Understanding Large Language Models in Your Pockets: Performance Study on COTS Mobile Devices
作者: Jie Xiao, Qianyi Huang, Xu Chen, Chen Tian
分类: cs.LG
发布日期: 2024-10-04 (更新: 2025-09-11)
💡 一句话要点
针对商用移动设备,研究人员对本地部署的大语言模型性能进行了全面评估。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 移动设备 性能评估 资源优化 推理引擎
📋 核心要点
- 现有大语言模型本地部署在移动设备上,面临性能、资源利用和用户体验的挑战,需要深入评估。
- 该研究通过全面的测量分析,揭示了硬件能力、系统动态与移动端LLM性能之间的关系。
- 研究对比了不同移动SoC在LLM工作负载下的性能差异,为开发者优化移动端LLM应用提供指导。
📝 摘要(中文)
随着大型语言模型(LLM)日益融入我们的工作和日常生活,用户隐私问题日益突出,推动了这些模型本地部署的趋势。目前,一些轻量级LLM(例如,Gemini Nano、LLAMA2 7B)可以在智能手机上本地运行,从而让用户更好地控制个人数据。作为一种快速兴起的应用,我们关注它们在商用移动设备上的性能。为了全面了解LLM在移动平台上的部署现状,我们对移动设备进行了全面的测量研究。我们评估了影响用户体验的指标,包括token吞吐量、延迟和电池消耗,以及对开发者至关重要的因素,如资源利用率、DVFS策略和推理引擎。此外,我们详细分析了这些硬件能力和系统动态如何影响设备上的LLM性能,这可能有助于开发者识别和解决移动LLM应用的瓶颈。我们还对主要供应商的移动片上系统(SoC)进行了全面比较,突出了它们在处理LLM工作负载方面的性能差异。我们希望这项研究能够为设备上LLM的开发和未来移动系统架构的设计提供见解。
🔬 方法详解
问题定义:论文旨在解决在商用移动设备上部署大型语言模型(LLM)时面临的性能瓶颈和资源优化问题。现有方法缺乏对移动设备上LLM性能的全面评估,无法有效指导开发者进行模型优化和硬件选型。特别是,用户体验(如延迟、吞吐量)和设备资源利用率(如电池消耗、CPU/GPU占用)之间的权衡需要深入研究。
核心思路:论文的核心思路是通过全面的测量和分析,揭示移动设备上LLM性能的关键影响因素。通过对比不同硬件平台(SoC)、推理引擎和模型配置,识别性能瓶颈,并分析系统动态(如DVFS策略)对性能的影响。这种方法旨在为开发者提供数据驱动的优化建议,并为未来的移动系统架构设计提供参考。
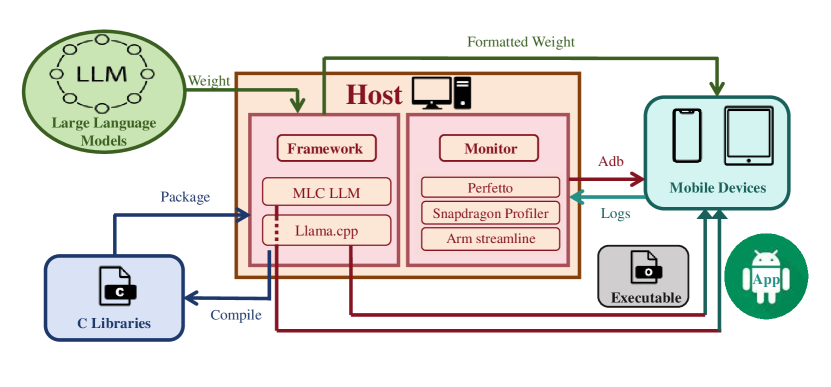
技术框架:该研究的技术框架主要包括以下几个阶段:1) 选择具有代表性的商用移动设备和LLM模型;2) 设计全面的性能评估指标,包括token吞吐量、延迟、电池消耗、资源利用率等;3) 实施大规模的测量实验,收集性能数据;4) 对数据进行深入分析,识别性能瓶颈和关键影响因素;5) 对不同硬件平台和推理引擎进行对比分析,评估其性能差异。
关键创新:该研究的关键创新在于其全面性和系统性。它不仅关注用户体验层面的性能指标,还深入分析了硬件资源利用和系统动态对LLM性能的影响。此外,该研究还提供了对不同移动SoC的详细对比,为开发者提供了有价值的参考信息。与现有研究相比,该研究更侧重于实际应用场景,并提供了更具操作性的优化建议。
关键设计:在实验设计方面,论文选择了具有代表性的商用移动设备,包括不同厂商和不同型号的智能手机。在模型选择方面,论文选择了可以在移动设备上本地运行的轻量级LLM,如Gemini Nano和LLAMA2 7B。在性能评估方面,论文设计了一系列全面的指标,包括token吞吐量、延迟、电池消耗、CPU/GPU利用率、内存占用等。此外,论文还考虑了不同的推理引擎(如TensorFlow Lite、ONNX Runtime)和模型配置(如量化、剪枝)对性能的影响。
🖼️ 关键图片
📊 实验亮点
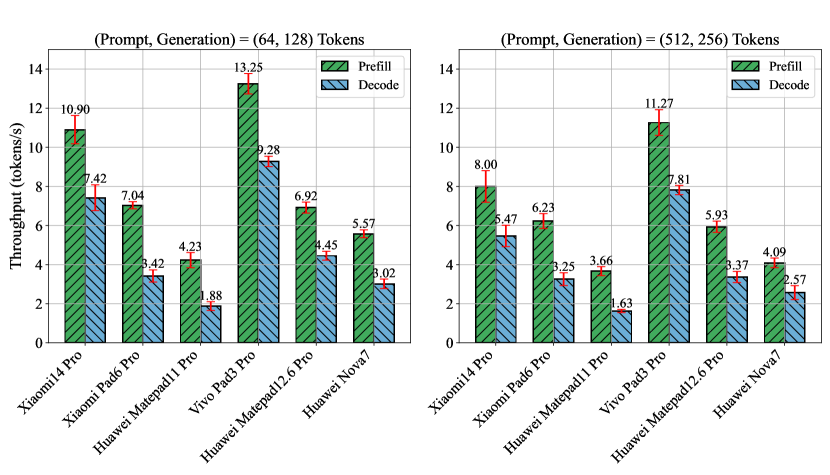
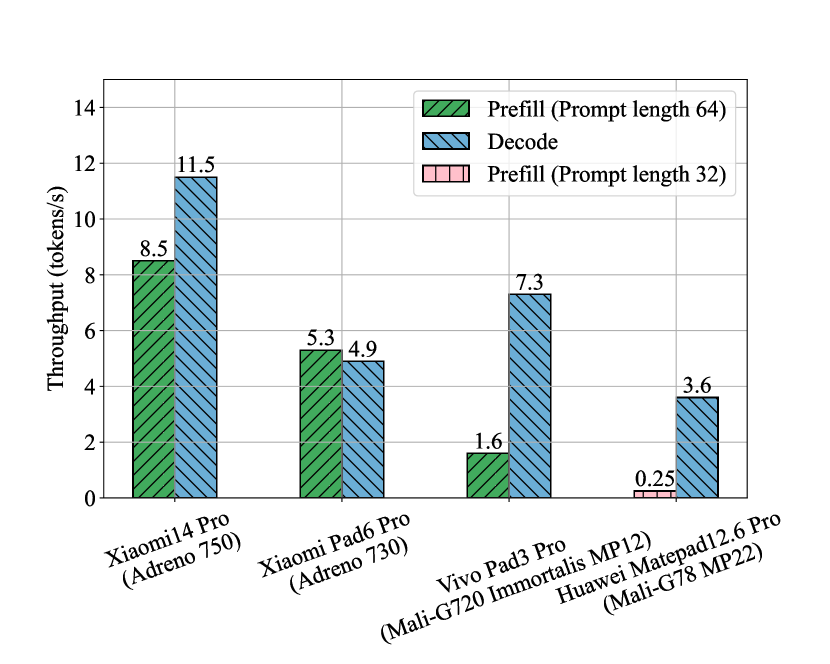
实验结果表明,不同移动SoC在处理LLM工作负载时存在显著性能差异。例如,某些SoC在token吞吐量方面表现更优,而另一些SoC在电池消耗方面更具优势。研究还发现,推理引擎的选择和模型配置对性能有重要影响。通过合理的优化,可以在移动设备上实现高性能、低功耗的LLM应用。
🎯 应用场景
该研究成果可应用于移动设备上的智能助手、离线翻译、本地知识库等场景。通过优化模型部署和硬件配置,可以提升用户体验,降低设备功耗,并保护用户隐私。未来,该研究可推动移动端AI应用的发展,并为移动系统架构设计提供指导。
📄 摘要(原文)
As large language models (LLMs) increasingly integrate into every aspect of our work and daily lives, there are growing concerns about user privacy, which push the trend toward local deployment of these models. There are a number of lightweight LLMs (e.g., Gemini Nano, LLAMA2 7B) that can run locally on smartphones, providing users with greater control over their personal data. As a rapidly emerging application, we are concerned about their performance on commercial-off-the-shelf mobile devices. To fully understand the current landscape of LLM deployment on mobile platforms, we conduct a comprehensive measurement study on mobile devices. We evaluate both metrics that affect user experience, including token throughput, latency, and battery consumption, as well as factors critical to developers, such as resource utilization, DVFS strategies, and inference engines. In addition, we provide a detailed analysis of how these hardware capabilities and system dynamics affect on-device LLM performance, which may help developers identify and address bottlenecks for mobile LLM applications. We also provide comprehensive comparisons across the mobile system-on-chips (SoCs) from major vendors, highlighting their performance differences in handling LLM workloads. We hope that this study can provide insights for both the development of on-device LLMs and the design for future mobile system architecture.