Exploring the Limitations of Mamba in COPY and CoT Reasoning
作者: Ruifeng Ren, Zhicong Li, Yong Liu
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-10-04 (更新: 2025-05-29)
备注: Mamba, Chain of Thought
💡 一句话要点
分析Mamba在COPY操作和CoT推理中的局限性,揭示其在特定任务上的性能瓶颈。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Mamba Transformer COPY操作 思维链 动态规划 长序列建模 模型局限性
📋 核心要点
- Transformer在长序列建模中面临推理开销随序列长度线性增长的挑战。
- 论文分析了Mamba在COPY操作和CoT推理中的表达能力,揭示其在特定任务上的局限性。
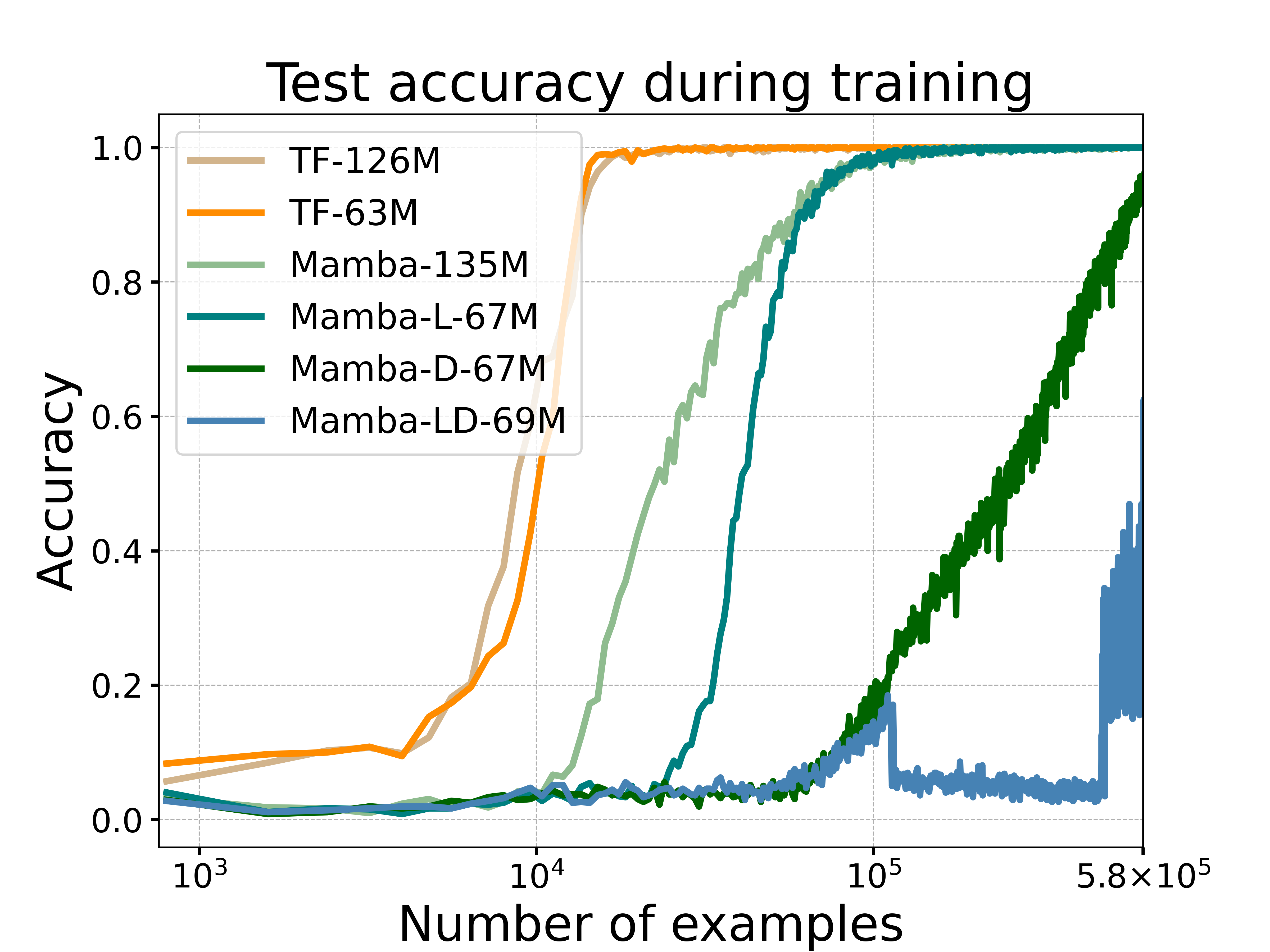
- 实验表明,Mamba在COPY和CoT任务上的性能不如Transformer,尤其是在需要精确复制和复杂推理时。
📝 摘要(中文)
Transformer已成为现代大型语言模型(LLM)的基石;然而,它们的推理开销随着序列长度线性增长,对长序列建模提出了挑战。鉴于此,Mamba因保持恒定的推理大小而备受关注,经验证据表明,它可以在序列建模中与Transformer的性能相匹配,同时显著降低计算成本。然而,一个悬而未决的问题是:Mamba是否总能在实现与Transformer相当的性能的同时带来节省?在本文中,我们重点分析Mamba执行我们定义的COPY操作和思维链(CoT)推理的表达能力。首先,受到Mamba和线性注意力之间联系的启发,我们表明,固定大小的Mamba可能难以执行COPY操作,而Transformer可以更轻松地处理它们。然而,当Mamba的大小随着输入序列长度线性增长时,它可以准确地执行COPY,但在这种情况下,Mamba不再提供开销节省。基于此观察,我们进一步分析了Mamba解决CoT任务的能力,这些任务可以用动态规划(DP)问题来描述。我们的研究结果表明,为了解决任意DP问题,Mamba的总成本仍然与标准Transformer相当。然而,与高效Transformer类似,当面对具有有利属性(如局部性)的DP问题时,Mamba可以节省开销。我们在COPY和CoT任务上的实验进一步证明了Mamba在学习这些任务方面与Transformer相比的局限性。
🔬 方法详解
问题定义:论文旨在研究Mamba模型在处理COPY操作和Chain-of-Thought (CoT) 推理任务时的能力边界。现有的Mamba模型虽然在长序列建模上具有计算效率优势,但其在需要精确信息复制和复杂推理的任务上的性能表现尚不明确,可能无法达到Transformer的水平。
核心思路:论文的核心思路是通过理论分析和实验验证,揭示Mamba模型在COPY操作和CoT推理任务上的局限性。通过分析Mamba与线性注意力机制的联系,以及CoT任务与动态规划问题的关联,探讨Mamba在不同场景下的性能表现,并与Transformer进行对比。
技术框架:论文主要通过以下步骤进行分析:1) 定义COPY操作,并分析Mamba和Transformer在执行COPY操作时的能力差异。2) 将CoT推理任务抽象为动态规划(DP)问题,并分析Mamba和Transformer在解决DP问题时的计算复杂度。3) 设计实验,在COPY和CoT任务上评估Mamba和Transformer的性能。
关键创新:论文的关键创新在于:1) 首次系统性地分析了Mamba模型在COPY操作和CoT推理任务上的局限性。2) 揭示了Mamba在处理需要精确信息复制和复杂推理的任务时,可能无法达到Transformer的性能水平。3) 将CoT推理任务与动态规划问题联系起来,为分析Mamba在复杂推理任务上的性能提供了新的视角。
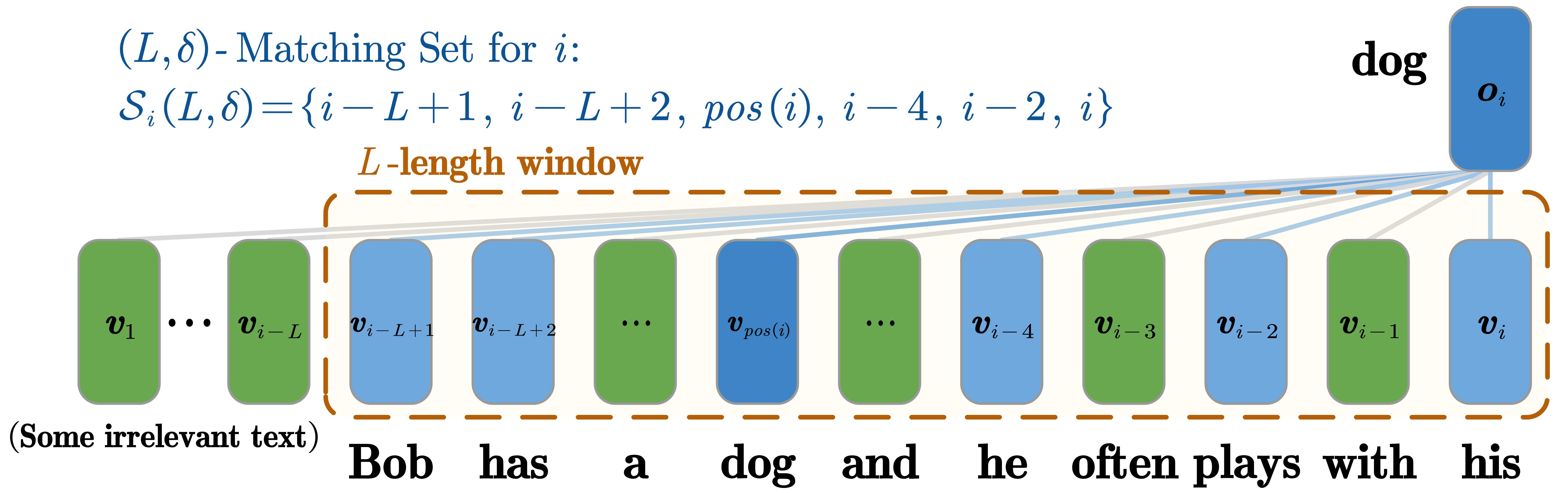
关键设计:在COPY任务中,论文设计了不同长度的序列,并评估Mamba和Transformer的复制准确率。在CoT任务中,论文选择了具有不同属性的动态规划问题,如具有局部性的DP问题,并评估Mamba和Transformer的求解效率和准确率。论文还分析了Mamba模型在不同参数设置下的性能表现,例如Mamba模型的大小与输入序列长度的关系。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在COPY任务中,固定大小的Mamba模型难以准确复制长序列,而Transformer可以轻松处理。在CoT任务中,Mamba模型在解决任意DP问题时的总成本与标准Transformer相当,但在面对具有局部性的DP问题时,Mamba可以节省开销。这些实验结果验证了Mamba在特定任务上的局限性。
🎯 应用场景
该研究成果有助于更好地理解Mamba模型的优势和局限性,为选择合适的模型解决特定任务提供指导。研究结果对于开发更高效、更强大的语言模型具有重要意义,尤其是在需要处理长序列和复杂推理的任务中,例如文档摘要、机器翻译、对话生成等。
📄 摘要(原文)
Transformers have become the backbone of modern Large Language Models (LLMs); however, their inference overhead grows linearly with the sequence length, posing challenges for modeling long sequences. In light of this, Mamba has attracted attention for maintaining a constant inference size, with empirical evidence demonstrating that it can match Transformer performance in sequence modeling while significantly reducing computational costs. However, an open question remains: can Mamba always bring savings while achieving performance comparable to Transformers? In this paper, we focus on analyzing the expressive ability of Mamba to perform our defined COPY operation and Chain of Thought (CoT) reasoning. First, inspired by the connection between Mamba and linear attention, we show that constant-sized Mamba may struggle to perform COPY operations while Transformers can handle them more easily. However, when the size of Mamba grows linearly with the input sequence length, it can accurately perform COPY, but in this case, Mamba no longer provides overhead savings. Based on this observation, we further analyze Mamba's ability to tackle CoT tasks, which can be described by the Dynamic Programming (DP) problems. Our findings suggest that to solve arbitrary DP problems, the total cost of Mamba is still comparable to standard Transformers. However, similar to efficient Transformers, when facing DP problems with favorable properties such as locality, Mamba can provide savings in overhead. Our experiments on the copy and CoT tasks further demonstrate Mamba's limitations compared to Transformers in learning these tasks.