Looking through the mind's eye via multimodal encoder-decoder networks
作者: Arman Afrasiyabi, Erica Busch, Rahul Singh, Dhananjay Bhaskar, Laurent Caplette, Nicholas Turk-Browne, Smita Krishnaswamy
分类: eess.IV, cs.LG, q-bio.NC
发布日期: 2024-09-27
💡 一句话要点
提出基于多模态编解码网络的fMRI脑成像解码方法,用于解析心理图像
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: fMRI解码 心理图像 多模态学习 脑机接口 神经科学
📋 核心要点
- 现有方法难以有效解码fMRI信号中的心理图像,尤其是在缺乏直接视觉参考的情况下。
- 论文提出一种多模态编解码网络,通过对齐视频-fMRI和文本提示-fMRI的潜在表示来解码心理图像。
- 实验结果表明,该模型在增强的fMRI数据集上能够准确创建映射并合理地解码心理图像。
📝 摘要(中文)
本文探索了利用fMRI测量数据解码受试者心理图像的方法。为了实现这一解码,首先建立了受试者观看视频时fMRI信号与视觉图像之间的映射关系。该映射将高维fMRI激活状态与视觉图像关联起来。然后,通过文本提示(主要是情感标签,不直接涉及视觉对象)引导受试者。为了解码受试者“脑海中的”视觉图像,将这些fMRI测量的潜在表示与基于视频文本标签的视频-fMRI进行对齐。这种对齐有效地将视频fMRI嵌入与文本提示的fMRI嵌入重叠,从而允许我们使用fMRI到视频的映射进行解码。此外,我们通过增加团队收集的另外三名受试者的记录,增强了现有的fMRI数据集(最初包含五名受试者的数据)。我们证明了我们的模型在这个增强数据集上的有效性,既能准确地创建映射,又能合理地解码心理图像。
🔬 方法详解
问题定义:论文旨在解决如何从fMRI数据中解码出受试者脑海中的心理图像,尤其是在仅提供文本提示(例如情感标签)而没有直接视觉刺激的情况下。现有方法在处理这种间接的心理图像解码任务时存在挑战,因为fMRI信号与抽象概念之间的映射关系更加复杂。
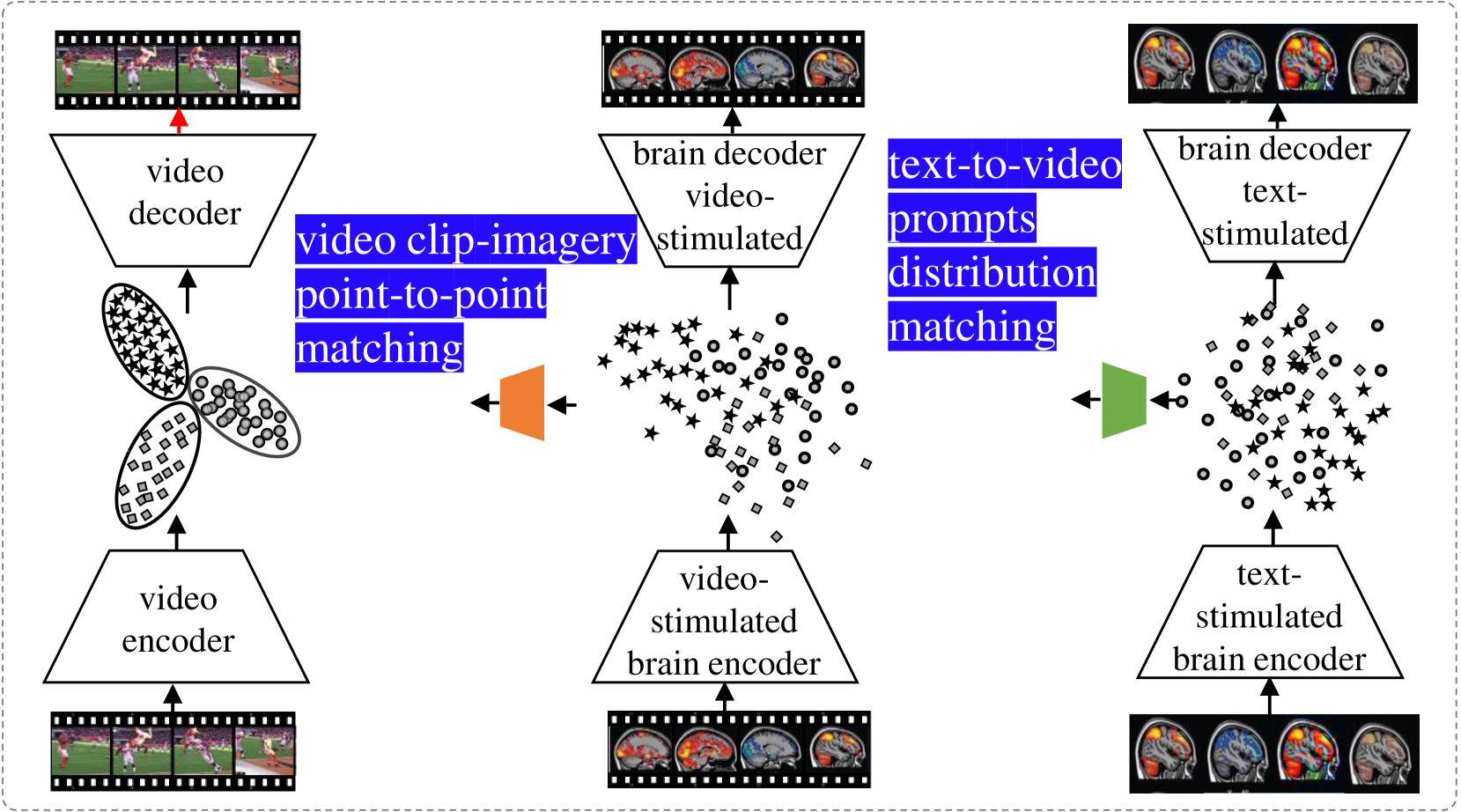
核心思路:论文的核心思路是通过建立视频-fMRI映射作为桥梁,将文本提示的fMRI信号与视觉图像联系起来。具体来说,首先学习视频内容与fMRI信号之间的对应关系,然后将文本提示的fMRI信号对齐到视频-fMRI的潜在空间中,从而利用已知的视频-fMRI映射来解码心理图像。
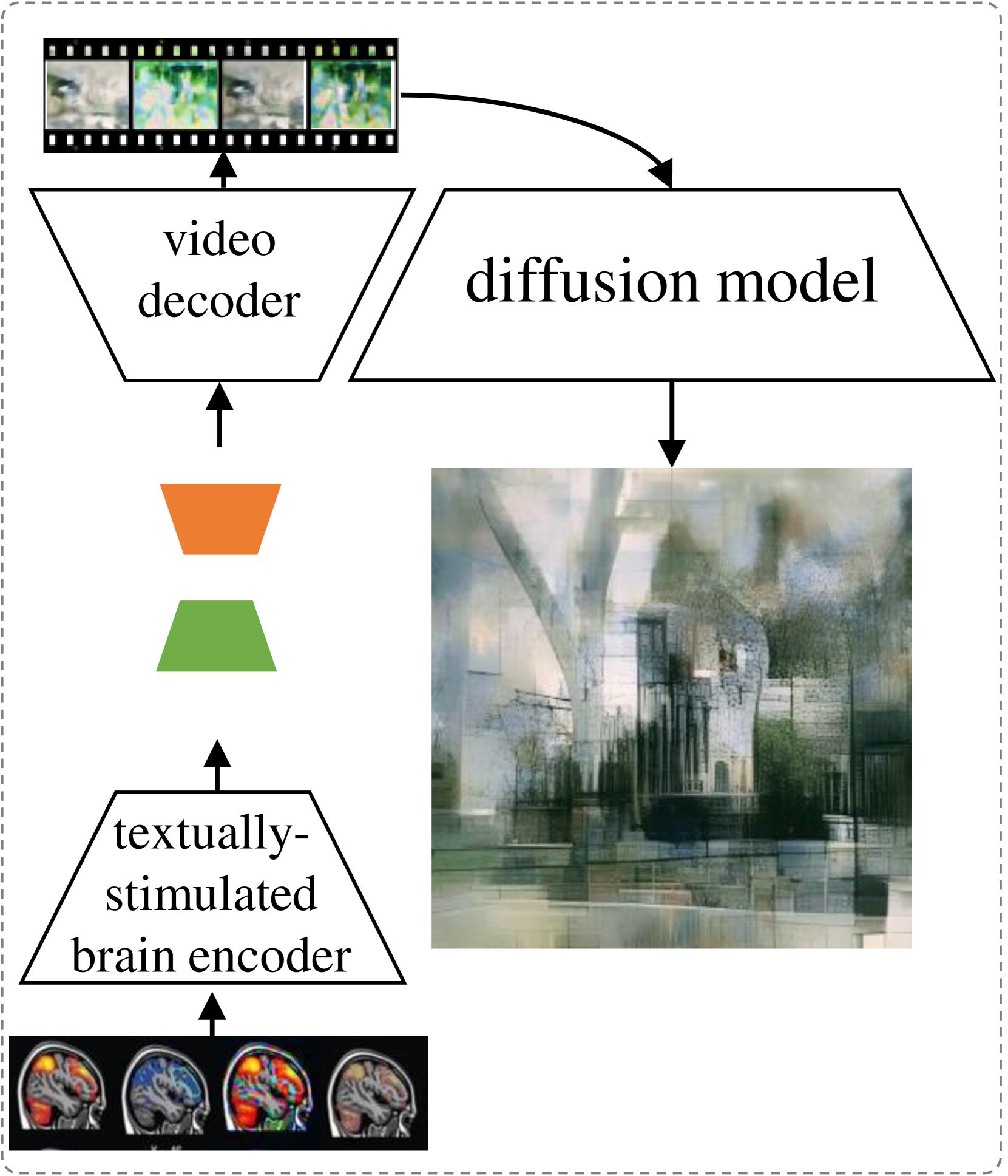
技术框架:整体框架包含以下几个主要步骤:1) 构建视频-fMRI映射:利用受试者观看视频时的fMRI数据,训练一个模型来学习视频内容与fMRI信号之间的对应关系。2) 文本提示:向受试者提供文本提示(例如情感标签),并记录相应的fMRI信号。3) 潜在空间对齐:将文本提示的fMRI信号嵌入到与视频-fMRI相同的潜在空间中,通过某种对齐机制(具体细节未知)使它们尽可能接近。4) 解码:利用学习到的视频-fMRI映射,将对齐后的文本提示fMRI信号解码为视觉图像。
关键创新:论文的关键创新在于利用视频-fMRI映射作为先验知识,来辅助解码文本提示的fMRI信号。这种方法有效地将抽象的文本概念与具体的视觉图像联系起来,从而实现了间接的心理图像解码。与直接从文本到图像的生成模型相比,该方法利用了fMRI数据中蕴含的神经活动信息,可能更准确地反映了受试者的心理状态。
关键设计:论文中关于潜在空间对齐的具体方法、损失函数以及网络结构等技术细节描述不足,属于未知信息。但是,可以推测可能使用了对比学习或相似性度量等方法来对齐不同的fMRI嵌入。
🖼️ 关键图片
📊 实验亮点
论文通过增强现有的fMRI数据集,并在此基础上验证了模型的有效性。虽然没有提供具体的性能指标,但论文声称模型能够准确地创建映射并合理地解码心理图像。与现有方法相比,该模型在处理文本提示的心理图像解码任务上具有优势,但具体的提升幅度未知。
🎯 应用场景
该研究成果可应用于脑机接口、精神疾病诊断、认知科学研究等领域。例如,可以帮助理解精神分裂症患者的思维模式,或用于开发基于意念控制的辅助设备。未来,该技术有望实现更精确的心理状态解码,从而促进人机交互和神经科学的发展。
📄 摘要(原文)
In this work, we explore the decoding of mental imagery from subjects using their fMRI measurements. In order to achieve this decoding, we first created a mapping between a subject's fMRI signals elicited by the videos the subjects watched. This mapping associates the high dimensional fMRI activation states with visual imagery. Next, we prompted the subjects textually, primarily with emotion labels which had no direct reference to visual objects. Then to decode visual imagery that may have been in a person's mind's eye, we align a latent representation of these fMRI measurements with a corresponding video-fMRI based on textual labels given to the videos themselves. This alignment has the effect of overlapping the video fMRI embedding with the text-prompted fMRI embedding, thus allowing us to use our fMRI-to-video mapping to decode. Additionally, we enhance an existing fMRI dataset, initially consisting of data from five subjects, by including recordings from three more subjects gathered by our team. We demonstrate the efficacy of our model on this augmented dataset both in accurately creating a mapping, as well as in plausibly decoding mental imagery.