In-context Learning in Presence of Spurious Correlations
作者: Hrayr Harutyunyan, Rafayel Darbinyan, Samvel Karapetyan, Hrant Khachatrian
分类: cs.LG, cs.CL
发布日期: 2024-10-04
💡 一句话要点
针对虚假相关性的上下文学习,提出新训练方法提升分类任务性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 虚假相关性 分类任务 元学习 泛化能力
📋 核心要点
- 现有上下文学习方法易受虚假特征影响,且在单任务元训练时易产生任务记忆,无法有效利用上下文信息。
- 提出一种新的训练技术,专门针对分类任务训练上下文学习器,以减轻虚假相关性的影响。
- 实验表明,该上下文学习器在特定分类任务上可媲美甚至超越ERM和GroupDRO等强基线方法。
📝 摘要(中文)
大型语言模型展现出卓越的上下文学习能力,即通过少量示例学习解决任务。最近的研究表明,Transformer可以通过训练来执行简单的上下文回归任务。本文探讨了训练上下文学习器以处理涉及虚假特征的分类任务的可能性。研究发现,传统的上下文学习器训练方法容易受到虚假特征的影响。此外,当元训练数据集仅包含一个任务的实例时,传统方法会导致任务记忆,而无法产生利用上下文进行预测的模型。基于这些观察,我们提出了一种新的技术来训练这种学习器以用于给定的分类任务。值得注意的是,这种上下文学习器可以匹配甚至优于像ERM和GroupDRO这样的强大方法。然而,与这些算法不同,它不能很好地推广到其他任务。我们表明,通过在多样化的合成上下文学习实例数据集上进行训练,可以获得推广到未见任务的上下文学习器。
🔬 方法详解
问题定义:论文旨在解决上下文学习器在存在虚假相关性的分类任务中的性能问题。现有方法的痛点在于,它们容易受到虚假特征的影响,导致模型学习到错误的关联,从而在测试时泛化能力较差。此外,当元训练数据集中只包含单一任务时,模型容易记住该任务的特定模式,而无法真正利用上下文信息进行学习。
核心思路:论文的核心思路是设计一种新的训练方法,使上下文学习器能够更好地识别和忽略虚假特征,从而提高其在分类任务中的性能。通过特定的训练策略,鼓励模型学习到更鲁棒的特征表示,并更好地利用上下文信息进行预测。
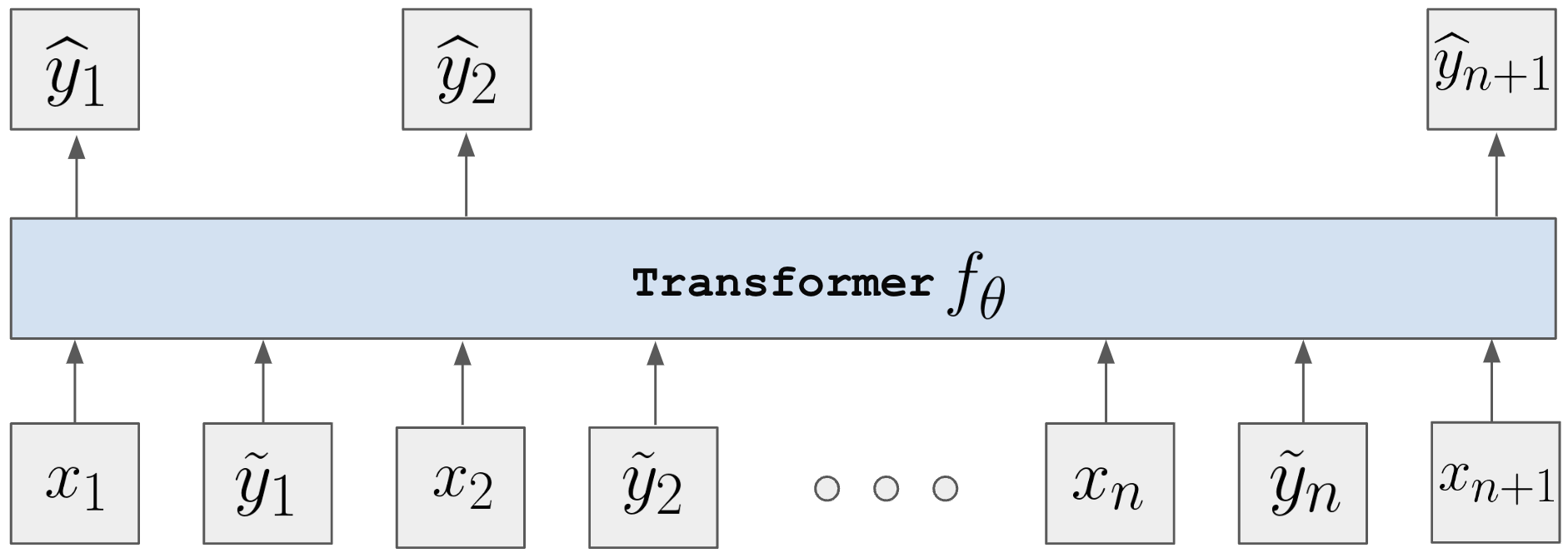
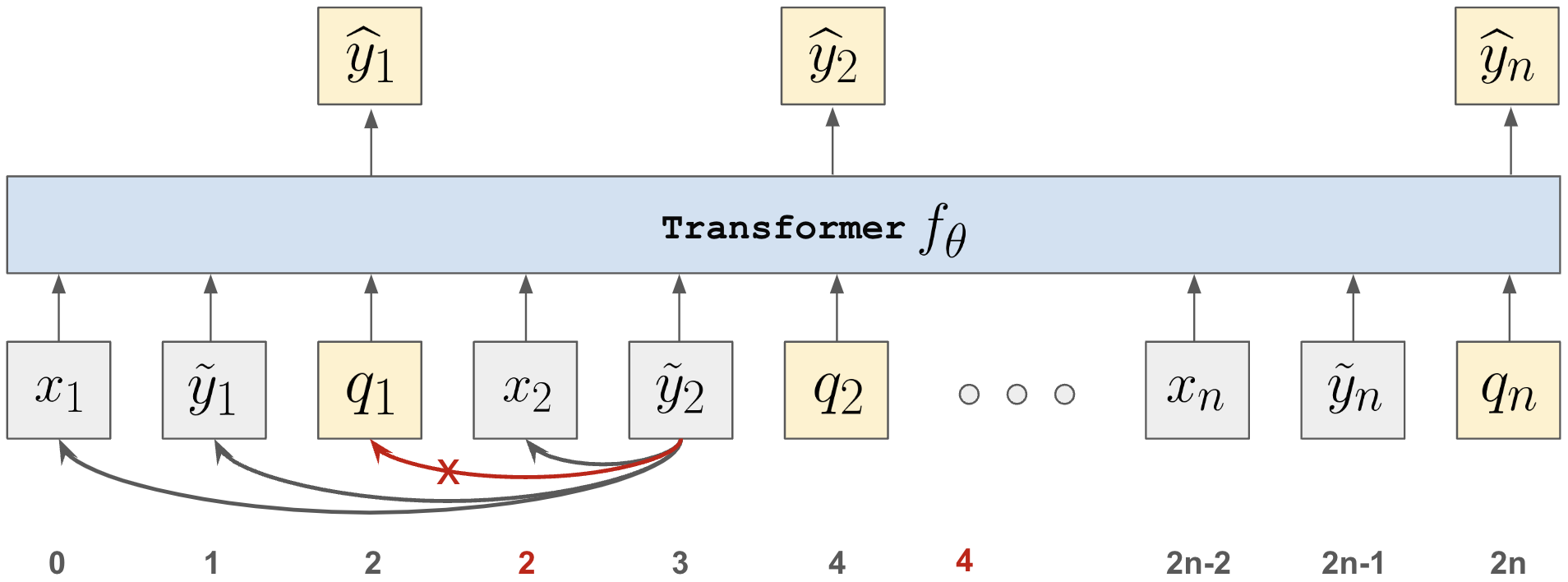
技术框架:论文提出的技术框架主要包括以下几个阶段:首先,构建包含虚假相关性的分类任务数据集。然后,使用提出的训练方法对上下文学习器进行元训练。在训练过程中,模型会学习如何利用上下文信息来区分真实特征和虚假特征。最后,在测试数据集上评估模型的性能,并与其他基线方法进行比较。
关键创新:论文最重要的技术创新点在于提出了一种新的训练方法,该方法能够有效地减轻虚假相关性对上下文学习器的影响。与现有方法相比,该方法能够使模型学习到更鲁棒的特征表示,并更好地利用上下文信息进行预测。
关键设计:论文的关键设计可能包括:特定的数据增强策略,用于增加训练数据的多样性;定制的损失函数,用于鼓励模型学习到更鲁棒的特征表示;以及特定的网络结构,用于更好地利用上下文信息。具体的参数设置、损失函数和网络结构等细节需要在论文中进一步查找。
🖼️ 关键图片
📊 实验亮点
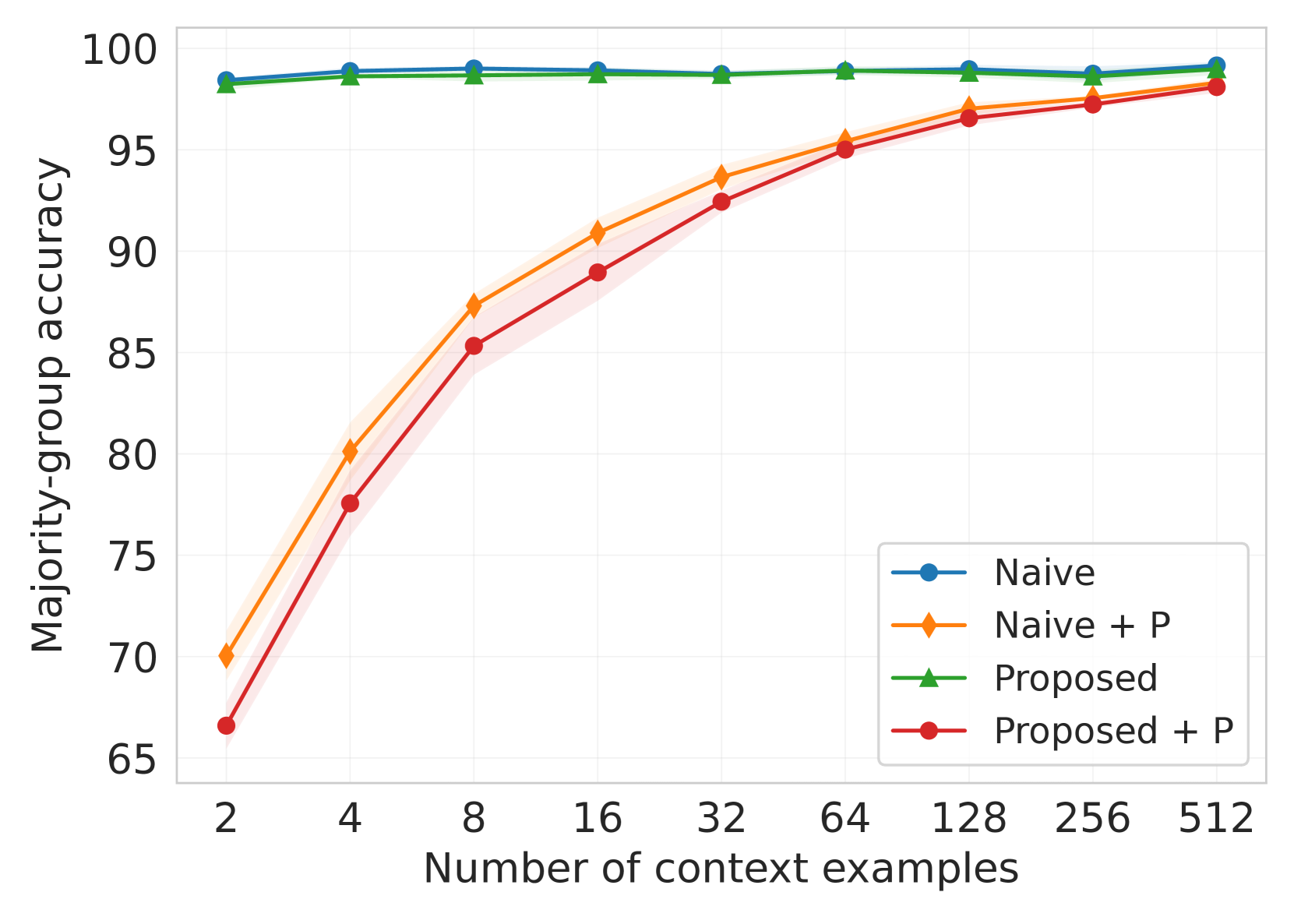
实验结果表明,提出的上下文学习器在特定分类任务上可以匹配甚至优于像ERM和GroupDRO这样的强大方法。虽然该模型在未见过的任务上的泛化能力有限,但通过在多样化的合成数据集上进行训练,可以显著提高其泛化能力。这些结果表明,该方法在解决虚假相关性问题方面具有潜力。
🎯 应用场景
该研究成果可应用于各种存在虚假相关性的分类任务,例如医疗诊断、金融风险评估等。通过训练能够有效忽略虚假特征的上下文学习器,可以提高决策的准确性和可靠性,降低误判风险。此外,该研究为开发更通用的上下文学习算法提供了新的思路,有助于推动人工智能技术的发展。
📄 摘要(原文)
Large language models exhibit a remarkable capacity for in-context learning, where they learn to solve tasks given a few examples. Recent work has shown that transformers can be trained to perform simple regression tasks in-context. This work explores the possibility of training an in-context learner for classification tasks involving spurious features. We find that the conventional approach of training in-context learners is susceptible to spurious features. Moreover, when the meta-training dataset includes instances of only one task, the conventional approach leads to task memorization and fails to produce a model that leverages context for predictions. Based on these observations, we propose a novel technique to train such a learner for a given classification task. Remarkably, this in-context learner matches and sometimes outperforms strong methods like ERM and GroupDRO. However, unlike these algorithms, it does not generalize well to other tasks. We show that it is possible to obtain an in-context learner that generalizes to unseen tasks by training on a diverse dataset of synthetic in-context learning instances.