Optimizing Cross-Client Domain Coverage for Federated Instruction Tuning of Large Language Models
作者: Zezhou Wang, Yaxin Du, Xingjun Ma, Yugang Jiang, Zhuzhong Qian, Siheng Chen
分类: cs.LG, cs.CL, cs.DC
发布日期: 2024-09-30 (更新: 2025-08-21)
备注: EMNLP 2025
💡 一句话要点
提出FedDCA,通过优化跨客户端领域覆盖提升联邦指令调优大语言模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 指令调优 大语言模型 领域覆盖 数据增强
📋 核心要点
- 现有联邦指令调优方法难以确定关键性能驱动因素和最佳数据增强策略,导致领域性能提升受限。
- FedDCA算法通过最大化跨客户端领域覆盖,构建多样且非冗余的指令集,从而提升模型在特定领域的泛化能力。
- 实验表明,FedDCA在多个领域优于现有基线,显著提升了模型性能和领域覆盖率,同时保持了良好的隐私性。
📝 摘要(中文)
针对大语言模型的联邦领域特定指令调优(FedDIT),旨在利用分布式私有且有限的数据来增强在特定领域的性能,但识别关键性能驱动因素和最佳增强策略仍然具有挑战性。本文通过实验证实,跨客户端领域覆盖而非数据异构性是关键因素。因此,本文提出FedDCA算法,通过面向多样性的客户端中心选择和基于检索的增强来显式地最大化这种覆盖,从而构建多样化、非冗余的跨客户端指令集。在多个领域的大量实验表明,FedDCA优于11个基线,实现了高达29.19%的性能提升和4.82%-21.36%的领域覆盖改进。FedDCA在各种具有挑战性的场景中保持有效性,包括数据选择、任务特定公共数据稀缺的预留设置以及各种数据异构性,同时隐私风险可控。这项工作阐明了关键的FedDIT动态,并将FedDCA作为一种有效的、保护隐私的和可扩展的解决方案,用于推进领域特定LLM的调优。
🔬 方法详解
问题定义:联邦领域特定指令调优(FedDIT)旨在利用分布式、私有的数据来提升大型语言模型(LLM)在特定领域的性能。然而,现有方法往往难以确定影响性能的关键因素,并且缺乏有效的数据增强策略,导致模型在目标领域的表现提升有限。现有的方法通常关注于解决数据异构性问题,而忽略了跨客户端的领域覆盖的重要性。
核心思路:本文的核心思路是最大化跨客户端的领域覆盖。作者通过实验发现,相比于数据异构性,跨客户端的领域覆盖才是影响FedDIT性能的关键因素。因此,FedDCA算法旨在构建一个多样化、非冗余的跨客户端指令集,从而提升模型在目标领域的泛化能力。
技术框架:FedDCA算法主要包含两个核心模块:多样性导向的客户端中心选择和基于检索的增强。首先,通过客户端中心选择算法,选择能够最大化领域覆盖的客户端子集。然后,利用基于检索的增强方法,从选定的客户端数据中检索出具有代表性的指令,并将其用于指令调优。整个过程在联邦学习框架下进行,保证了数据的隐私性。
关键创新:FedDCA的关键创新在于显式地优化跨客户端的领域覆盖。与现有方法不同,FedDCA不再仅仅关注于解决数据异构性问题,而是将领域覆盖作为优化目标,从而更有效地提升模型在目标领域的性能。此外,FedDCA提出的多样性导向的客户端中心选择和基于检索的增强方法,能够有效地构建多样化、非冗余的指令集。
关键设计:在客户端中心选择方面,FedDCA采用了一种基于贪心算法的策略,每次选择能够最大化当前领域覆盖的客户端。在基于检索的增强方面,FedDCA使用了一种基于语义相似度的检索方法,从客户端数据中检索出与目标领域相关的指令。此外,FedDCA还采用了差分隐私技术,以进一步保护数据的隐私性。具体的损失函数和网络结构与基线方法保持一致,重点在于数据选择和增强策略的优化。
🖼️ 关键图片
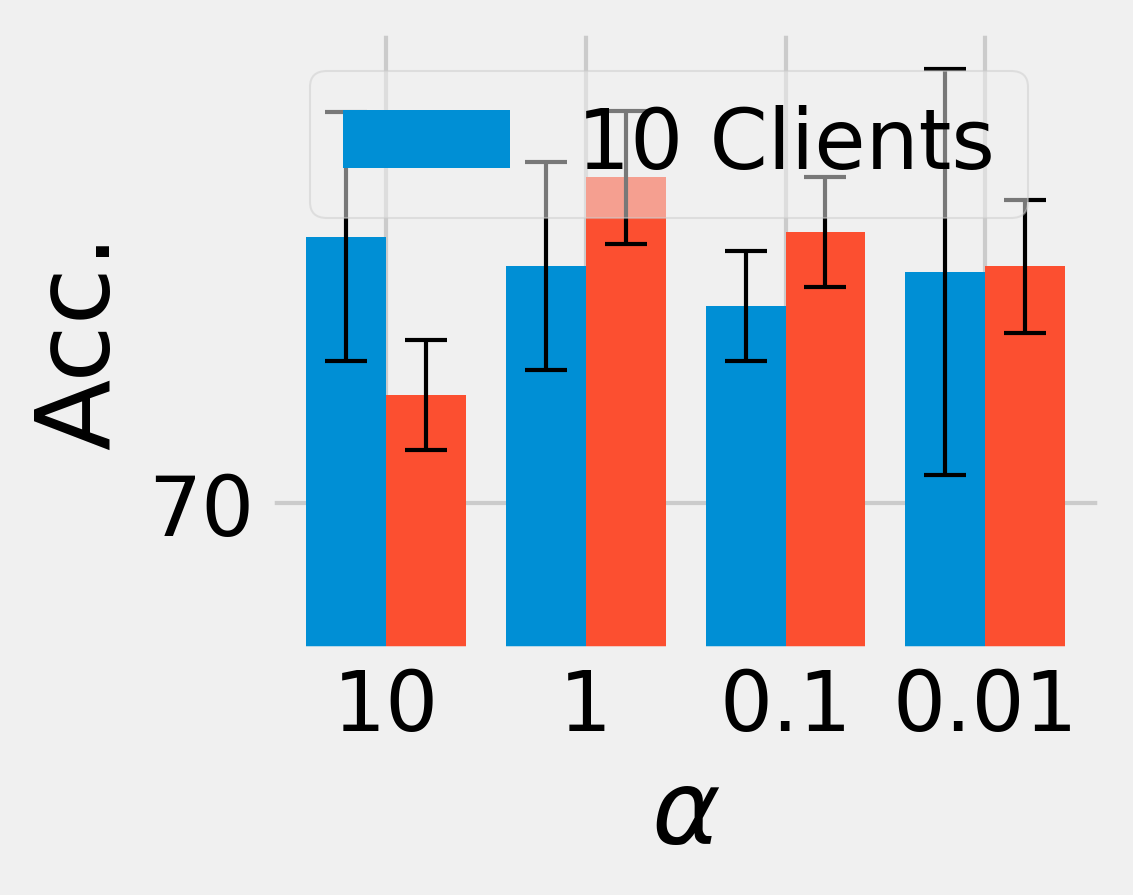
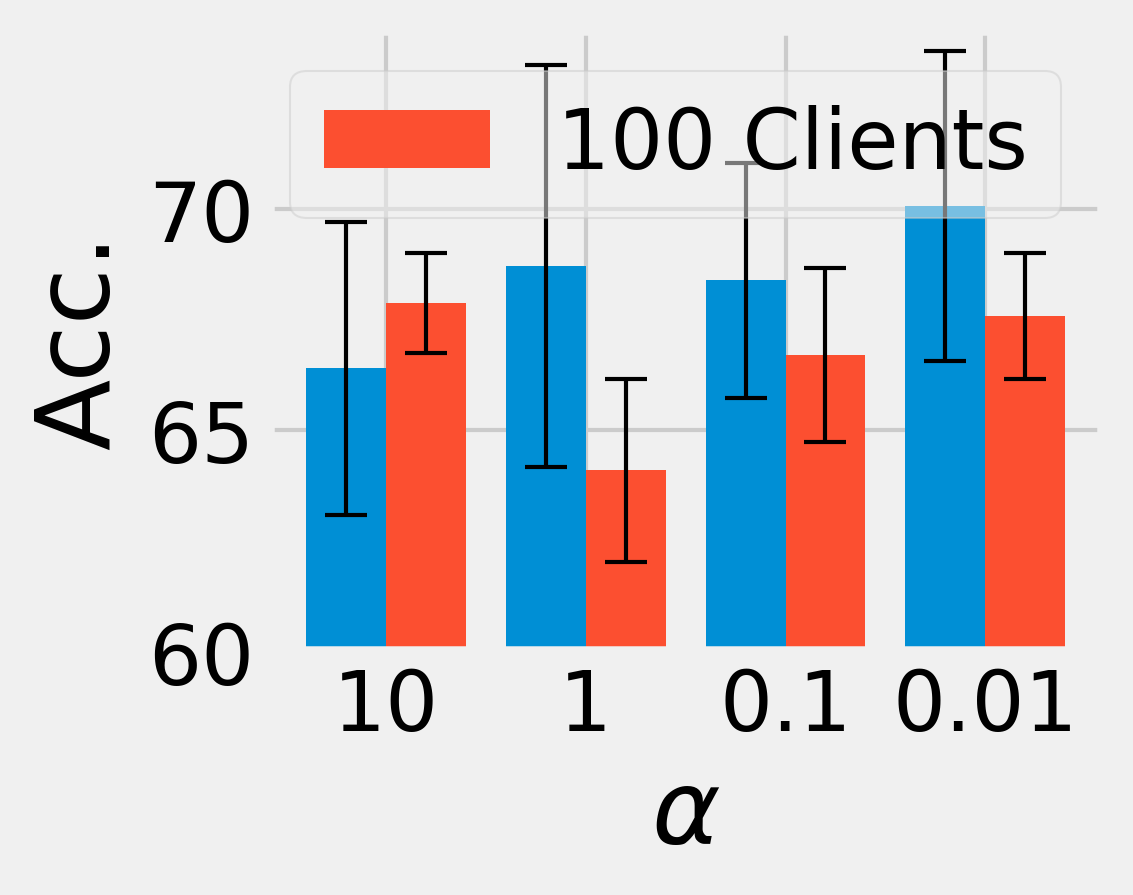
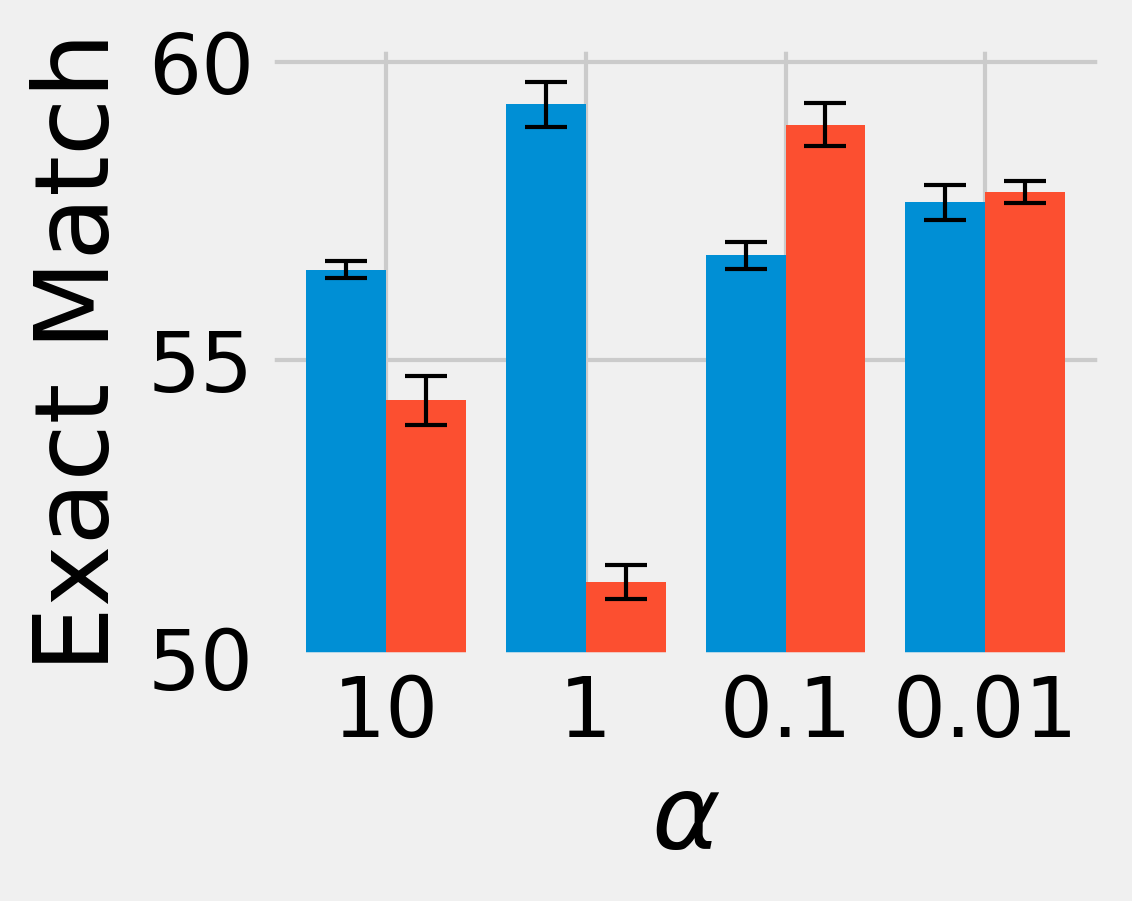
📊 实验亮点
实验结果表明,FedDCA在多个领域优于11个基线方法,实现了高达29.19%的性能提升和4.82%-21.36%的领域覆盖改进。尤其是在数据选择、任务特定公共数据稀缺的预留设置以及各种数据异构性等具有挑战性的场景中,FedDCA仍然表现出良好的性能和鲁棒性,验证了其有效性和实用性。
🎯 应用场景
FedDCA可应用于医疗、金融、法律等多个领域,提升LLM在特定领域的专业能力。例如,在医疗领域,可以利用分布在不同医院的电子病历数据,训练出能够辅助医生进行诊断和治疗的LLM。该研究有助于推动LLM在垂直领域的应用,并为构建更加智能化的行业解决方案提供技术支持。
📄 摘要(原文)
Federated domain-specific instruction tuning (FedDIT) for large language models (LLMs) aims to enhance performance in specialized domains using distributed private and limited data, yet identifying key performance drivers and optimal augmentation strategies remains challenging. We empirically establish that cross-client domain coverage, rather than data heterogeneity, is the pivotal factor. We then introduce FedDCA, an algorithm that explicitly maximizes this coverage through diversity-oriented client center selection and retrieval-based augmentation, constructing diverse, non-redundant cross-client instruction sets. Extensive experiments across multiple domains demonstrate FedDCA's superiority over eleven baselines, achieving performance gains of up to 29.19\% and domain coverage improvements of 4.82\%-21.36\%. FedDCA maintains its effectiveness in diverse and challenging scenarios, including data selection, held-out settings where task-specific public data is scarce and various data heterogeneity, with manageable privacy risks. This work clarifies critical FedDIT dynamics and presents FedDCA as an effective, privacy-preserving, and scalable solution for advancing domain-specific LLM tuning.