A Survey on LLM-based Code Generation for Low-Resource and Domain-Specific Programming Languages
作者: Sathvik Joel, Jie JW Wu, Fatemeh H. Fard
分类: cs.SE, cs.LG
发布日期: 2024-10-04 (更新: 2025-09-26)
备注: 64 pages, 3 figures, 15 tables. Accepted in ACM Transactions on Software Engineering and Methodology (TOSEM)
💡 一句话要点
针对低资源和领域特定编程语言,综述基于LLM的代码生成方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 低资源编程语言 领域特定语言 软件工程 综述 基准数据集
📋 核心要点
- 现有LLM在通用编程语言的代码生成上表现出色,但在低资源和领域特定语言上效果不佳,主要原因是数据稀缺和特定语法。
- 该综述系统性地回顾了利用LLM进行低资源和领域特定语言代码生成的研究现状、方法和挑战,填补了现有研究的空白。
- 通过筛选大量文献,论文总结了LLM在这些语言上的能力、局限性、评估技术、性能提升策略以及数据集构建方法。
📝 摘要(中文)
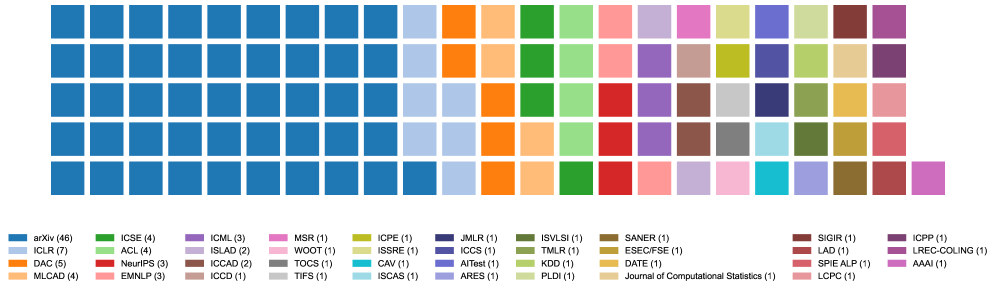
大型语言模型(LLM)在流行编程语言的代码生成方面表现出令人印象深刻的能力。然而,它们在低资源编程语言(LRPL)和领域特定语言(DSL)上的性能仍然是一个重大挑战,影响了数百万开发者——仅Rust就有350万用户——他们无法充分利用LLM的能力。LRPL和DSL面临独特的障碍,包括数据稀缺,以及对于DSL而言,通用数据集中缺乏充分表示的专门语法。解决这些挑战至关重要,因为LRPL和DSL提高了金融和科学等专门领域的开发效率。虽然一些综述讨论了LLM在软件工程中的应用,但没有一个专门关注与LRPL和DSL相关的挑战和机遇。本综述通过系统地回顾当前状态、方法和挑战,填补了这一空白,旨在利用LLM在这些语言中进行代码生成。我们从2020年至2024年间发表的超过27,000项研究中筛选出111篇论文,以评估LLM在LRPL和DSL中的能力和局限性。我们报告了所使用的LLM、基准和评估指标、提高性能的策略以及数据集收集和管理的方法。我们确定了四种主要的评估技术和几种用于评估LRPL和DSL中代码生成的指标。我们的分析将改进方法分为六类,并总结了研究人员提出的新颖架构。尽管有各种技术和指标,但缺乏用于评估LRPL和DSL中代码生成的标准方法和基准数据集。本综述为LLM、软件工程和专用编程语言交叉领域的研究人员和从业人员提供了一个资源,为未来LRPL和DSL代码生成方面的进展奠定了基础。
🔬 方法详解
问题定义:论文旨在解决LLM在低资源编程语言(LRPL)和领域特定语言(DSL)代码生成方面表现不佳的问题。现有方法在这些语言上由于数据稀缺和特定语法的缺乏,导致LLM无法有效学习和生成代码,严重限制了LLM在这些领域的应用。
核心思路:论文的核心思路是对现有研究进行系统性的梳理和总结,分析LLM在LRPL和DSL代码生成中面临的挑战,并归纳已有的解决方案和评估方法。通过对现有方法的分类和比较,为未来的研究提供指导和借鉴。
技术框架:该论文是一个综述性质的研究,其技术框架主要包括以下几个阶段:1) 文献检索:从大量已发表的论文中筛选出与LLM在LRPL和DSL代码生成相关的研究。2) 文献分类:对筛选出的文献进行分类,例如按照评估方法、性能提升策略、数据集构建方法等进行分类。3) 总结分析:对不同类别的方法进行总结和分析,找出其优缺点和适用场景。4) 提出挑战:基于现有研究的不足,提出未来研究需要解决的挑战。
关键创新:该论文的创新点在于它是第一个专门针对LLM在LRPL和DSL代码生成方面的综述。之前的综述主要关注LLM在通用编程语言上的应用,而忽略了LRPL和DSL的特殊性。该论文填补了这一空白,为研究人员提供了一个全面的了解LLM在这些语言上应用的资源。
关键设计:论文的关键设计在于其文献筛选和分类的标准。论文从2020年至2024年间发表的超过27,000项研究中筛选出111篇论文,并根据LLM的使用情况、基准、评估指标、性能提升策略以及数据集收集和管理方法对这些论文进行了分类。这种分类方法能够帮助研究人员快速找到自己感兴趣的研究方向。
🖼️ 关键图片
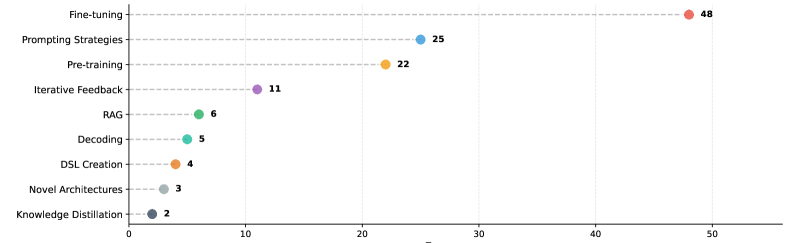
📊 实验亮点
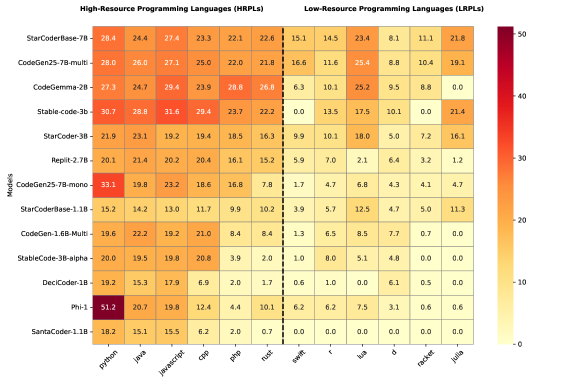
该综述筛选并分析了111篇相关论文,总结了四种主要的评估技术和多种评估指标,并将性能改进方法分为六类。研究强调,目前缺乏用于评估LRPL和DSL代码生成的标准方法和基准数据集,这为未来的研究指明了方向。
🎯 应用场景
该研究成果可应用于各种需要使用低资源或领域特定编程语言的场景,例如嵌入式系统开发、科学计算、金融建模等。通过提升LLM在这些语言上的代码生成能力,可以显著提高开发效率,降低开发成本,并促进这些领域的技术创新。
📄 摘要(原文)
Large Language Models (LLMs) have shown impressive capabilities in code generation for popular programming languages. However, their performance on Low-Resource Programming Languages (LRPLs) and Domain-Specific Languages (DSLs) remains a significant challenge, affecting millions of developers-3.5 million users in Rust alone-who cannot fully utilize LLM capabilities. LRPLs and DSLs encounter unique obstacles, including data scarcity and, for DSLs, specialized syntax that is poorly represented in general-purpose datasets. Addressing these challenges is crucial, as LRPLs and DSLs enhance development efficiency in specialized domains, such as finance and science. While several surveys discuss LLMs in software engineering, none focus specifically on the challenges and opportunities associated with LRPLs and DSLs. Our survey fills this gap by systematically reviewing the current state, methodologies, and challenges in leveraging LLMs for code generation in these languages. We filtered 111 papers from over 27,000 published studies between 2020 and 2024 to evaluate the capabilities and limitations of LLMs in LRPLs and DSLs. We report the LLMs used, benchmarks, and metrics for evaluation, strategies for enhancing performance, and methods for dataset collection and curation. We identified four main evaluation techniques and several metrics for assessing code generation in LRPLs and DSLs. Our analysis categorizes improvement methods into six groups and summarizes novel architectures proposed by researchers. Despite various techniques and metrics, a standard approach and benchmark dataset for evaluating code generation in LRPLs and DSLs are lacking. This survey serves as a resource for researchers and practitioners at the intersection of LLMs, software engineering, and specialized programming languages, laying the groundwork for future advancements in code generation for LRPLs and DSLs.