Improving LLM Reasoning through Scaling Inference Computation with Collaborative Verification
作者: Zhenwen Liang, Ye Liu, Tong Niu, Xiangliang Zhang, Yingbo Zhou, Semih Yavuz
分类: cs.LG, cs.AI
发布日期: 2024-10-05
💡 一句话要点
提出协同验证方法,通过扩展推理计算提升LLM在复杂推理任务中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理验证 思维链 程序思维 协同验证 数学推理 代码推理
📋 核心要点
- 现有LLM在复杂推理任务中表现不佳,原因在于其训练数据主要为正确答案,缺乏从错误中学习的能力。
- 该论文通过生成多条推理路径,并训练验证器对这些路径的正确性进行评估和排序,从而提升LLM的推理能力。
- 实验结果表明,该方法在GSM8k和MATH等基准测试中取得了SOTA结果,甚至超越了GPT-4o。
📝 摘要(中文)
大型语言模型(LLM)在通用能力方面取得了显著进展,但在持续和准确的推理方面仍然面临挑战,尤其是在数学和代码推理等复杂任务中。一个关键限制是LLM主要在正确的解决方案上进行训练,降低了它们检测和从错误中学习的能力,这阻碍了它们可靠地验证和排序输出。为了解决这个问题,我们通过生成多个推理路径并采用验证器来评估和排序生成的输出的正确性,从而扩大了推理时的计算量。为此,我们引入了一个综合数据集,其中包含由多个LLM生成的数学和代码任务的正确和不正确的解决方案。这种多样化的解决方案集使验证器能够更有效地从错误输出中区分和排序正确答案。基于对现有方法的广泛比较,选择了构建验证器的训练方法。此外,为了利用不同推理策略的独特优势,我们提出了一种新颖的协作方法,该方法集成了思维链(CoT)和程序思维(PoT)解决方案以进行验证。CoT提供了清晰的、逐步的推理过程,增强了可解释性,而PoT是可执行的,提供了精确且对错误敏感的验证机制。通过结合两者的优势,我们的方法显着提高了推理验证的准确性和可靠性。我们的验证器Math-Rev和Code-Rev证明了对现有LLM的显着性能提升,在GSM8k和MATH等基准测试中取得了最先进的结果,甚至在使用Qwen-72B-Instruct作为推理器的情况下优于GPT-4o。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在复杂推理任务中,尤其是数学和代码推理任务中,推理准确性和一致性不足的问题。现有的LLM主要基于正确答案进行训练,导致其缺乏有效识别和纠正错误的能力,从而限制了其在复杂推理场景下的应用。
核心思路:论文的核心思路是通过扩展推理时的计算量,生成多个推理路径,并训练专门的验证器来评估和排序这些推理路径的正确性。通过引入包含正确和错误答案的数据集,使验证器能够学习区分正确和错误的推理过程,从而提高整体推理的准确性和可靠性。
技术框架:该方法包含以下主要模块:1) 使用多个LLM生成数学和代码任务的多种解决方案,包括正确和错误的答案;2) 构建包含多样化解决方案的数据集,用于训练验证器;3) 训练验证器(Math-Rev和Code-Rev)来评估和排序生成的推理路径;4) 采用协同验证方法,整合思维链(CoT)和程序思维(PoT)的优势,以提高验证的准确性。
关键创新:该论文的关键创新在于:1) 构建了一个包含正确和错误答案的综合数据集,用于训练验证器;2) 提出了一种协同验证方法,结合了CoT的可解释性和PoT的可执行性,从而提高了验证的准确性;3) 通过扩展推理计算,生成多个推理路径,并利用验证器进行评估和排序,从而提升了LLM的推理能力。
关键设计:论文的关键设计包括:1) 数据集的构建,需要保证包含足够数量的正确和错误答案,并且答案的多样性;2) 验证器的训练方法,需要选择合适的模型和损失函数,以提高验证器的准确性;3) 协同验证方法的实现,需要合理地整合CoT和PoT的输出,以提高验证的可靠性。具体参数设置和网络结构等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
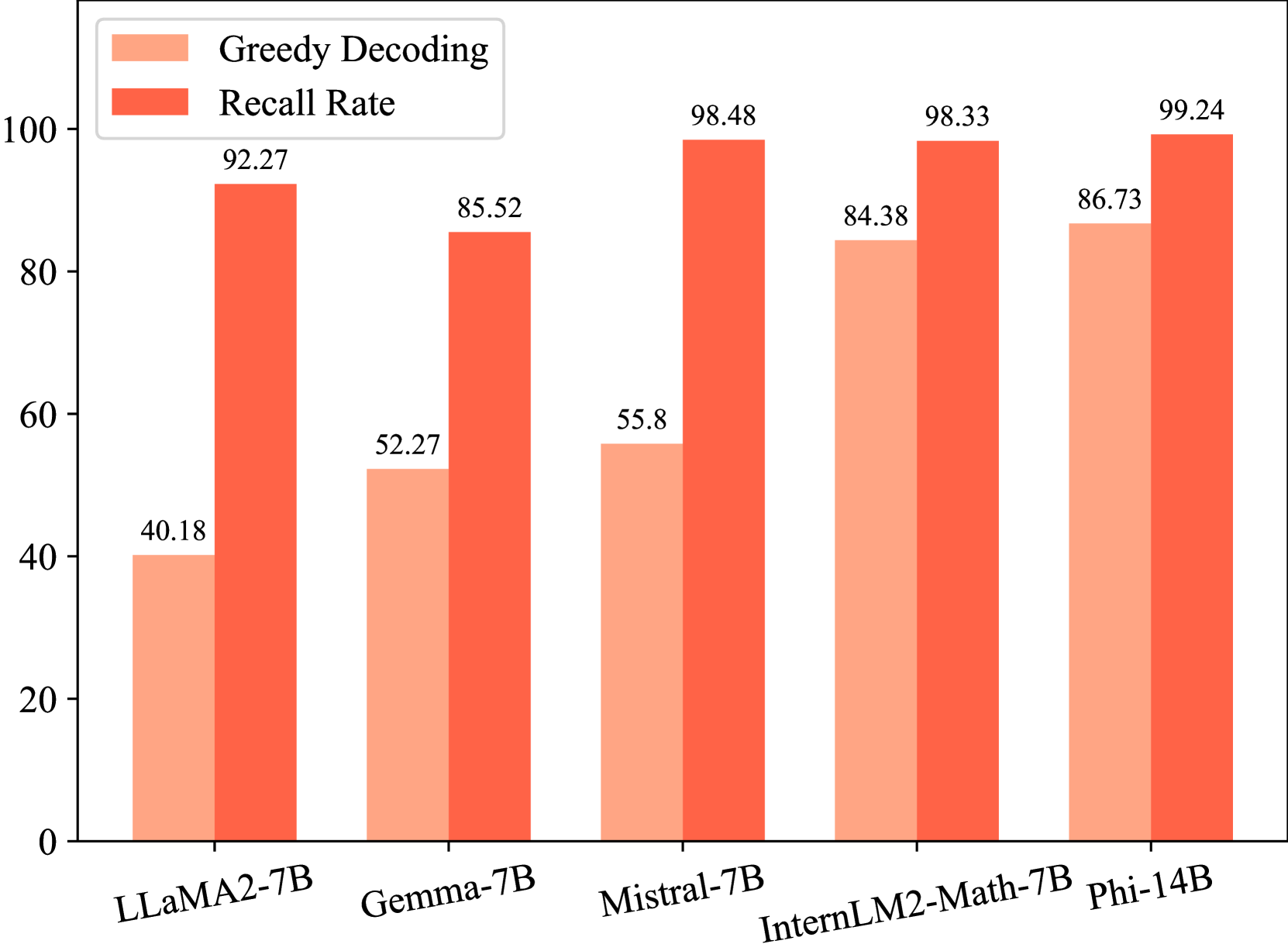


📊 实验亮点
实验结果表明,该方法在GSM8k和MATH等基准测试中取得了显著的性能提升,达到了SOTA水平。具体而言,使用Qwen-72B-Instruct作为推理器时,该方法甚至超越了GPT-4o。Math-Rev和Code-Rev验证器能够有效区分正确和错误的推理路径,从而提高了整体推理的准确性。
🎯 应用场景
该研究成果可应用于需要高精度推理的领域,如金融分析、科学研究、软件开发等。通过提高LLM的推理准确性和可靠性,可以减少人工干预,提高工作效率,并为决策提供更可靠的支持。未来,该方法可以进一步扩展到其他复杂推理任务,并与其他技术相结合,以实现更强大的AI系统。
📄 摘要(原文)
Despite significant advancements in the general capability of large language models (LLMs), they continue to struggle with consistent and accurate reasoning, especially in complex tasks such as mathematical and code reasoning. One key limitation is that LLMs are trained primarily on correct solutions, reducing their ability to detect and learn from errors, which hampers their ability to reliably verify and rank outputs. To address this, we scale up the inference-time computation by generating multiple reasoning paths and employing verifiers to assess and rank the generated outputs by correctness. To facilitate this, we introduce a comprehensive dataset consisting of correct and incorrect solutions for math and code tasks, generated by multiple LLMs. This diverse set of solutions enables verifiers to more effectively distinguish and rank correct answers from erroneous outputs. The training methods for building verifiers were selected based on an extensive comparison of existing approaches. Moreover, to leverage the unique strengths of different reasoning strategies, we propose a novel collaborative method integrating Chain-of-Thought (CoT) and Program-of-Thought (PoT) solutions for verification. CoT provides a clear, step-by-step reasoning process that enhances interpretability, while PoT, being executable, offers a precise and error-sensitive validation mechanism. By taking both of their strengths, our approach significantly improves the accuracy and reliability of reasoning verification. Our verifiers, Math-Rev and Code-Rev, demonstrate substantial performance gains to existing LLMs, achieving state-of-the-art results on benchmarks such as GSM8k and MATH and even outperforming GPT-4o with Qwen-72B-Instruct as the reasoner.