Continuous Approximations for Improving Quantization Aware Training of LLMs
作者: He Li, Jianhang Hong, Yuanzhuo Wu, Snehal Adbol, Zonglin Li
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-10-06
💡 一句话要点
提出连续近似方法,提升LLM量化感知训练的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 量化感知训练 大型语言模型 模型压缩 连续近似 直通估计器
📋 核心要点
- 现有量化感知训练(QAT)依赖直通估计器(STE)近似舍入和钳位函数,导致梯度估计不准确,影响模型性能。
- 论文提出两种连续近似方法,平滑舍入和钳位函数,以提供更准确的梯度信息,从而优化量化模型的训练。
- 实验表明,该方法在WikiText-v2、BoolQ和MMLU数据集上均取得了显著的性能提升,验证了其有效性。
📝 摘要(中文)
本文提出了一种改进大型语言模型(LLM)量化感知训练(QAT)的方法,旨在降低量化带来的性能下降。该方法通过引入两种连续近似来优化QAT过程中的舍入函数和钳位函数,传统上这些函数使用直通估计器(STE)进行近似。实验结果表明,在WikiText-v2数据集上,量化模型的困惑度(PPL)达到9.0815,优于基线的9.9621。此外,在BoolQ上实现了2.76%的改进,在MMLU上实现了5.47%的改进。这些结果证明,使用该方法可以更准确地学习步长和权重。该方法在相同的精度、模型大小和训练设置下实现了更好的性能,有助于开发更节能的LLM技术,符合全球可持续发展目标。
🔬 方法详解
问题定义:大型语言模型(LLMs)的量化感知训练(QAT)旨在压缩模型大小并降低计算成本。然而,QAT过程中对量化操作(如舍入和钳位)的不可微性处理,通常采用直通估计器(STE),导致梯度估计不准确,影响量化模型的性能。现有方法难以在量化后保持模型精度,尤其是在低比特量化时,性能下降更为明显。
核心思路:论文的核心思路是通过引入连续可微的函数来近似舍入和钳位操作,从而避免使用STE带来的梯度估计问题。通过使用连续近似,可以更准确地计算梯度,从而优化量化模型的权重和步长,最终提高量化模型的性能。这种方法旨在弥合量化操作的不可微性与梯度优化之间的差距。
技术框架:该方法主要包含以下几个阶段:首先,使用浮点模型进行预训练;然后,在QAT过程中,将原有的舍入和钳位操作替换为提出的连续近似函数;接着,使用标准的反向传播算法计算梯度并更新模型参数;最后,将模型量化为目标比特数。整体流程与标准的QAT类似,但关键在于使用连续近似函数替代了STE。
关键创新:最重要的技术创新点在于提出了两种连续近似函数,分别用于替代舍入和钳位操作。这些连续近似函数是可微的,允许更准确的梯度计算,从而避免了STE带来的梯度偏差问题。与现有方法使用STE的硬截断不同,该方法通过平滑的连续函数来模拟量化过程,从而更好地适应梯度优化。
关键设计:具体而言,论文设计了可微的函数来近似rounding和clamping操作。这些函数通常包含可学习的参数,例如温度参数,用于控制近似的平滑程度。损失函数与标准QAT相同,但由于梯度的改进,可以更有效地优化模型。网络结构保持不变,该方法可以应用于各种LLM架构。
🖼️ 关键图片
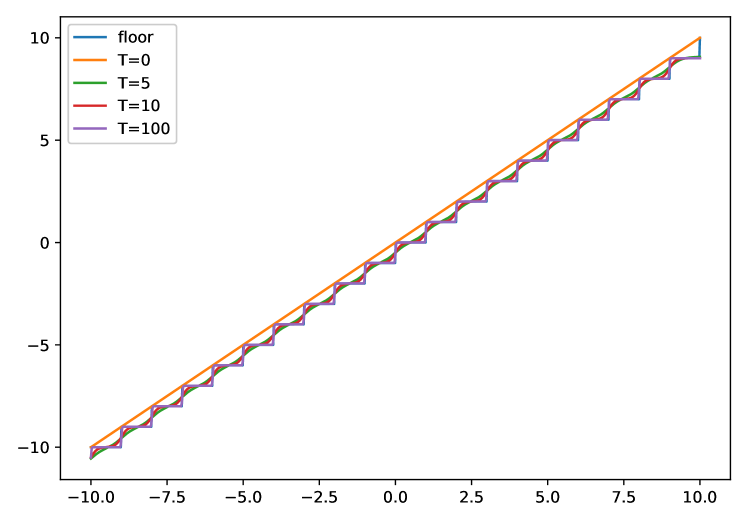

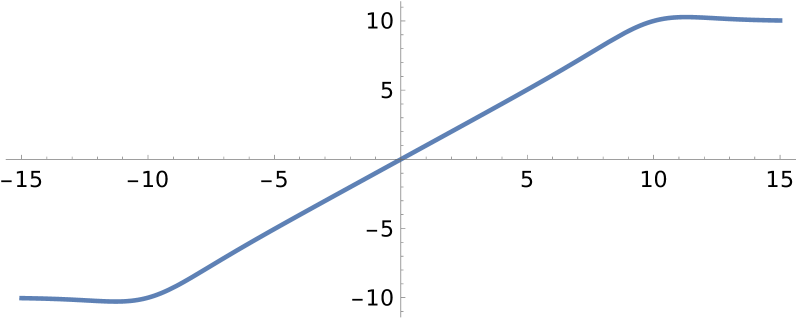
📊 实验亮点
实验结果表明,该方法在WikiText-v2数据集上将量化模型的困惑度(PPL)从基线的9.9621降低到9.0815,实现了显著的性能提升。此外,在BoolQ上获得了2.76%的改进,在MMLU上获得了5.47%的改进。这些结果表明,该方法能够有效地提高量化模型的精度,使其在各种下游任务中表现更好。
🎯 应用场景
该研究成果可广泛应用于对计算资源和能耗有严格要求的场景,例如移动设备、边缘计算和嵌入式系统。通过提高量化模型的性能,可以部署更小、更快的LLM,从而在资源受限的环境中实现更强大的AI应用。这对于推动人工智能在物联网、自动驾驶和智能家居等领域的普及具有重要意义。
📄 摘要(原文)
Model compression methods are used to reduce the computation and energy requirements for Large Language Models (LLMs). Quantization Aware Training (QAT), an effective model compression method, is proposed to reduce performance degradation after quantization. To further minimize this degradation, we introduce two continuous approximations to the QAT process on the rounding function, traditionally approximated by the Straight-Through Estimator (STE), and the clamping function. By applying both methods, the perplexity (PPL) on the WikiText-v2 dataset of the quantized model reaches 9.0815, outperforming 9.9621 by the baseline. Also, we achieve a 2.76% improvement on BoolQ, and a 5.47% improvement on MMLU, proving that the step sizes and weights can be learned more accurately with our approach. Our method achieves better performance with the same precision, model size, and training setup, contributing to the development of more energy-efficient LLMs technology that aligns with global sustainability goals.