Spatial-Aware Decision-Making with Ring Attractors in Reinforcement Learning Systems
作者: Marcos Negre Saura, Richard Allmendinger, Wei Pan, Theodore Papamarkou
分类: cs.LG
发布日期: 2024-10-04 (更新: 2025-10-24)
备注: Accepted at NeurIPS 2025
💡 一句话要点
利用环形吸引子进行空间感知决策,提升强化学习系统性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 环形吸引子 空间感知 动作选择 深度强化学习
📋 核心要点
- 传统强化学习在处理连续动作空间或需要空间推理的任务时存在探索效率低下的问题。
- 论文提出利用环形吸引子显式编码动作空间,并提供时间滤波,从而稳定动作选择过程。
- 实验表明,该方法在Atari 100k基准测试中显著提升了性能,超越了现有技术水平。
📝 摘要(中文)
本文提出了一种基于环形吸引子的强化学习方法,旨在提高学习速度和准确性。环形吸引子是一种受神经回路动力学启发的数学模型,作为一种专门的、受大脑启发的结构,编码空间信息和不确定性。它显式地编码动作空间,促进神经活动的组织,并在深度强化学习(DRL)的背景下实现空间表征在神经网络中的分布。这些结构还提供时间滤波,从而稳定探索期间的动作选择,例如,通过保持机器人控制中旋转角度之间的连续性或类游戏环境中战术动作之间的邻接性。环形吸引子在动作选择过程中的应用包括将动作映射到环上的特定位置,并根据神经活动解码所选动作。我们通过构建外生模型和将其集成作为DRL智能体的一部分来研究环形吸引子的应用。我们的方法显著提高了Atari 100k基准测试的性能,与选定的基线相比,性能提高了53%。
🔬 方法详解
问题定义:现有强化学习方法在处理具有空间结构或连续动作空间的任务时,常常面临探索效率低下的问题。例如,在机器人控制中,相邻的动作在物理空间上也是相邻的,但传统的强化学习方法难以利用这种空间关系。此外,探索过程中的随机性可能导致动作选择的不稳定,影响学习效率。
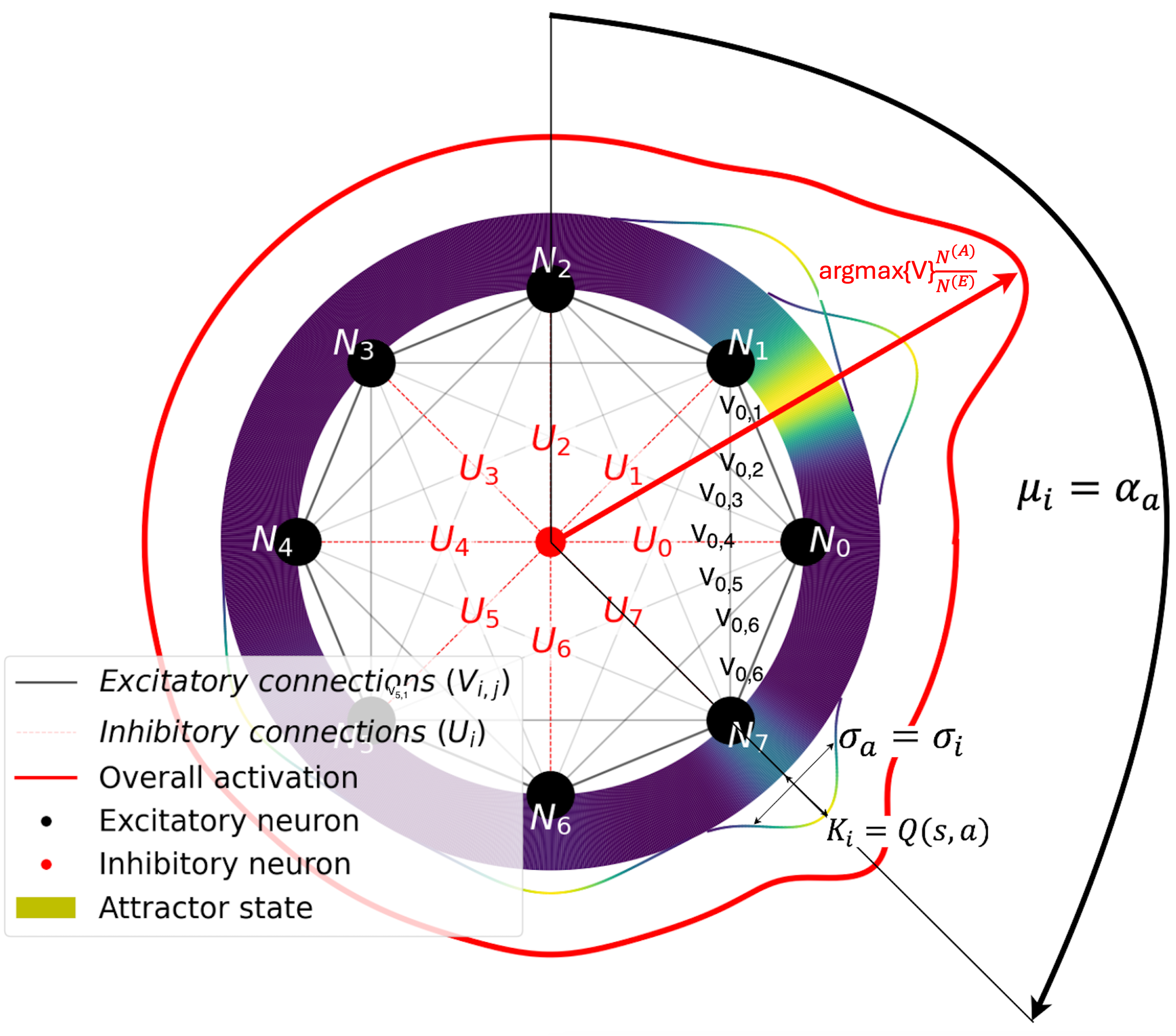
核心思路:论文的核心思路是将动作空间映射到一个环形结构上,利用环形吸引子的动力学特性来编码动作之间的空间关系,并提供时间滤波。环形吸引子可以看作是一个连续的状态空间,每个状态对应一个动作。通过在环上进行扩散,可以实现对相邻动作的探索,并利用时间滤波来平滑动作选择,从而提高探索效率和稳定性。
技术框架:该方法主要包含两个部分:一是构建一个外生的环形吸引子模型,用于动作选择;二是将环形吸引子集成到深度强化学习智能体中。在第一种方法中,智能体首先根据当前状态生成一个动作分布,然后将该分布映射到环形吸引子上,利用环形吸引子的动力学特性选择最终的动作。在第二种方法中,环形吸引子作为智能体的一部分,直接参与到动作选择的过程中。
关键创新:该方法最重要的创新点在于将环形吸引子引入到强化学习中,利用其空间编码和时间滤波的特性来提高探索效率和稳定性。与传统的强化学习方法相比,该方法能够更好地利用动作空间的空间结构,并减少探索过程中的随机性。
关键设计:关键的设计包括如何将动作映射到环形吸引子上,以及如何利用环形吸引子的动力学特性进行动作选择。论文中使用了高斯核函数将动作分布映射到环形吸引子上,并使用一个时间常数来控制时间滤波的强度。此外,论文还探索了不同的网络结构,以将环形吸引子集成到深度强化学习智能体中。
🖼️ 关键图片

📊 实验亮点
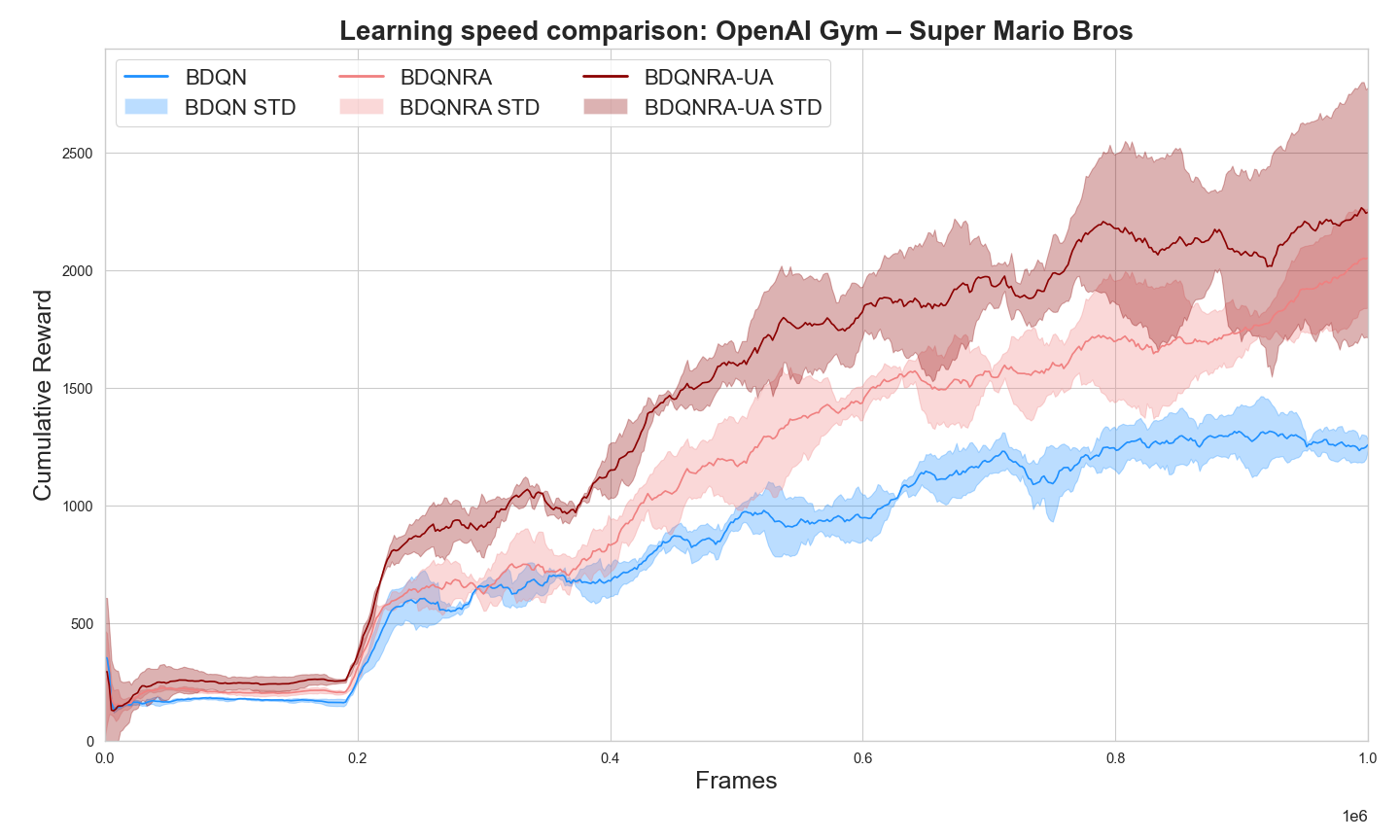
实验结果表明,该方法在Atari 100k基准测试中取得了显著的性能提升,与选定的基线相比,性能提高了53%。这表明该方法能够有效地提高强化学习智能体的学习效率和性能,尤其是在需要空间推理和连续动作控制的任务中。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI、自动驾驶等领域。通过利用环形吸引子编码动作空间,可以提高智能体在连续动作空间中的探索效率和稳定性,从而实现更高效、更智能的决策。例如,在机器人控制中,可以利用该方法实现更平滑、更自然的运动控制;在游戏AI中,可以实现更具策略性和适应性的游戏角色。
📄 摘要(原文)
Ring attractors, mathematical models inspired by neural circuit dynamics, provide a biologically plausible mechanism to improve learning speed and accuracy in Reinforcement Learning (RL). Serving as specialized brain-inspired structures that encode spatial information and uncertainty, ring attractors explicitly encode the action space, facilitate the organization of neural activity, and enable the distribution of spatial representations across the neural network in the context of Deep Reinforcement Learning (DRL). These structures also provide temporal filtering that stabilizes action selection during exploration, for example, by preserving the continuity between rotation angles in robotic control or adjacency between tactical moves in game-like environments. The application of ring attractors in the action selection process involves mapping actions to specific locations on the ring and decoding the selected action based on neural activity. We investigate the application of ring attractors by both building an exogenous model and integrating them as part of DRL agents. Our approach significantly improves state-of-the-art performance on the Atari 100k benchmark, achieving a 53% increase in performance over selected baselines.