DMC-VB: A Benchmark for Representation Learning for Control with Visual Distractors
作者: Joseph Ortiz, Antoine Dedieu, Wolfgang Lehrach, Swaroop Guntupalli, Carter Wendelken, Ahmad Humayun, Guangyao Zhou, Sivaramakrishnan Swaminathan, Miguel Lázaro-Gredilla, Kevin Murphy
分类: cs.LG
发布日期: 2024-09-26
备注: NeurIPS 2024 Datasets and Benchmarks Track. Dataset available at: https://github.com/google-deepmind/dmc_vision_benchmark
🔗 代码/项目: GITHUB
💡 一句话要点
提出DMC-VB基准测试,用于评估视觉干扰下控制任务的表征学习鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 离线强化学习 视觉干扰 表征学习 鲁棒性 基准测试
📋 核心要点
- 离线强化学习在泛化智能体方面表现出色,但对背景或视角等视觉干扰因素非常敏感,缺乏鲁棒性。
- DMC-VB数据集旨在评估离线强化学习智能体在视觉干扰下的鲁棒性,包含多种任务和不同质量的数据。
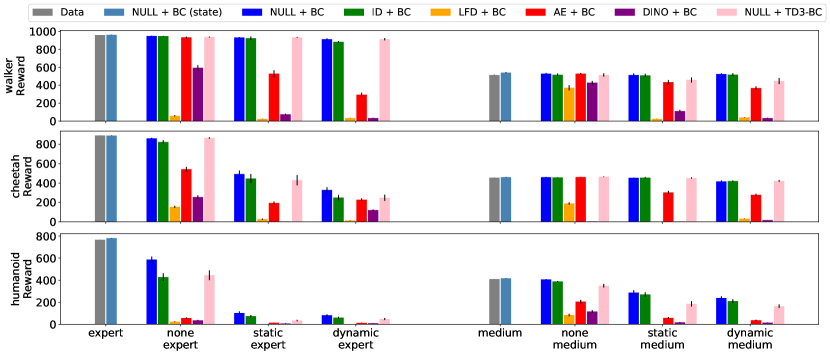
- 实验表明,预训练表征不一定能提升策略学习效果,但在专家数据有限时,利用次优数据或隐藏目标任务进行预训练有所帮助。
📝 摘要(中文)
本文提出了DeepMind Control Visual Benchmark (DMC-VB),一个在DeepMind Control Suite中收集的数据集,用于评估离线强化学习智能体在视觉干扰下,从视觉输入解决连续控制任务的鲁棒性。与之前的工作相比,我们的数据集(a)结合了不同难度的运动和导航任务,(b)包括静态和动态的视觉变化,(c)考虑了由不同技能水平策略生成的数据,(d)系统地返回状态和像素观测对,(e)规模大一个数量级,并且(f)包含具有隐藏目标的任务。伴随我们的数据集,我们提出了三个基准来评估用于预训练的表征学习方法,并对几种最近提出的方法进行了实验。我们发现预训练的表征并不能帮助DMC-VB上的策略学习,并强调了在像素观测和状态上学习的策略之间存在很大的表征差距。当专家数据有限时,策略学习可以从在(a)次优数据和(b)具有随机隐藏目标任务上预训练的表征中受益。我们的数据集和用于训练和评估智能体的基准代码可在https://github.com/google-deepmind/dmc_vision_benchmark获得。
🔬 方法详解
问题定义:论文旨在解决离线强化学习智能体在面对视觉干扰时的鲁棒性问题。现有方法在视觉变化面前表现脆弱,无法很好地泛化到新的视觉环境中。这限制了离线强化学习在实际场景中的应用,因为真实世界的数据通常包含各种各样的视觉干扰因素。
核心思路:论文的核心思路是构建一个包含多种视觉干扰的基准数据集,并利用该数据集来评估和改进离线强化学习智能体的鲁棒性。通过系统地引入静态和动态的视觉变化,并考虑不同技能水平的策略生成的数据,可以更全面地评估智能体在不同情况下的表现。
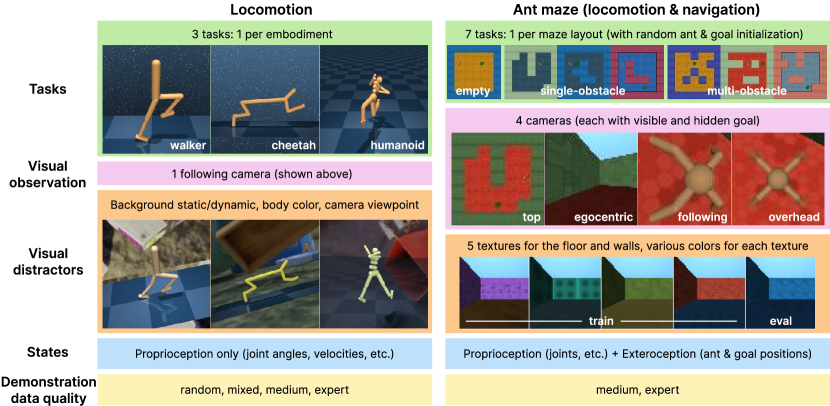
技术框架:DMC-VB数据集构建于DeepMind Control Suite之上,包含运动和导航任务。数据集的构建流程包括:1) 选择DeepMind Control Suite中的任务;2) 引入静态和动态的视觉干扰;3) 使用不同技能水平的策略生成数据;4) 系统地记录状态和像素观测对。此外,论文还提出了三个基准来评估表征学习方法,这些基准用于预训练智能体的表征,然后评估其在DMC-VB上的表现。
关键创新:DMC-VB数据集的关键创新在于其规模、多样性和系统性。与现有数据集相比,DMC-VB数据集更大一个数量级,包含更多种类的任务和视觉干扰,并且系统地记录了状态和像素观测对。此外,DMC-VB数据集还包含具有隐藏目标的任务,这使得评估智能体的泛化能力更加具有挑战性。
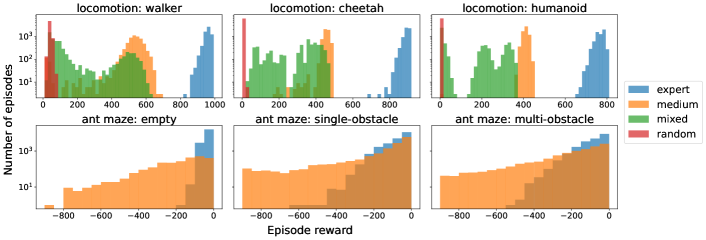
关键设计:DMC-VB数据集的关键设计包括:1) 静态视觉干扰,例如改变背景颜色或添加静态物体;2) 动态视觉干扰,例如移动的物体或变化的灯光;3) 不同技能水平的策略生成的数据,包括专家策略、次优策略和随机策略;4) 具有隐藏目标的任务,例如需要智能体找到隐藏的物体或到达隐藏的位置。
🖼️ 关键图片
📊 实验亮点
实验结果表明,预训练表征不一定能提升DMC-VB上的策略学习效果,这突出了像素观测和状态之间存在的表征差距。然而,当专家数据有限时,使用次优数据或具有随机隐藏目标任务的数据进行预训练可以提高策略学习的性能。这些发现为离线强化学习的表征学习提供了有价值的指导。
🎯 应用场景
该研究成果可应用于机器人、自动驾驶等领域,提升智能体在复杂视觉环境下的控制能力。通过DMC-VB基准测试,可以更好地评估和改进离线强化学习算法的鲁棒性,推动相关技术在现实场景中的应用,例如在存在视觉干扰的工厂环境中进行机器人控制。
📄 摘要(原文)
Learning from previously collected data via behavioral cloning or offline reinforcement learning (RL) is a powerful recipe for scaling generalist agents by avoiding the need for expensive online learning. Despite strong generalization in some respects, agents are often remarkably brittle to minor visual variations in control-irrelevant factors such as the background or camera viewpoint. In this paper, we present theDeepMind Control Visual Benchmark (DMC-VB), a dataset collected in the DeepMind Control Suite to evaluate the robustness of offline RL agents for solving continuous control tasks from visual input in the presence of visual distractors. In contrast to prior works, our dataset (a) combines locomotion and navigation tasks of varying difficulties, (b) includes static and dynamic visual variations, (c) considers data generated by policies with different skill levels, (d) systematically returns pairs of state and pixel observation, (e) is an order of magnitude larger, and (f) includes tasks with hidden goals. Accompanying our dataset, we propose three benchmarks to evaluate representation learning methods for pretraining, and carry out experiments on several recently proposed methods. First, we find that pretrained representations do not help policy learning on DMC-VB, and we highlight a large representation gap between policies learned on pixel observations and on states. Second, we demonstrate when expert data is limited, policy learning can benefit from representations pretrained on (a) suboptimal data, and (b) tasks with stochastic hidden goals. Our dataset and benchmark code to train and evaluate agents are available at: https://github.com/google-deepmind/dmc_vision_benchmark.