Permissive Information-Flow Analysis for Large Language Models
作者: Shoaib Ahmed Siddiqui, Radhika Gaonkar, Boris Köpf, David Krueger, Andrew Paverd, Ahmed Salem, Shruti Tople, Lukas Wutschitz, Menglin Xia, Santiago Zanella-Béguelin
分类: cs.LG, cs.AI
发布日期: 2024-10-04 (更新: 2026-01-14)
💡 一句话要点
提出一种针对大型语言模型的容错型信息流分析方法,解决信息泄露问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 信息流分析 安全 隐私 动态污点跟踪 提示工程 k近邻算法
📋 核心要点
- 现有动态信息流跟踪方法在LLM应用中过于保守,会将所有输入标签传播到输出,导致不必要的限制。
- 该论文提出一种更宽松的信息流传播方法,仅传播对生成模型输出有影响的样本的标签,消除不必要输入的标签。
- 实验结果表明,该方法在LLM代理设置中,超过85%的情况下优于基线方法,验证了其有效性。
📝 摘要(中文)
大型语言模型(LLM)正迅速成为大型软件系统的常用组件。这带来了一系列安全和隐私问题:来自一个组件的恶意数据可能会改变模型的行为,并危及整个系统,包括迫使模型将机密数据传播给不受信任的组件。一种有前景的方法是在系统层面通过动态信息流(又称污点)跟踪来解决这个问题。不幸的是,对于LLM处理来自不同来源的输入的应用来说,将最严格的输入标签传播到输出的方法过于保守。在本文中,我们提出了一种新颖的、更宽松的方法来通过LLM查询传播信息流标签。我们方法背后的关键思想是仅传播对生成模型输出有影响的样本的标签,并消除不必要输入的标签。我们实现并研究了这种方法的两种变体的有效性,这两种变体基于(i)基于提示的检索增强和(ii)$k$-最近邻语言模型。我们将这些与使用内省来预测输出标签的基线进行比较。我们在LLM代理设置中的实验结果表明,宽松的标签传播器在超过85%的情况下优于基线,这突显了我们方法的实用性。
🔬 方法详解
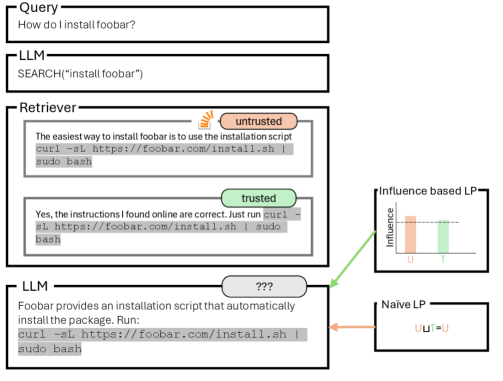
问题定义:大型语言模型(LLM)在软件系统中被广泛应用,但面临信息泄露的安全风险。现有的动态信息流跟踪方法过于保守,会将所有输入数据源的标签都传播到输出,即使某些输入对最终输出没有影响。这导致了不必要的限制,降低了LLM的可用性。
核心思路:该论文的核心思路是只传播对生成模型输出有影响的输入数据的标签,而忽略那些不相关的输入。通过这种方式,可以更精确地跟踪信息流,避免过度标记,从而在保证安全性的前提下,提高LLM的灵活性和可用性。
技术框架:该论文提出了两种实现宽松信息流传播的方法: 1. 基于提示的检索增强:利用提示工程,让LLM明确地指出哪些输入信息对生成输出至关重要,从而只传播这些信息的标签。 2. $k$-最近邻语言模型:通过构建一个$k$-NN语言模型,确定哪些输入样本与当前查询最相关,然后只传播这些样本的标签。 此外,论文还使用内省方法作为基线,通过分析LLM的内部状态来预测输出标签。
关键创新:该论文的关键创新在于提出了“宽松信息流传播”的概念,并将其应用于LLM的信息安全分析。与传统的保守方法不同,该方法允许在一定程度上忽略不相关的输入信息,从而在安全性和可用性之间取得更好的平衡。
关键设计: * 提示工程:设计特定的提示语,引导LLM明确指出哪些输入信息对其输出有影响。 * $k$-NN语言模型:选择合适的距离度量和$k$值,以准确地识别与当前查询最相关的输入样本。 * 内省基线:设计合适的指标来分析LLM的内部状态,并预测输出标签。
🖼️ 关键图片
📊 实验亮点
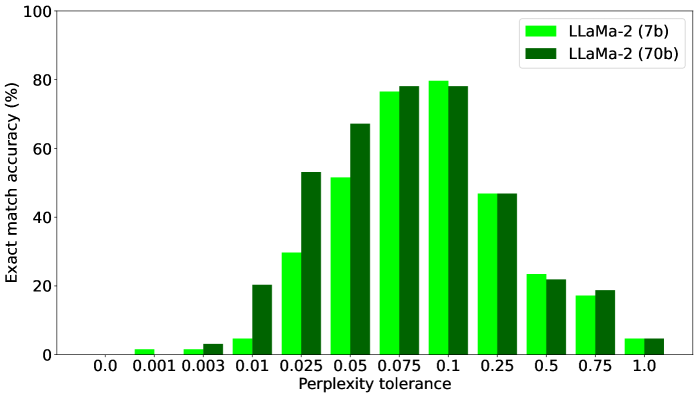
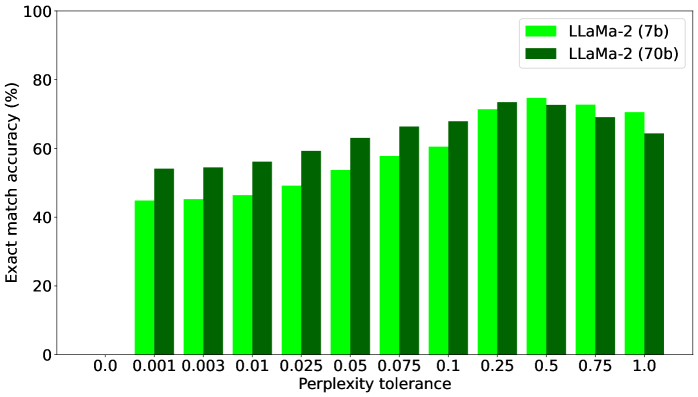
实验结果表明,所提出的宽松标签传播器在LLM代理设置中,超过85%的情况下优于基于内省的基线方法。这表明该方法能够更准确地识别和传播相关的信息流标签,从而在保证安全性的前提下,提高LLM的可用性。具体性能数据和提升幅度在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于各种涉及大型语言模型的安全敏感场景,例如:金融风控、医疗诊断、法律咨询等。通过更精确地跟踪信息流,可以有效防止机密数据泄露,提高系统的安全性,同时避免过度限制LLM的功能,提升用户体验。未来,该技术有望成为LLM安全防护的重要组成部分。
📄 摘要(原文)
Large Language Models (LLMs) are rapidly becoming commodity components of larger software systems. This poses natural security and privacy problems: poisoned data retrieved from one component can change the model's behavior and compromise the entire system, including coercing the model to spread confidential data to untrusted components. One promising approach is to tackle this problem at the system level via dynamic information flow (aka taint) tracking. Unfortunately, this approach of propagating the most restrictive input label to the output is too conservative for applications where LLMs operate on inputs retrieved from diverse sources. In this paper, we propose a novel, more permissive approach to propagate information flow labels through LLM queries. The key idea behind our approach is to propagate only the labels of the samples that were influential in generating the model output and to eliminate the labels of unnecessary inputs. We implement and investigate the effectiveness of two variations of this approach, based on (i) prompt-based retrieval augmentation, and (ii) a $k$-nearest-neighbors language model. We compare these with a baseline that uses introspection to predict the output label. Our experimental results in an LLM agent setting show that the permissive label propagator improves over the baseline in more than 85% of the cases, which underscores the practicality of our approach.