Membership Inference Attacks Cannot Prove that a Model Was Trained On Your Data
作者: Jie Zhang, Debeshee Das, Gautam Kamath, Florian Tramèr
分类: cs.LG, cs.CR
发布日期: 2024-09-29 (更新: 2025-03-07)
备注: position paper at IEEE SaTML 2025
💡 一句话要点
论证成员推断攻击无法有效证明模型基于特定数据训练
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 成员推断攻击 训练数据证明 假阳性率 数据提取攻击 金丝雀数据 模型版权 数据隐私
📋 核心要点
- 现有方法使用成员推断攻击来证明模型基于特定数据训练,但缺乏对假阳性率的有效控制。
- 论文核心在于论证成员推断攻击作为训练数据证明的不可靠性,并提出数据提取和金丝雀数据成员推断作为替代方案。
- 论文通过理论分析和实验验证,强调了控制假阳性率在训练数据证明中的重要性,并探索了可行的解决方案。
📝 摘要(中文)
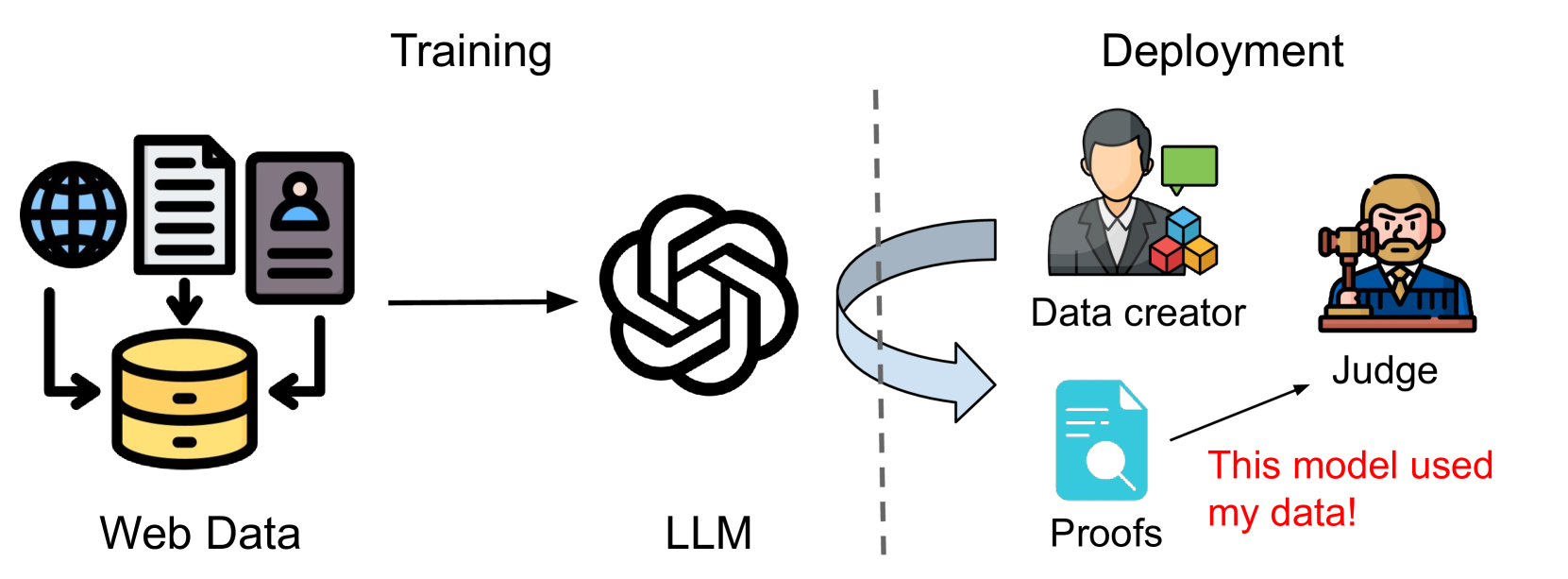
本文研究了训练数据证明问题,即数据创建者或所有者希望向第三方证明某个机器学习模型是在他们的数据上训练的。训练数据证明在最近针对基于网络规模数据训练的基础模型的诉讼中起着关键作用。许多先前的工作建议使用成员推断攻击来实例化训练数据证明。我们认为这种方法从根本上是不合理的:为了提供令人信服的证据,数据创建者需要证明他们的攻击具有较低的假阳性率,即在模型未在目标数据上训练的零假设下,攻击的输出不太可能发生。然而,从这个零假设中抽样是不可能的,因为我们不知道训练集的具体内容,也无法(高效地)重新训练大型基础模型。最后,我们提出了两种前进的道路,通过展示数据提取攻击和对特殊金丝雀数据的成员推断可以用来创建可靠的训练数据证明。
🔬 方法详解
问题定义:论文关注的是如何向第三方证明一个机器学习模型确实使用了特定的数据进行训练。现有的方法主要依赖于成员推断攻击,即判断某个数据点是否属于模型的训练集。然而,这种方法的痛点在于,即使模型没有使用该数据训练,成员推断攻击也可能产生“是”的结果,即出现假阳性。如何区分真正的训练数据和仅仅是与训练数据相似的数据,是现有方法面临的挑战。
核心思路:论文的核心思路是论证基于成员推断攻击的训练数据证明是不健全的,因为无法有效地评估和控制假阳性率。为了提供可信的证据,需要证明攻击的输出在模型未在目标数据上训练的零假设下不太可能发生。由于无法得知确切的训练集内容,也无法高效地重新训练大型模型,因此直接验证零假设是不可行的。
技术框架:论文并没有提出一个完整的技术框架,而是侧重于分析现有方法的缺陷,并提出了两种可能的替代方案。这两种方案分别是:1) 数据提取攻击,即尝试从模型中提取出训练数据;2) 对特殊金丝雀数据的成员推断,即在训练集中加入一些特殊的数据点(金丝雀数据),然后通过成员推断来判断模型是否使用了这些数据。
关键创新:论文最重要的创新在于指出了基于成员推断攻击的训练数据证明的根本缺陷,即无法有效控制假阳性率。这使得现有的方法在法律诉讼等场景中难以作为可靠的证据。论文还提出了数据提取攻击和金丝雀数据成员推断作为替代方案,为未来的研究提供了新的方向。
关键设计:论文并没有涉及具体的参数设置、损失函数或网络结构等技术细节,而是侧重于理论分析和概念论证。对于数据提取攻击,关键在于设计有效的攻击方法,能够从模型中尽可能多地提取出训练数据。对于金丝雀数据成员推断,关键在于选择合适的金丝雀数据,使其既能被模型有效学习,又能在成员推断中被准确识别。
🖼️ 关键图片


📊 实验亮点
论文通过理论分析,论证了基于成员推断攻击的训练数据证明的不可靠性,并指出了其根本缺陷在于无法有效控制假阳性率。此外,论文还提出了数据提取攻击和金丝雀数据成员推断作为替代方案,为未来的研究提供了新的方向。
🎯 应用场景
该研究成果对涉及数据隐私、模型版权和法律诉讼等领域具有重要意义。例如,在针对大型语言模型的版权诉讼中,数据所有者可以利用该研究提出的方法来证明模型是否使用了其数据进行训练。此外,该研究也为模型开发者提供了更可靠的训练数据证明方法,有助于建立用户信任。
📄 摘要(原文)
We consider the problem of a training data proof, where a data creator or owner wants to demonstrate to a third party that some machine learning model was trained on their data. Training data proofs play a key role in recent lawsuits against foundation models trained on web-scale data. Many prior works suggest to instantiate training data proofs using membership inference attacks. We argue that this approach is fundamentally unsound: to provide convincing evidence, the data creator needs to demonstrate that their attack has a low false positive rate, i.e., that the attack's output is unlikely under the null hypothesis that the model was not trained on the target data. Yet, sampling from this null hypothesis is impossible, as we do not know the exact contents of the training set, nor can we (efficiently) retrain a large foundation model. We conclude by offering two paths forward, by showing that data extraction attacks and membership inference on special canary data can be used to create sound training data proofs.