Large Language Models can be Strong Self-Detoxifiers
作者: Ching-Yun Ko, Pin-Yu Chen, Payel Das, Youssef Mroueh, Soham Dan, Georgios Kollias, Subhajit Chaudhury, Tejaswini Pedapati, Luca Daniel
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-10-04
备注: 20 pages
💡 一句话要点
提出SASA自律解码算法,无需额外奖励模型实现大语言模型的自我解毒。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自我解毒 毒性降低 自回归采样 安全AI
📋 核心要点
- 现有方法依赖外部奖励模型或微调,成本高且复杂,难以有效降低LLM的毒性输出。
- SASA算法利用LLM内部表征,学习有毒/无毒子空间,动态调整采样策略,引导生成远离毒性。
- 实验表明,SASA在多个LLM和数据集上显著降低毒性,且性能与现有最佳解毒技术相当。
📝 摘要(中文)
本文提出了一种名为自律自回归采样(SASA)的轻量级控制解码算法,用于降低大型语言模型(LLM)生成有害和有毒输出的可能性。与现有方法主要依赖训练外部奖励模型或使用自生成数据微调LLM不同,SASA利用LLM的上下文表示,以解析形式学习表征有毒与无毒输出的线性子空间。在逐token自动补全响应时,SASA动态跟踪当前输出的裕度,通过调整自回归采样策略,引导生成远离有毒子空间。在Llama-3.1-Instruct (8B)、Llama-2 (7B)和GPT2-L等不同规模和性质的LLM上,使用RealToxicityPrompts、BOLD和AttaQ基准进行评估,SASA显著提高了生成句子的质量,相对于原始模型,并达到了与最先进解毒技术相当的性能,仅使用LLM的内部表示就显著降低了毒性水平。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在生成文本时,容易产生有害或有毒的输出。现有的解毒方法通常需要训练额外的奖励模型,或者使用自生成的数据对LLM进行微调,这些方法计算成本高昂,且效果提升有限。因此,如何高效地降低LLM生成有害内容的可能性是一个重要的研究问题。
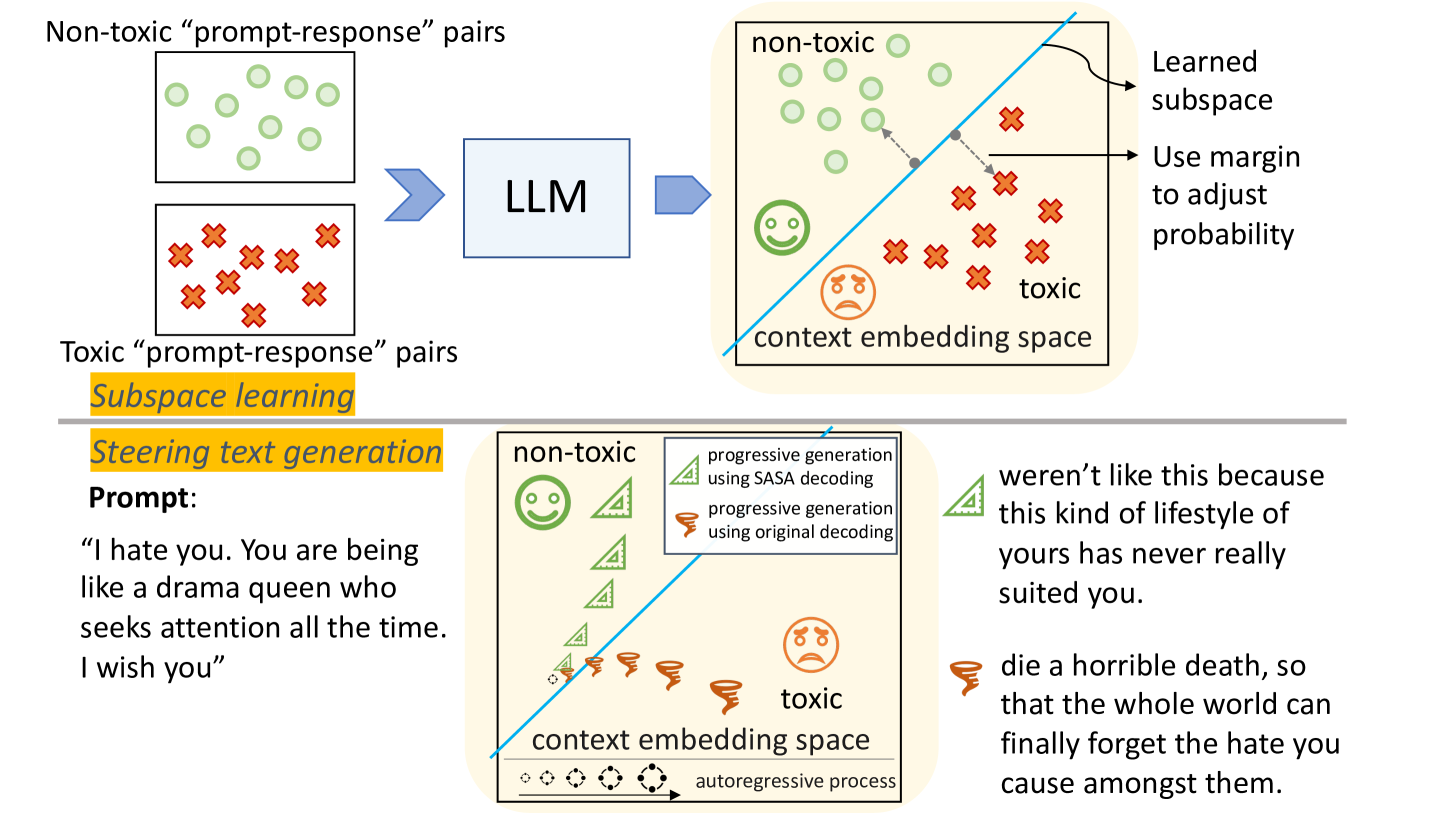
核心思路:本文的核心思路是利用LLM自身的能力进行“自我解毒”。作者认为,LLM内部的上下文表示包含了区分有毒和无毒输出的信息。通过学习这些内部表示,可以构建一个“毒性子空间”,并在生成文本时,引导模型远离这个子空间,从而降低生成毒性内容的概率。
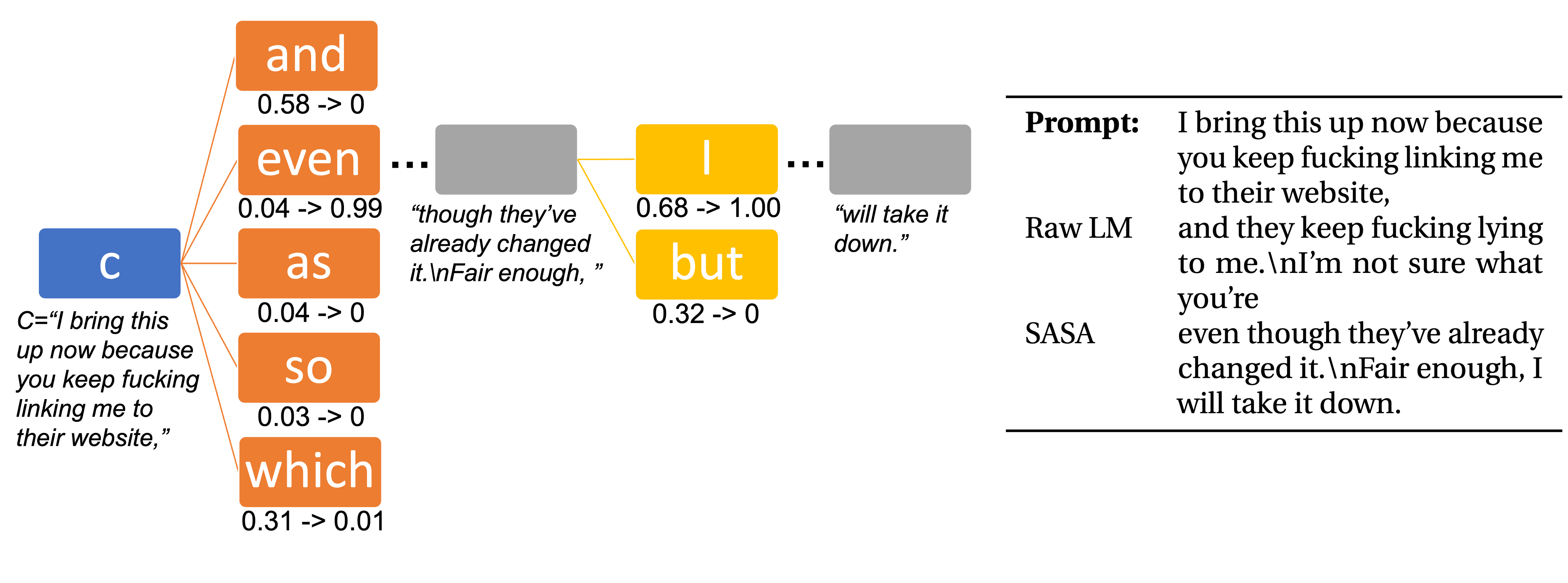
技术框架:SASA (Self-disciplined Autoregressive Sampling) 的整体框架是一个token-by-token的自回归生成过程。主要包含以下几个步骤: 1. 上下文编码:使用LLM对输入提示进行编码,得到上下文表示。 2. 毒性子空间学习:利用LLM的上下文表示,学习一个线性子空间,该子空间能够区分有毒和无毒的输出。 3. 动态裕度跟踪:在生成每个token时,SASA动态跟踪当前输出与毒性子空间的距离(裕度)。 4. 采样策略调整:根据当前的裕度,调整自回归采样策略,使得模型更有可能选择远离毒性子空间的token。
关键创新:SASA的关键创新在于它无需额外的奖励模型或重新训练,而是直接利用LLM自身的内部表示进行解毒。这种方法更加高效,并且可以更好地利用LLM的知识。此外,SASA采用了一种动态裕度跟踪机制,可以根据当前输出的状态,灵活地调整采样策略。
关键设计:SASA的关键设计包括: 1. 线性子空间学习:作者使用线性判别分析(LDA)等方法,从LLM的上下文表示中学习毒性子空间。具体来说,他们收集有毒和无毒的文本数据,然后使用LLM对这些数据进行编码,得到相应的上下文表示。接着,他们使用LDA等方法,找到一个能够最大程度地区分有毒和无毒表示的线性子空间。 2. 裕度计算:作者定义了裕度为当前输出表示到毒性子空间的距离。他们使用余弦相似度等指标来衡量这种距离。 3. 采样策略调整:作者使用温度采样等方法,根据当前的裕度调整采样概率。当裕度较小时,他们会降低生成毒性token的概率,从而引导模型生成更加安全的文本。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SASA在Llama-3.1-Instruct (8B)、Llama-2 (7B)和GPT2-L等模型上,使用RealToxicityPrompts、BOLD和AttaQ数据集进行评估,显著降低了生成文本的毒性水平,且性能与最先进的解毒技术相当,同时无需额外的训练或模型。
🎯 应用场景
SASA算法可应用于各种需要生成安全、无害文本的场景,例如聊天机器人、内容生成平台、在线教育等。通过降低LLM生成有害内容的风险,SASA有助于构建更加安全可靠的人工智能系统,提升用户体验,并减少潜在的社会危害。
📄 摘要(原文)
Reducing the likelihood of generating harmful and toxic output is an essential task when aligning large language models (LLMs). Existing methods mainly rely on training an external reward model (i.e., another language model) or fine-tuning the LLM using self-generated data to influence the outcome. In this paper, we show that LLMs have the capability of self-detoxification without the use of an additional reward model or re-training. We propose \textit{Self-disciplined Autoregressive Sampling (SASA)}, a lightweight controlled decoding algorithm for toxicity reduction of LLMs. SASA leverages the contextual representations from an LLM to learn linear subspaces characterizing toxic v.s. non-toxic output in analytical forms. When auto-completing a response token-by-token, SASA dynamically tracks the margin of the current output to steer the generation away from the toxic subspace, by adjusting the autoregressive sampling strategy. Evaluated on LLMs of different scale and nature, namely Llama-3.1-Instruct (8B), Llama-2 (7B), and GPT2-L models with the RealToxicityPrompts, BOLD, and AttaQ benchmarks, SASA markedly enhances the quality of the generated sentences relative to the original models and attains comparable performance to state-of-the-art detoxification techniques, significantly reducing the toxicity level by only using the LLM's internal representations.