挑战,包括文本(病史、症状)和音频(呼吸音)。传统方法依赖于特定任务的模型和有限的数据,导致泛化能力差,难以适应新的数据集和任务。此外,简单的特征融合方法无法充分利用不同模态之间的关联。
核心思路:RespLLM的核心思路是利用预训练大型语言模型(LLM)的强大先验知识和泛化能力,将文本和音频信息统一到一个框架中。通过跨模态注意力机制,实现音频和文本特征的有效融合,从而提升呼吸系统健康预测的准确性和泛化性。指令调优进一步增强了模型对不同任务的适应能力。
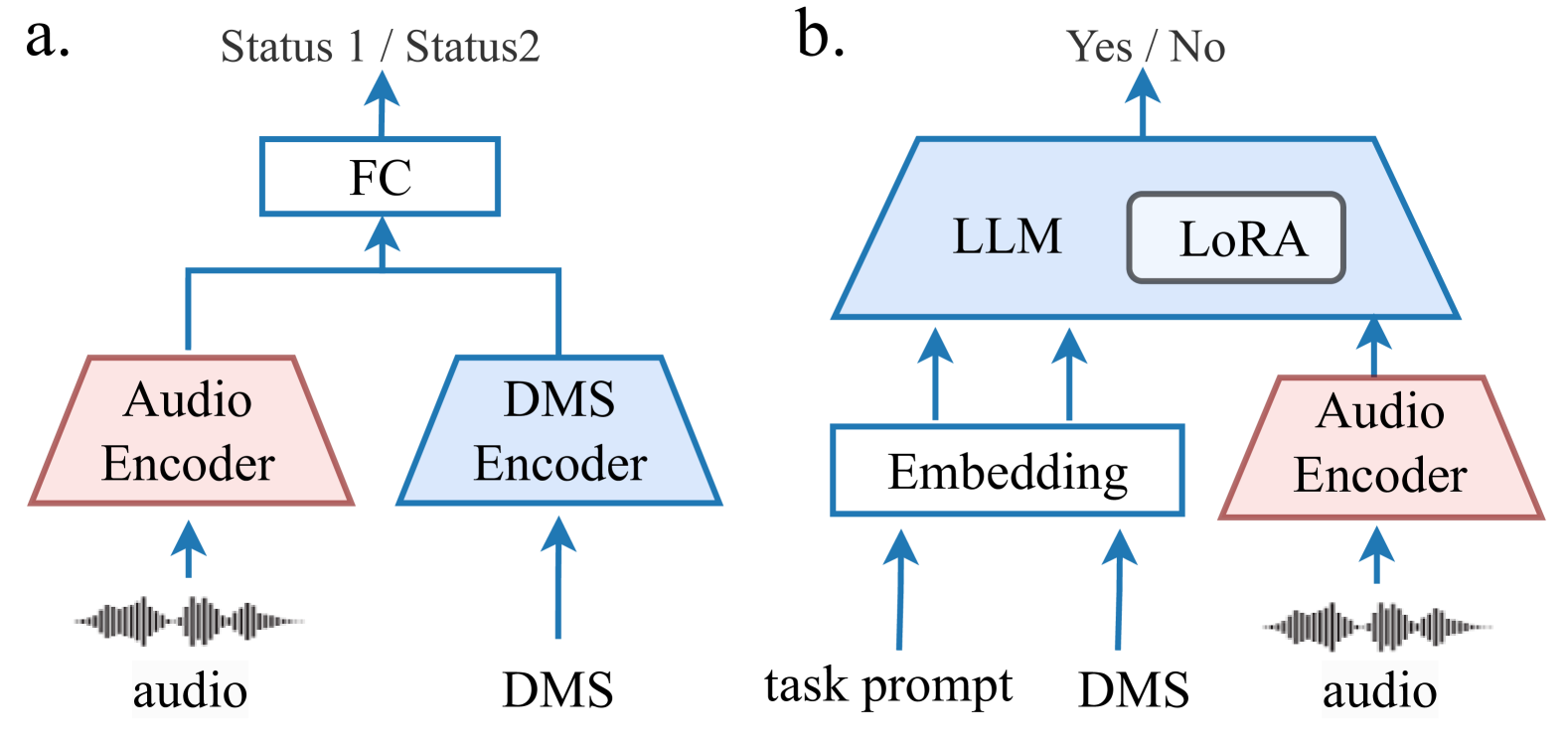
技术框架:RespLLM框架主要包括以下几个模块:1) 音频编码器:将呼吸音频转换为特征向量表示。2) 文本编码器:将文本信息(如病史、症状)转换为特征向量表示。3) 跨模态注意力模块:融合音频和文本特征,学习模态间的关联。4) LLM解码器:基于融合后的特征,预测呼吸系统健康状况。5) 指令调优模块:使用多源数据进行指令调优,提升模型的泛化性和通用性。
关键创新:RespLLM的关键创新在于:1) 提出了一种基于多模态LLM的呼吸系统健康预测框架,能够有效处理异构数据。2) 采用了跨模态注意力机制,实现了音频和文本特征的有效融合。3) 使用指令调优方法,提升了模型的泛化性和通用性。与现有方法相比,RespLLM能够更好地利用预训练LLM的知识,并能够适应新的数据集和任务。
关键设计:音频编码器可以使用预训练的音频模型(如AST),文本编码器可以使用预训练的文本模型(如BERT)。跨模态注意力模块可以使用Transformer结构。指令调优可以使用不同的指令数据集和调优策略。损失函数可以使用交叉熵损失函数或Focal Loss。具体的参数设置需要根据数据集和任务进行调整。
🖼️ 关键图片


📊 实验亮点
RespLLM在五个真实世界数据集上进行了评估,结果表明其性能优于领先的基线模型。在已训练任务上,RespLLM的平均性能提升了4.6%。在未见数据集上,RespLLM的平均性能提升了7.9%。此外,RespLLM还能够进行新任务的零样本预测,展示了其强大的泛化能力。
🎯 应用场景
RespLLM可应用于呼吸系统疾病的早期筛查、诊断和监测。它可以自动化临床咨询和听诊过程,减轻医生的工作负担,提高诊断效率。此外,RespLLM还可以用于远程医疗和移动健康应用,为患者提供便捷的呼吸系统健康服务。该研究为多模态医学数据分析提供了一种新的思路,有望推动医疗人工智能的发展。
📄 摘要(原文)
The high incidence and mortality rates associated with respiratory diseases underscores the importance of early screening. Machine learning models can automate clinical consultations and auscultation, offering vital support in this area. However, the data involved, spanning demographics, medical history, symptoms, and respiratory audio, are heterogeneous and complex. Existing approaches are insufficient and lack generalizability, as they typically rely on limited training data, basic fusion techniques, and task-specific models. In this paper, we propose RespLLM, a novel multimodal large language model (LLM) framework that unifies text and audio representations for respiratory health prediction. RespLLM leverages the extensive prior knowledge of pretrained LLMs and enables effective audio-text fusion through cross-modal attentions. Instruction tuning is employed to integrate diverse data from multiple sources, ensuring generalizability and versatility of the model. Experiments on five real-world datasets demonstrate that RespLLM outperforms leading baselines by an average of 4.6% on trained tasks, 7.9% on unseen datasets, and facilitates zero-shot predictions for new tasks. Our work lays the foundation for multimodal models that can perceive, listen to, and understand heterogeneous data, paving the way for scalable respiratory health diagnosis.