Learning Code Preference via Synthetic Evolution
作者: Jiawei Liu, Thanh Nguyen, Mingyue Shang, Hantian Ding, Xiaopeng Li, Yu Yu, Varun Kumar, Zijian Wang
分类: cs.LG, cs.CL, cs.SE
发布日期: 2024-10-04 (更新: 2024-10-23)
💡 一句话要点
提出CodeFavor框架,通过合成进化数据学习代码偏好,提升代码生成质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码偏好学习 合成数据 代码进化 代码评审 大型语言模型
📋 核心要点
- 现有代码生成评估方法难以同时兼顾代码的良好属性和开发者偏好,缺乏有效对齐。
- CodeFavor通过合成进化数据学习代码偏好,利用代码提交和评论信息训练偏好模型。
- 实验表明,CodeFavor显著提升代码偏好预测准确性,并能以更低成本匹配更大模型的性能。
📝 摘要(中文)
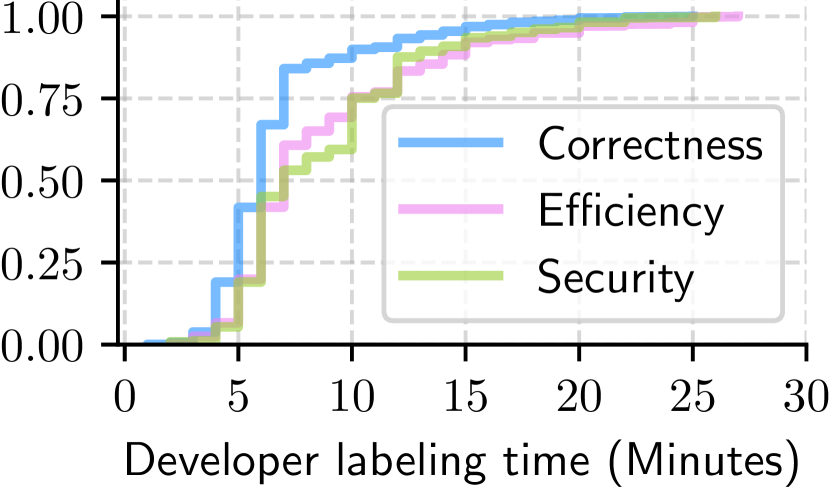
大型语言模型(LLMs)最近展示了卓越的编码能力。然而,评估基于良好形式属性的代码生成并使其与开发者偏好对齐仍然具有挑战性。在本文中,我们探索了代码偏好学习这一新挑战下的两个关键问题:(i) 我们如何训练模型来预测有意义的代码偏好?(ii) 人类和LLM的偏好如何与可验证的代码属性和开发者代码品味对齐?为此,我们提出了CodeFavor,一个从合成进化数据(包括代码提交和代码评论)中训练成对代码偏好模型的框架。为了评估代码偏好,我们引入了CodePrefBench,一个包含1364个严格策划的代码偏好任务的基准,涵盖了三个可验证的属性——正确性、效率和安全性——以及人类偏好。我们的评估表明,CodeFavor全面提高了基于模型的代码偏好的准确性,最高可达28.8%。同时,CodeFavor模型可以匹配参数量是其6-9倍的模型的性能,同时成本效益提高了34倍。我们还通过一套全面的受控实验,严格验证了CodeFavor中的设计选择。此外,我们发现了基于人类的代码偏好的高昂成本和局限性:尽管在每个任务上花费了23.4人-分钟,但仍有15.1-40.3%的任务未解决。与基于模型的偏好相比,人类偏好在代码正确性的目标下往往更准确,但在非功能性目标方面则次优。
🔬 方法详解
问题定义:现有代码生成模型评估和优化方法,难以有效捕捉开发者对代码的偏好,尤其是在正确性之外的效率、安全性等非功能性属性上。人工标注代码偏好成本高昂且存在主观性偏差,难以大规模应用。
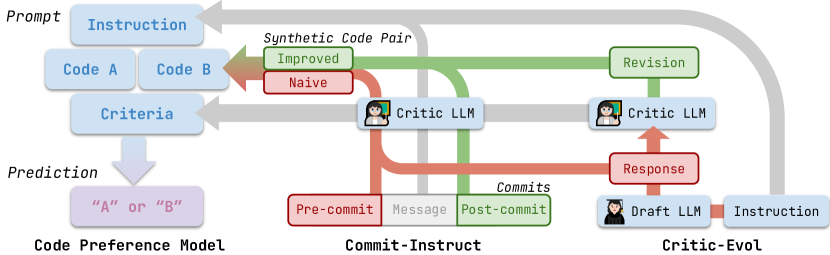
核心思路:利用代码的进化历史(commit记录)和代码评审信息,构建合成数据来训练代码偏好模型。核心假设是,代码的演进方向和评审意见反映了开发者对代码质量和风格的偏好。通过学习这些偏好,可以更准确地评估和改进代码生成模型。
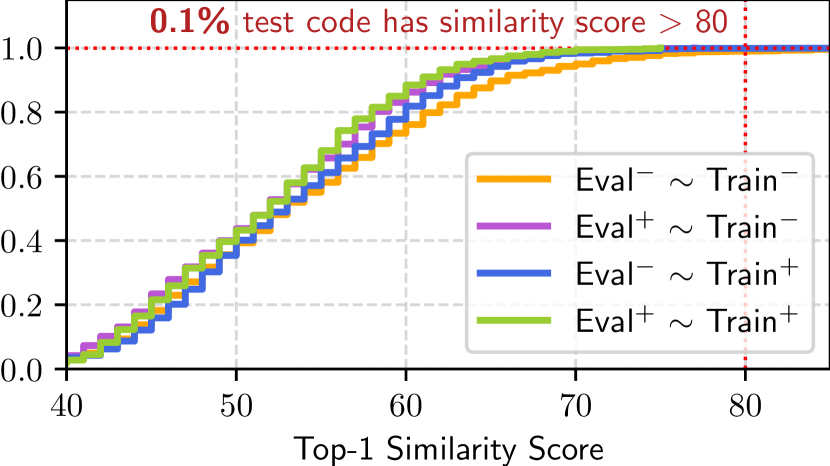
技术框架:CodeFavor框架包含以下几个主要阶段:1) 数据合成:从代码仓库中提取代码提交历史和评审信息,构建包含代码片段、修改和评审意见的数据集。2) 偏好建模:使用Transformer等模型,学习代码片段之间的偏好关系。输入是两个代码片段,输出是哪个片段更符合开发者偏好。3) 偏好评估:使用CodePrefBench基准评估模型预测代码偏好的准确性。CodePrefBench包含多个代码偏好任务,涵盖正确性、效率和安全性等属性。
关键创新:CodeFavor的关键创新在于利用合成进化数据来学习代码偏好。与传统的依赖人工标注的方法相比,CodeFavor可以更高效、更客观地获取代码偏好信息。此外,CodeFavor还提出了CodePrefBench基准,为代码偏好学习的研究提供了一个统一的评估平台。
关键设计:CodeFavor使用成对排序损失函数(pairwise ranking loss)来训练偏好模型。具体来说,对于每个代码偏好任务,模型需要预测哪个代码片段更符合开发者偏好。损失函数鼓励模型将更符合偏好的代码片段排在前面。此外,CodeFavor还使用了数据增强技术,例如代码片段的随机替换和插入,来提高模型的泛化能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CodeFavor在CodePrefBench基准上显著提高了代码偏好预测的准确性,最高提升达28.8%。CodeFavor模型在性能上可以与参数量是其6-9倍的模型相媲美,同时成本效益提高了34倍。此外,实验还揭示了人工标注代码偏好的局限性,表明模型偏好在非功能性目标上优于人类偏好。
🎯 应用场景
CodeFavor可应用于代码生成模型的评估和优化,帮助模型生成更符合开发者偏好的代码。例如,可以用于代码自动补全、代码修复、代码重构等任务。此外,CodeFavor还可以用于代码质量评估和代码风格规范化,提高软件开发效率和代码可维护性。
📄 摘要(原文)
Large Language Models (LLMs) have recently demonstrated remarkable coding capabilities. However, assessing code generation based on well-formed properties and aligning it with developer preferences remains challenging. In this paper, we explore two key questions under the new challenge of code preference learning: (i) How do we train models to predict meaningful preferences for code? and (ii) How do human and LLM preferences align with verifiable code properties and developer code tastes? To this end, we propose CodeFavor, a framework for training pairwise code preference models from synthetic evolution data, including code commits and code critiques. To evaluate code preferences, we introduce CodePrefBench, a benchmark comprising 1364 rigorously curated code preference tasks to cover three verifiable properties-correctness, efficiency, and security-along with human preference. Our evaluation shows that CodeFavor holistically improves the accuracy of model-based code preferences by up to 28.8%. Meanwhile, CodeFavor models can match the performance of models with 6-9x more parameters while being 34x more cost-effective. We also rigorously validate the design choices in CodeFavor via a comprehensive set of controlled experiments. Furthermore, we discover the prohibitive costs and limitations of human-based code preference: despite spending 23.4 person-minutes on each task, 15.1-40.3% of tasks remain unsolved. Compared to model-based preference, human preference tends to be more accurate under the objective of code correctness, while being sub-optimal for non-functional objectives.