Compression via Pre-trained Transformers: A Study on Byte-Level Multimodal Data
作者: David Heurtel-Depeiges, Anian Ruoss, Joel Veness, Tim Genewein
分类: cs.LG, cs.AI, cs.IT
发布日期: 2024-10-07 (更新: 2025-05-23)
💡 一句话要点
利用预训练Transformer实现高效数据压缩,超越传统算法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据压缩 预训练Transformer 多模态学习 字节级别建模 模型压缩
📋 核心要点
- 现有Foundation模型压缩率受限于参数规模,直接缩减参数会降低预测精度。
- 探索使用预训练Transformer进行数据压缩,在参数规模和压缩性能间寻找平衡点。
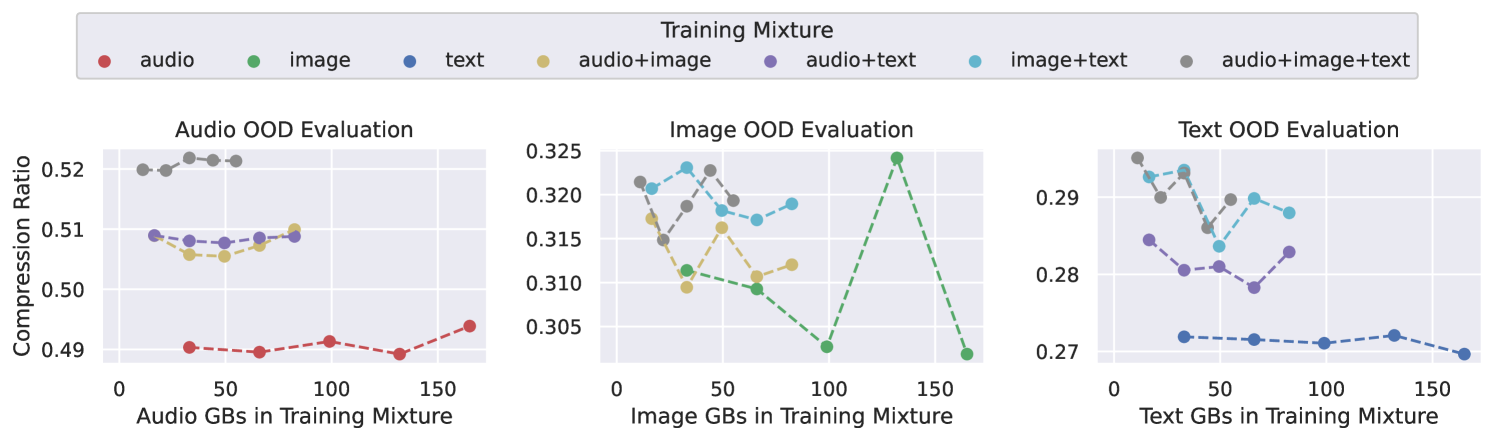
- 实验表明,小型Transformer模型在多种模态数据上超越传统压缩算法,但跨模态迁移能力有限。
📝 摘要(中文)
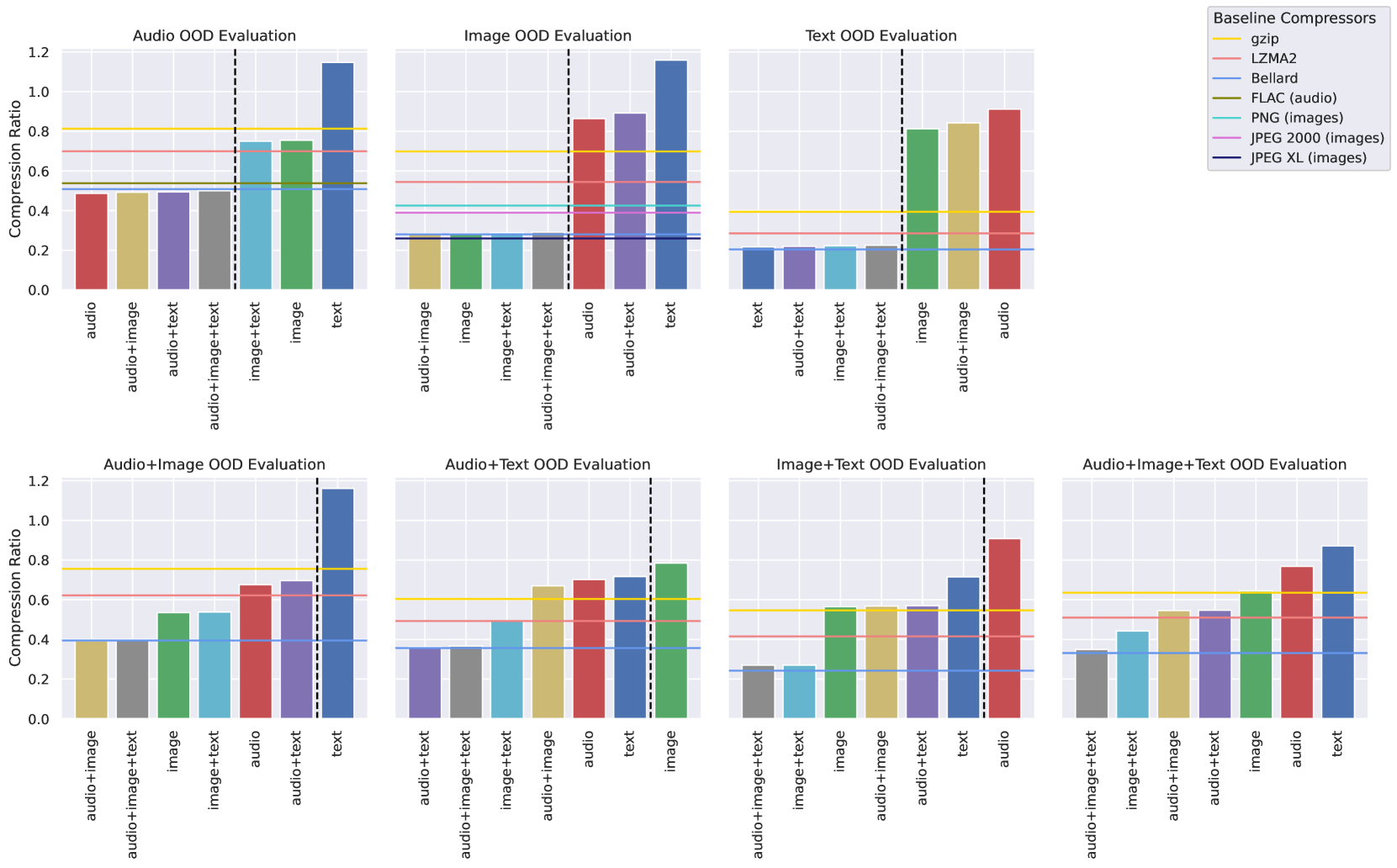
本文研究了使用预训练Transformer模型进行数据压缩的方法。虽然大型Foundation模型具有强大的压缩能力,但考虑到其参数规模,压缩率通常不如标准压缩算法。简单地减少参数量会损害预测性能,从而降低压缩效果。本文通过大规模实验,探索了预训练Transformer在实现有竞争力的压缩率方面的潜力。作者在165GB的原始字节序列(包括文本、图像和音频数据及其组合)上训练模型,并在每种模态的1GB OOD数据上进行压缩测试。结果表明,相对较小的模型(数百万参数)可以优于通用压缩算法(gzip、LZMA2)甚至特定领域压缩器(PNG、JPEG-XL、FLAC),即使考虑参数大小。例如,在OOD音频数据上实现了0.49的最低压缩率(FLAC为0.54)。通过消融实验和超参数搜索,研究了模型和数据集规模的影响,以及单模态与多模态训练的效果。研究发现,即使是小型模型也可以在多种模态上表现良好,但与大型Foundation模型不同,迁移到未见模态的能力较弱。
🔬 方法详解
问题定义:现有Foundation模型虽然具备强大的数据压缩能力,但其庞大的参数规模导致整体压缩效率不高,难以超越传统的压缩算法。简单地减少模型参数虽然可以降低模型大小,但会显著降低模型的预测能力,进而影响压缩性能。因此,如何在模型大小和压缩性能之间取得平衡是一个关键问题。
核心思路:本文的核心思路是利用预训练的Transformer模型,通过在大量多模态数据上进行训练,学习到数据中的通用表示,从而实现高效的数据压缩。通过控制模型的大小,在预测精度和模型大小之间找到一个最佳平衡点,使得模型在压缩性能上能够超越传统的压缩算法。
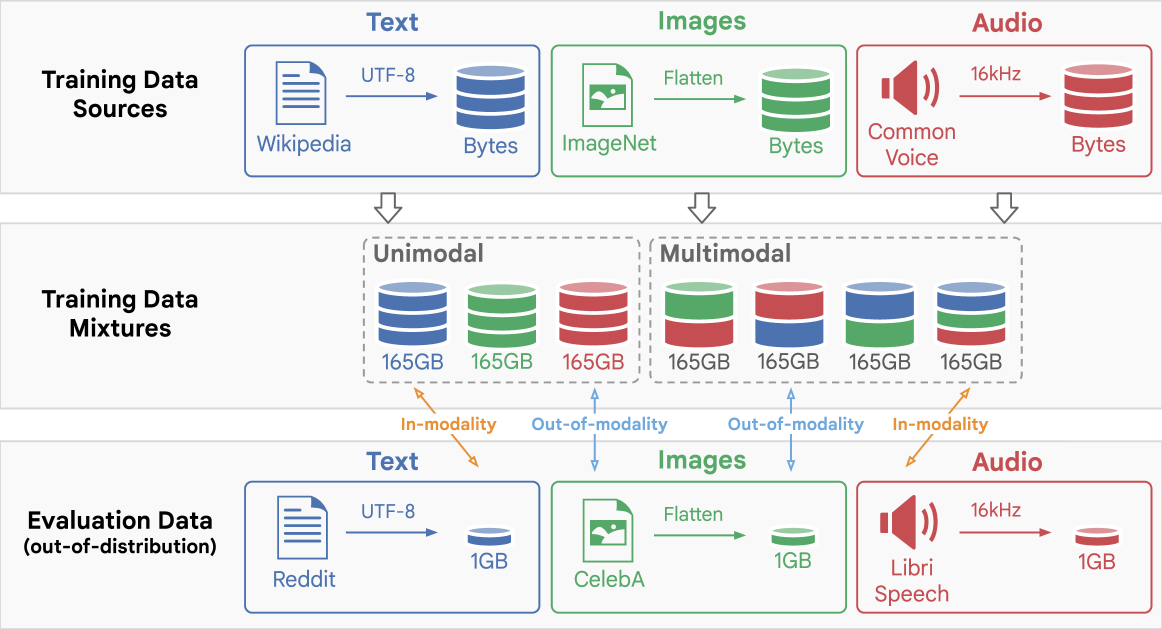
技术框架:该研究采用标准的Transformer架构作为基础模型。训练过程包括在165GB的原始字节序列数据上进行预训练,这些数据涵盖文本、图像和音频三种模态及其所有可能的组合。训练完成后,使用训练好的模型对1GB的OOD数据进行压缩测试。通过比较不同模型大小、训练数据模态以及超参数设置下的压缩性能,来评估模型的压缩能力。
关键创新:该研究的关键创新在于探索了小型预训练Transformer模型在数据压缩方面的潜力,并证明了即使是参数量较小的模型,在经过适当的训练后,也可以在多种模态的数据上实现优于传统压缩算法的压缩性能。此外,研究还探讨了多模态训练对模型压缩性能的影响,并发现虽然小型模型在多模态数据上表现良好,但其跨模态迁移能力较弱。
关键设计:研究中涉及的关键设计包括:模型大小的选择(数百万参数级别),训练数据集的规模(165GB),训练数据的模态组合(文本、图像、音频及其组合),以及超参数的调整。此外,研究还采用了标准的字节级别的数据表示方法,使得模型可以直接处理原始的字节序列数据,而无需进行复杂的预处理。
🖼️ 关键图片
📊 实验亮点
实验结果表明,相对较小的Transformer模型(数百万参数)在OOD数据上的压缩性能优于传统的通用压缩算法(gzip、LZMA2)和特定领域压缩器(PNG、JPEG-XL、FLAC)。例如,在OOD音频数据上,该方法实现了0.49的最低压缩率,而FLAC的压缩率为0.54。这表明预训练Transformer在数据压缩方面具有巨大的潜力。
🎯 应用场景
该研究成果可应用于各种需要高效数据压缩的场景,例如音视频存储与传输、图像压缩、文本压缩等。通过使用小型预训练Transformer模型,可以在保证压缩性能的同时,降低存储和计算成本,尤其适用于资源受限的设备和应用。未来的研究可以进一步探索如何提高模型的跨模态迁移能力,以及如何将该方法应用于更广泛的数据类型。
📄 摘要(原文)
Foundation models are strong data compressors, but when accounting for their parameter size, their compression ratios are inferior to standard compression algorithms. Naively reducing the parameter count does not necessarily help as it deteriorates predictions and, accordingly, compression. We conduct a large-scale empirical study to find a sweet spot where pre-trained vanilla transformers can achieve competitive compression ratios. To this end, we train models on 165GB of raw byte sequences of either text, image, or audio data (and all possible combinations of the three) and then compress 1GB of out-of-distribution (OOD) data from each modality. We find that relatively small models (millions of parameters) can outperform standard general-purpose compression algorithms (gzip, LZMA2) and even domain-specific compressors (PNG, JPEG-XL, FLAC) $\unicode{x2013}$ even when accounting for parameter size. We achieve, e.g., the lowest compression ratio of 0.49 on OOD audio data (vs. 0.54 for FLAC). We conduct extensive ablations and hyperparameter sweeps to study the impact of model- and dataset scale, and we investigate the effect of unimodal versus multimodal training. We find that even small models can be trained to perform well on multiple modalities, but unlike large-scale foundation models, transfer to unseen modalities is generally weak.